КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Решение.2
|
|
|
|
Решение.1
| ai | pi | кодовая комбинация | ni | pini | H(ai) |
| a1 | 0,22 | 11 | 2 | 0,44 | 0,4806 |
| a2 | 0,20 | 101 | 3 | 0,6 | 0,4643 |
| a3 | 0,16 | 100 | 3 | 0,48 | 0,4230 |
| a4 | 0,16 | 01 | 2 | 0,32 | 0,4230 |
| a5 | 0,10 | 001 | 3 | 0,30 | 0,3322 |
| a6 | 0,10 | 0001 | 4 | 0,40 | 0,3322 |
| a7 | 0,04 | 00001 | 5 | 0,20 | 0,1857 |
| a8 | 0,02 | 00000 | 5 | 0,10 | 0,1129 |
По формуле(9.2)
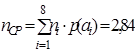 ,
,
по формуле (9.1)
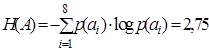 ,
,
тогда по формуле (9.7)
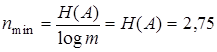
и по формуле (9.8)
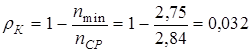 .
.
| ai | pi | кодовая комбинация | ni | pini | H(ai) |
| a1 | 0,22 | 11 | 2 | 0,44 | 0,4806 |
| a2 | 0,20 | 10 | 2 | 0,40 | 0,4643 |
| a3 | 0,16 | 011 | 3 | 0,48 | 0,4230 |
| a4 | 0,16 | 010 | 3 | 0,48 | 0,4230 |
| a5 | 0,10 | 001 | 3 | 0,30 | 0,3322 |
| a6 | 0,10 | 0001 | 4 | 0,40 | 0,3322 |
| a7 | 0,04 | 00001 | 5 | 0,20 | 0,1857 |
| a8 | 0,02 | 00000 | 5 | 0,10 | 0,1129 |
По формуле(9.2)
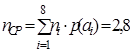 ,
,
по формуле (9.1)
,
тогда по формуле (9.7)
и по формуле (9.8)
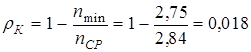 ,
,
т.е. второй вариант решения ближе к оптимальному, поскольку обеспечивает меньший коэффициент избыточности.
От данной неоднозначности построения эффективного кода свободен код Хаффмена. Для двоичного кода методика Хаффмена сводится к следующему. Символы алфавита источника выписываются в основной столбец таблицы в порядке убывания вероятностей. Далее два последних символа объединяются в один вспомогательный с вероятностью, равной сумме вероятностей объединяемых символов. Вероятности символов, не участвовавших в объединении, и полученная суммарная вероятность снова располагаются в порядке убывания в дополнительном столбце таблицы, после чего два последних символа вновь объединяются. Процесс повторяется до тех пор, пока не буде получен единственный вспомогательный символ с вероятностью, равной 1. Для составления кодовых комбинаций, соответствующих символам, необходимо проследить пути переходов по строкам и столбцам таблицы.
Для наглядного представления этого процесса удобнее всего построить граф, называемый кодовым деревом. Процедура построения кодового дерева выглядит следующим образом. Из вершины, соответствующей последнему единственному вспомогательному символу с вероятностью, равной 1, направляются две ветви, причем ветви с большей вероятностью присваивается кодовый символ 1, а с меньшей - 0. Такое последовательное ветвление из вершин, соответствующих вспомогательным символам, продолжается до получения вершин, соответствующих основным исходным символам.
Пример 9.3. Закодировать двоичным кодом Хаффмена ансамбль из примера 9.2. Решение представлено на рис. 9.1.
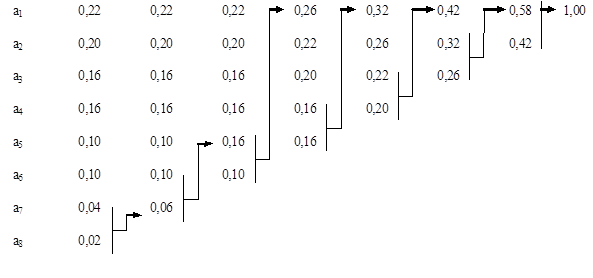
|
| Рис. 9.1. Алгоритм Хаффмена |
Кодовое дерево для этого примера изображено на рис. 9.2

|
| Рис. 9.2. Кодовое дерево |
Составленная в соответствии с кодовым деревом таблица кодовых комбинаций представлена ниже.
| ai | кодовая комбинация | ni |
| a1 | 01 | 2 |
| a2 | 00 | 2 |
| a3 | 111 | 3 |
| a4 | 110 | 3 |
| a5 | 100 | 3 |
| a6 | 1011 | 4 |
| a7 | 10101 | 5 |
| a8 | 10100 | 5 |
Таким образом, получены те же параметры в смысле избыточности, что и в примере 9.2, решение 2 для кода Шеннона - Фано, хотя кодовые комбинации по составу другие.
Из рассмотрения методов построения эффективных кодов следует, что эффект уменьшения избыточности достигается за счет различия в числе разрядов в кодовых комбинациях, т.е. эти эффективные коды являются неравномерными, а это приводит к дополнительным трудностям при декодировании. Как вариант, можно для различения кодовых комбинаций ставить специальный разделительный символ, но при этом снижается эффект, т.к. средняя длина кодовой комбинации увеличивается на один разряд.
Более целесообразно обеспечить однозначное декодирование без введения дополнительных разрядов. Для этого эффективный код необходимо строить так, чтобы ни одна комбинация кода не совпадала с началом другой более длинной кодовой комбинации. Коды, удовлетворяющие этому условию, называются префиксными.
Наличие или отсутствие свойства префиксности отражается и на кодовом дереве. Если свойство префиксности отсутствует, то некоторые промежуточные вершины кодового дерева могут соответствовать кодовым комбинациям.
Префиксные коды иногда называют мгновенно декодируемыми, поскольку конец кодовой комбинации опознается сразу, как только мы достигаем конечного символа кодовой комбинации при чтении кодовой последовательности. В этом состоит преимущество префиксных кодов перед другими однозначно декодируемыми неравномерными кодами, для которых конец каждой кодовой комбинации может быть найден лишь после анализа одной или нескольких последующих комбинаций, а иногда и всей последовательности. Это приводит к тому, что декодирование осуществляется с запаздыванием по отношению к приему последовательности.
Очевидно, что практическое применение могут иметь только префиксные коды. Коды Шеннона - Фано и Хаффмена являются префиксными.
Контрольные вопросы к лабораторной работе №9 [1. с. 241-258]
9-1. Что называется сигнально-кодовой конструкцией?
9-2. Что называется энтропией источника сообщений?
9-3. Когда энтропия источника максимальна?
9-4. Когда энтропия источника минимальна?
9-5. В чем состоит суть эффективного кодирования по методу Шеннона - Фано?
9-6. Как строится эффективный код по методу Шеннона - Фано?
9-7. В чем состоит недостаток эффективного кодирования по методу Шеннона – Фано?
9-8. Как строится эффективный код по методу Хаффмена?
9-9. Какие эффективные коды называются префиксными?
9-10. Почему при укрупнении алфавита общая избыточность не меняется?
9-11. Перечислите основные методы сжатия информации без потерь.
9-12. В чем состоит суть метода кодирования повторов?
9-13. Чем статические вероятностные методы сжатия отличаются от динамических?
9-14. Чем протокол сжатия MNP7 отличается от протокола MNP5?
9-15. Что означает свойство предшествования таблицы фраз в алгоритме LZW?
9-16. Какие параметры алгоритма LZW согласовываются между взаимодействующими пользователями?
9-17. С какой целью алгоритм LZW осуществляет мониторинг входного и выходного потоков данных?
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 482; Нарушение авторских прав?; Мы поможем в написании вашей работы!