КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Кодирование информации
|
|
|
|
Основы классификации информации
Классификация – особый вид логической операции, заключающейся в распределении элементов рассматриваемого множества по подмножествам (делении на классы) в соответствии с определённым признаком (группой признаков). Совокупность правил на основе взаимосвязанных признаков, в соответствии с которыми производится упорядоченное расположение классифицируемых элементов, составляет систему классификации.
Любая классификация основана на делении исходного множества на подмножества по каким-либо признакам. Множество или подмножество, объединяющее часть объектов классификации по одному или нескольким признакам, носит название классификационной группировки. Признаком классификации называется реквизит (свойство объекта, характеристика, значение), позволяющий установить сходство или различие с другими объектами классификации. Синонимом признака классификации является основание деления.
Классификатор – систематизированный свод наименований и кодов классификационных группировок (более подробному раскрытию понятия «классификатор» посвящён один из последующих подразделов настоящего пособия).
Системы классификации характеризуются гибкостью, ёмкостью и степенью заполненности.
Гибкостью системы классификации называют свойство системы классификации допускать включение новых классификационных группировок без разрушения существующей структуры классификатора.
Ёмкостью системы классификации называют наибольшее возможное количество группировок в данной системе классификации.
Степень заполненности (коэффициент заполненности) системы клас-сификации определяется отношением фактического количества используемых классификационных группировок к ёмкости.
Логическим продолжением классификации является кластеризация, которую можно рассматривать как автоматическую классификацию. Главное отличие кластеризации состоит в том, что перечень классификационных группировок и их характеристики не задаются чётко, а определяются автоматически в процессе обработки.
К системам классификации предъявляются следующие требования:
- полнота охвата объектов рассматриваемой области;
- однозначность реквизитов;
- возможность включения новых объектов.
На основе различных методов применения классификационных признаков строятся иерархическая, фасетная и дескрипторная системы классификации.
3.2.1. Иерархическая система классификации
Под иерархией понимается расположение элементов множества или частей целого в порядке подчинённости от высшего уровня к низшему. В иерархической системе классификации устанавливается такое отношение соподчинения между классификационными признаками, при котором каждое множество высшего порядка содержит непересекающиеся между собой подмножества низшего порядка.
Иерархическая система классификации строится путём последовательного деления исходного множества элементов, составляющего нулевой уровень, на классы (подмножества первого уровня), каждый из которых может делиться на подклассы (подмножества второго уровня), подклассы – на группы (подмножества третьего уровня), группы – на подгруппы (подмножества четвёртого уровня) и т.д.
Таким образом, осуществляется последовательный переход от общих признаков, характерных для всех элементов множества, к детализированным, характерным только для подмножеств более низшего уровня. Выбору классификационных признаков следует уделить особое внимание. Важно не только определить сами признаки, но и установить порядок их использования.
В качестве примера можно рассмотреть иерархическую систему классификации объектов административно-территориального деления Российской Федерации, иллюстрируемую рисунком 3.1. Уровни классификации здесь обозначены пунктирными линиями с цифрами. Конечно, на рисунке представлена далеко не вся Россия. Большинство группировок на уровнях 1, 3, 4 вообще опущено, что показано штриховыми линиями, символизирующими отброшенные ветви. Кроме того, на рисунке не показано дальнейшее деление на подмножества группировок на уровнях 2–4, также обозначенных штриховыми линиями.
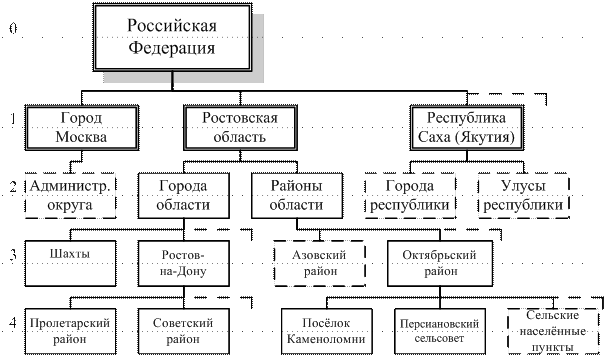
Рис. 3.1. Пример иерархической системы классификации объектов
административно-территориального деления Российской Федерации
В рассматриваемом примере всё множество объектов административно-территориального деления Российской Федерации подразделяется на группы согласно территориальному делению. Эти группы располагаются по уровням классификации в соответствии с административной подчинённостью, причём в каждый уровень включаются объекты, непосредственно подчинённые объектам предыдущего уровня.
Так, первый уровень классификации образуется по признаку «наименование субъекта Российской Федерации» и включает в себя все объекты федерального подчинения: республики, края, области, города федерального значения, автономную область и округа, входящие в состав Российской Федерации.
Для последующей группировки в каждом новом классе необходимо задать свои классификационные признаки и их значения. Таким образом, выбор классификационных признаков будет зависеть от семантического содержания того класса, для которого необходима группировка на последующем уровне иерархии. Так, для рассматриваемого примера в разных ветвях, исходящих из первого уровня классификации, уже на втором уровне используются различные не зависимые друг от друга признаки: наименование административного округа Москвы; тип объекта областного подчинения; тип объекта республиканского подчинения.
Глубина классификации (количество уровней, соответствующее числу признаков, выбранных в качестве основания деления) в рассматриваемом примере равна четырём. Причём не все ветви достигают этой глубины. Так, город областного подчинения Шахты находится на третьем уровне и не имеет дальнейшего административного деления, в отличие от «соседнего» Ростова-на-Дону. Однако можно было бы продолжить деление, например, по признаку отнесения к территориальному избирательному участку, или исторически сложившихся наименований территорий (Центр, ХБК, Артём и т.д., однако в этом случае установление чётких границ может оказаться затруднительным).
Основной особенностью иерархической системы классификации является жёсткость структуры, задаваемой порядком использования классификационных признаков. Эта особенность объясняет и достоинства, и недостатки иерархической системы классификации. Отметим, что далеко не для любого множества объектов можно осуществить выбор классификационных признаков и создать соответствующую структуру.
Достоинстваиерархической системы классификации:
- наглядность, простота и логичность построения;
- использование независимых классификационных признаков в различных ветвях иерархической структуры.
Недостаткииерархической системы классификации:
- сложность внесения в структуру изменений, связанная с перераспределением объектов по классификационным группировкам;
- невозможность группировать объекты по заранее не предусмотренным сочетаниям признаков.
3.2.2. Фасетная классификация
Фасетная система классификации, в отличие от иерархической, позволяет выбирать признаки классификации независимо как друг от друга (без соподчинения), так и от семантического содержания классифицируемого объекта. Признаки классификации называются фасетами (facet – рамка). Каждый фасет содержит совокупность однородных значений данного классификационного признака. Причём значения в фасете могут перечисляться произвольно, хотя предпочтительнее их упорядочение.
Общая схема построения фасетной системы классификации в виде таблицы отображена на рисунке 3.2. Названия столбцов соответствуют выделенным классификационным признакам (фасетам), обозначенным Ф1, Ф2, …, Ф i, …, Ф n. В каждой клетке таблицы хранится конкретное значение фасета. Количество значений (строк таблицы) для разных фасетов может отличаться. Например, если фасет «Год рождения» обычно характеризуется четырёхзначным числом (а это 10000 различных значений), то для фасета «Пол» можно ограничиться двумя значениями.
|
|
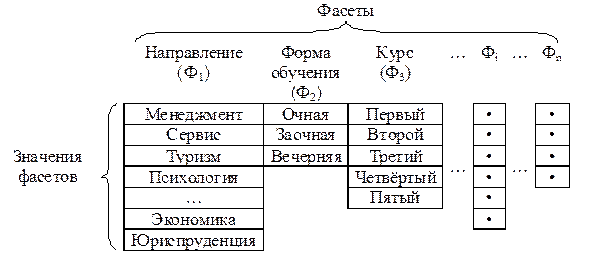
Рис. 3.2. Фасетная система классификации
Процедура классификации заключается в установлении для каждого объекта совокупности значений, соответствующих определённым фасетам. При этом могут быть использованы не все фасеты. Для каждого множества объекта задаётся конкретная группировка фасетов структурной формулой, в которой отражается порядок их следования. Например, если множество «Сведения» задано формулой («Направление», «Форма обучения», «Курс»), то подмножества могут задаваться следующими значениями: («Сервис», «Очная», «Первый»), («Юриспруденция», «Очная», «Второй»), («Сервис», «Заочная», «Четвёртый») и др.
При построении фасетной системы классификации необходимо, чтобы значения, используемые в различных фасетах, не повторялись. Фасетную систему легко можно модифицировать, добавляя новые фасеты, удаляя существующие или изменяя конкретные значения любого фасета.
Достоинствафасетной системы классификации:
- возможность создания большой ёмкости классификации, т.е. использования большого числа признаков классификации и их значений для создания группировок;
- возможность простой модификации всей системы классификации без изменения структуры существующих группировок.
Недостатком фасетной системы классификации является сложность её построения, так как необходимо учитывать всё многообразие классификационных признаков, а также низкая наглядность.
3.2.3. Дескрипторная система классификации
Для организации поиска информации, для ведения тезаурусов (словарей) эффективно используется дескрипторная (описательная) система классификации, язык которой приближается к естественному языку описания информационных объектов. Особенно широко она используется в библиотечной системе поиска.
Суть дескрипторного метода классификации заключается в следующем:
- отбирается совокупность ключевых слов или словосочетаний, описывающих определённую предметную область или совокупность однородных объектов. Причём среди ключевых слов могут находиться синонимы;
- выбранные ключевые слова и словосочетания подвергаются нормализации, то есть из совокупности синонимов выбирается один или несколько наиболее употребительных;
- создаётся словарь дескрипторов, т.е. словарь ключевых слов и словосочетаний, отобранных в результате процедуры нормализации.
Пример. В качестве предметной области выбирается учебная деятельность в высшем учебном заведении. Ключевыми могут быть выбраны следующие слова: студент, обучаемый, учащийся, преподаватель, учитель, педагог, лектор, ассистент, доцент, профессор, факультет, подразделение университета, аудитория, комната, лаборатория, лекция, практическое занятие, занятие и др. Среди указанных ключевых слов встречаются синонимы, например: студент, обучаемый, учащийся; преподаватель, учитель, педагог и т.д. После нормализации словарь дескрипторов будет состоять из следующих слов: студент, преподаватель, факультет, аудитория, занятие и т.д.
Между дескрипторами устанавливаются связи, которые позволяют расширить область поиска информации. Связи могут быть трёх видов:
- синонимические – указывают некоторую совокупность ключевых слов как синонимы (студент – учащийся – обучаемый);
- родовидовые – отражают включение некоторого класса объектов в более представительный класс (студент – группа – факультет);
- ассоциативные – соединяют дескрипторы, обладающие общими свойствами (студент – преподаватель – занятие – аудитория).
3.3.1. Системы кодирования
Под кодированием понимается процесс присвоения условных обозначений (кодов) признакам объектов. Кодирование используется для представления информации в ЭВМ при хранении, передаче и обработке. Вопросам кодирования, связанным с хранением и передачей информации (представление в ЭВМ, шифрование, сжатие, помехозащищённость), посвящены соответствующие разделы теории информации.
Здесь же рассматриваются основы кодирования, связанного с обработкой информации. Цель такого кодирования – обеспечение более удобной и эффективной обработки информации (путём представления информации в соответствующей форме). Система кодирования – совокупность правил кодового обозначения объектов.
Код строится на базе алфавита, который может состоять из букв, цифр и других символов. Наибольшее распространение при обработке информации с помощью ЭВМ получили цифровые коды. Код характеризуется длиной, структурой и степенью информативности. Длина – количество позиций (знаков, разрядов) в коде. Структура – порядок расположения в коде символов, используемых для обозначения классификационного признака. Степень информативности – отношение числа закодированных признаков к длине кода.
К системам кодирования предъявляются следующие требования:
- идентификация каждого объекта кодируемого множества;
- отображение необходимой информации об объектах;
- достаточная гибкость и резерв кодовых обозначений при минимальной длине кода;
- ориентация на автоматическую обработку информации, возможность обнаружения ошибок.
Существующие системы кодирования информации можно разбить на два основных вида (рис. 3.3):
- регистрационные системы кодирования, не требующие предварительной классификации объектов;
- классификационные системы кодирования, ориентированные на проведение предварительной классификации объектов.
Регистрационное кодирование, в свою очередь, может быть представлено порядковой и серийно-порядковой системами, а классификационное – последовательной и параллельной системами. Каждая из них имеет преимущества и недостатки, поэтому в зависимости от конкретных обстоятельств и целей необходимо выбирать наиболее рациональную систему.


Рис. 3.3. Классификация основных систем кодирования
Особо следует выделить комбинированные системы кодирования, представляющие собой сочетание нескольких различных систем кодирования. Они используются для кодирования больших номенклатур объектов, которые можно группировать по нескольким соподчинённым или независимым признакам. Комбинированные системы кодирования дают возможность получить более информативный код.
3.3.2. Порядковое кодирование
Порядковая система кодирования не требует предварительной классификации объектов и основана на наиболее простом методе. Его суть заключается в последовательной нумерации объектов натуральными числами. Таким образом, каждый объект идентифицируется регистрационным номером. Объекты при регистрации могут располагаться как случайно, так и в определённом порядке, например алфавитном (список студентов группы) или хронологическом (журнал регистрации событий).
Количество объектов номенклатуры N, которое может быть закодировано с помощью порядковой системы, зависит от количества символов А, составляющих алфавит кода, и длины кодового обозначения l (количества знаков в коде), что выражается формулой N = Аl. Например, с использованием алфавита из десяти цифр и трёхзначного кода можно закодировать 103, то есть 1000 объектов (от 000 до 999).
Достоинствами порядковой системы являются простота кодирования и минимальная длина кода. Долговечность порядкового кода практически всегда достигается за счёт незначительной избыточности, так как добавление только одного разряда увеличивает ёмкость кода в А раз.
Недостатком порядковой системы кодирования является отсутствие в коде информации о свойствах объектов (даже зная, что список группы составляется в лексикографическом порядке, мы не можем по номеру с полной уверенностью назвать начальную букву фамилии, так как все студенты могут оказаться Ивановыми).
3.3.3. Серийно-порядковое кодирование
Используемый в серийно-порядковой системе метод отличается от порядкового кодирования тем, что объекты предварительно разбиваются на подмножества, а порядковые номера – на серии. Элементы каждого подмножества регистрируются в пределах отведённой для него серии номеров. В каждой серии обычно предусматриваются резервные номера (на случай появления новых позиций).
По своей сути серийно-порядковая система является смешанной: классифицирующей и идентифицирующей. Обычно применяется в тех случаях, когда деление на подмножества осуществляется только по одному классификационному признаку, а их количество невелико.
Пример. Для нумерации аудиторий некоего вуза, размещённого в четырёх небольших близкорасположенных зданиях, имеющих по 20 используемых для занятий помещений, можно использовать четыре серии по 25 номеров (00–24; 25–49; 50–74; 75–99). При этом в каждой серии остаётся резерв из пяти номеров (на случай перепланировки), а длина кода аудитории остаётся прежней – двузначной. Другой пример: использование «нечётной» серии для нумерации почтовых адресов домов, расположенных на левой, а «чётной» – на правой стороне улицы.
Серийно-порядковой системе присущи в основном те же достоинства и недостатки, что и порядковому кодированию. Но здесь коды, помимо идентификации объекта, несут некоторую дополнительную информацию, хотя её восприятие человеком может быть затруднено. Резервирование, с одной стороны, является достоинством, обеспечивающим некоторую долговечность кода, а с другой – серийно-порядковая система может стать непригодной из-за переполнения только одной серии, при этом резервы других серий ещё не будут исчерпаны. Поэтому серийно-порядковый код в сравнении с порядковым оказывается менее долговечным и более избыточным.
3.3.4. Последовательное кодирование
Последовательное кодирование, как и параллельное (рис. 3.3), требует проведения предварительной классификации кодируемых объектов. Классификационные системы кодирования называются также позиционными, так как для выражения каждого классификационного признака в структуре кода выделяется позиция (группа символов) из одного или нескольких разрядов.
Последовательное кодирование используется для иерархической классификационной структуры. Суть метода заключается в следующем: сначала записывается код старшей группировки 1-го уровня, затем код группировки 2-го уровня, а после код группировки 3-го уровня и т.д. В результате получается кодовая комбинация, каждый разряд которой содержит информацию о специфике выделенной группы на каждом уровне иерархической структуры. При этом значение характеристики объекта, выраженного каким-либо числом на определённой позиции, зависит от конкретного значения предыдущих разрядов кодовой комбинации (за исключением разрядов старшей группировки).
Пример. Проведём кодирование информации, классифицированной с помощью двухуровневой иерархической схемы (рис. 3.3). Количество позиций определяется глубиной классификации и равно двум. Присвоим на каждом уровне код «Л» для левых группировок (Регистрационные, Порядковая, Последовательная), «П» – для правых (Классификационные, Серийно-порядковая, Параллельная). Структура кода задаётся последовательностью «ХY», где «Х» – код группировки первого уровня, «Y» – второго. Теперь легко получить коды всех группировок второго уровня:
- ЛЛ – (Система кодирования) Регистрационная, Порядковая;
- ЛП – Регистрационная, Серийно-порядковая;
- ПЛ – Классификационная, Последовательная;
- ПП – Классификационная, Параллельная.
Следует обратить внимание на то, что символ «Л» в позиции «Х» имеет значение – «Регистрационные», а значение этого же символа, но расположенного в позиции «Y», уже зависит от предыдущего знака (ЛЛ – Порядковая, а ПЛ – Последовательная). То есть извлечение информации из кода (как и кодирование) осуществляется последовательно: сначала определяется значение признака, соответствующего первому уровню, а только потом – второму.
Последовательная система кодирования обладает теми же основными достоинствами и недостатками, что и иерархическая система классификации. Если же сравнивать с порядковой системой, то представление дополнительной информации достигается за счёт увеличения длины и избыточности кода.
3.3.5. Параллельное кодирование
Параллельное кодирование используется для фасетной системы классификации. Суть метода заключается в следующем: все фасеты кодируются независимо друг от друга (параллельно, одновременно); для каждого фасета в структуре кода определяется позиция из одного или нескольких разрядов.
Параллельная система кодирования обладает основными достоинствами и недостатками, присущими фасетной системе классификации. Однако параллельный код оказывается ещё более избыточным, чем последовательный, так как на практике многие сочетания признаков могут вообще не существовать и, следовательно, ёмкость кода будет использоваться не полностью.
Пример. Проведём кодирование сведений, представленных на рисунке 3.2. фасетами «Направление», «Форма обучения», «Курс». Количество кодовых группировок определяется количеством фасетов и равно трём. Для кодирования фасетов следует проанализировать их номенклатуру и выбрать наиболее рациональный метод, учитывая предъявляемые к системам кодирования требования.
Для использования в процессе автоматизированной обработки и обмена информацией на всех установленных государством образовательных уровнях в Российской Федерации с охватом как государственных, так и негосударственных образовательных учреждений предназначен Общероссийский классификатор специальностей по образованию (ОКСО). Но в учебных целях рассматриваемого примера (удобство восприятия, понимание) можно закодировать каждое направление первыми тремя буквами его наименования. Для кодирования фасета «Форма обучения» будем использовать первую букву значения, а для номера курса – соответствующую десятичную цифру.
Структуру полученного кода можно выразить записью «ННН Ф К», где ННН – присвоенный нами код направления; Ф – код формы обучения, К – курс. В отличие от последовательного кодирования, порядок (очерёдность) кодирования фасетов значения не имеет. Поэтому по обозначению «Сер О 2» мы независимо от других позиций можем определить и направление – Сервис; и форму обучения – очная; и курс – второй.
3.3.6. Штриховое кодирование
В настоящее время для автоматической идентификации признаков объектов широко используется штриховое кодирование, основанное на оптическом считывании информации различными техническими устройствами – сканерами штрих-кода. В качестве примера можно привести такие широко известные штриховые коды, как:
- UРC (Universal Product Code) – универсальный товарный код, разработанный в США;
- EAN (European Article Number) – европейский товарный код, созданный на базе UРC;
Опуская особенности преобразования штрихового года в цифровой, рассмотрим подробнее структуру широко распространённого в России товарного кода EAN-13. Он состоит из тринадцати цифр, которые можно разделить на четыре части:
- первые три цифры обозначают код страны-производителя (точнее – код регионального представителя глобальной организации по стандартизации). Но некоторые коды имеют специальное значение. Так, использование кодов, начинающихся с цифры 2, разрешено для внутренних целей любого предприятия, но запрещено за его пределами (применяется, например, для весового товара при розничной торговле);
- следующие четыре цифры (в России начиная с 2000 г. – шесть) – код предприятия-производителя для данной страны;
- следующие пять цифр (в России – три) – код продукта, устанавливаемый предприятием-производителем;
- последняя цифра является контрольной.
Таким образом, в основе кода EAN-13 лежит последовательная система кодирования, так как определение значения второй части кода возможно только после определения первой, а третьей – после второй. При этом в первой части кода используется серийно-порядковое кодирование, так как, например, России соответствует серия 460–469.
|
|
|
|
|
Дата добавления: 2014-12-07; Просмотров: 3109; Нарушение авторских прав?; Мы поможем в написании вашей работы!