КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Тема № 2. Інформаційні системи і їх класифікація
|
|
|
|
План:
1. Поняття Інформаційних систем(ІС).
2. Класифікація ІС.
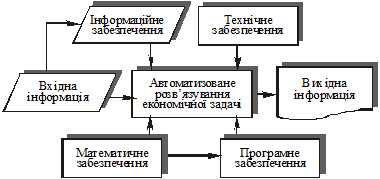
Схема автоматизованого розв’язування економічних задач
Математичні моделі й алгоритми можуть бути подані.у вигляді, який передбачає етап програмування, і у формі, придатній для прямого використання при розв’язуванні задачі. Вихідна інформація може бути подана в різних варіантах.
У системах обробки інформації головними її компонентами є дані та обчислення. Більшість інформаційних систем управління інформаційними ресурсами в організаціях містять і багато інших компонентів, таких як вимоги, запити, трігери і звіти. І всі вони, зокрема, містять великі описи свого власного змісту в тій чи іншій формі. Ці описи необхідні для інтерпретації і для коректного використання наданої інформації (коли в системі немає повного опису, то передбачається, що користувачі отримують його з іншого джерела).
В інформаційних системах першого покоління, які в зарубіжній літературі відомі під назвою Data Processing System — DPS («Системи обробки даних», синоніми — «Електронна обробка даних», «Системи електронної обробки даних»), а у вітчизняній — «Автоматизовані системи управління (АСУ) — позадачний підхід» — для кожної задачі окремо готувалися дані і створювалася математична модель. Такий підхід зумовлював інформаційну надмірність (одні й ті самі дані могли використовуватись для розв’язування різних задач) і математичну надмірність (моделі розв’язування різних задач мали загальні блоки). Типовими прикладами систем обробки даних є системи керування запасами, виписування рахунків, нарахування зарплати.
Системи обробки даних були вузько прикладними й орієнтованими на автоматизацію робіт з паперами за рахунок комп’ютеризації великих масивів і потоків даних на операційному рівні. Розпізнавальною ознакою цих систем є ефективна обробка запитів, використання інтегрованих файлів для пов’язування між собою задач і генерування зведених звітів для керівництва. Оскільки кожна система була націлена на конкретне застосування, то опис її функцій (як правило, у формі надрукованих керівництв (інструкцій) до процедур або у вигляді стандартів) подавався мінімально і призначався для спеціаліста в цій предметній галузі. Крім того, передбачалось, що користувачі мають належний досвід як у прикладній галузі, так і в роботі із системами, які обслуговують відповідне застосування.
Інформаційні системи другого покоління відомі під назвою Management Information System — MIS («управлінські (адміністративні) інформаційні системи» або «інформаційні системи в менеджменті»), у нашій літературі використовується термін «АСУ — концепція баз даних». Основною функцією таких систем є забезпечення керівництва інформацією. Типову управлінську інформаційну систему характеризує структурований потік інформації, інтеграція задач обробки даних, генерування запитів і звітів.
В управлінських інформаційних системах (УІС) вже були визнані переваги колективного користування даними, а також відзначено, що в одній організації багато прикладних програм використовують одні й ті самі робочі дані і відбувається дублювання робіт у процесі збирання, зберігання і пошуку цих даних. Зі збільшенням кількості прикладних програм, що обслуговують всі рівні управління та обробляють одні й ті самі робочі дані, зростав обсяг дублювання, що ставало гальмом на шляху комп’ютеризації управління. Більш того, це дублювання часто було неефективним, оскільки призводило до несумісності прикладних програм. Виходом із цієї ситуації стала концепція створення єдиної централізовано керованої бази даних, яка за допомогою спеціального програмного продукту — СУБД обслуговує всі прикладні програми організацій.
Основною проблемою створення великих розподілених баз даних є складність опису даних, що має на меті об’єктивного, незалежного від окремих прикладних програм, спростити колективне використання даних різними прикладними програмами. Для опису даних широко застосовуються моделі та словники даних. Семантика даних, тобто вивчення їх змісту незалежно від окремих прикладних програм, стала самостійною галуззю досліджень.
Системи підтримки прийняття рішень — СППР (Decision Support Systems — DSS) — це інформаційні системи третього покоління. СППР — інтерактивна комп’ютерна система, яка призначена для підтримки різних видів діяльності в разі прийняття рішень зі слабоструктурованих або неструктурованих проблем. Iнтерес до СППР як перспективної галузі використання обчислювальної техніки та інструментарію підвищення ефективності праці у сфері управління економікою постійно зростає. У багатьох країнах розробка та реалізація СППР перетворилася на сферу бізнесу, що швидко розвивається.
СППР мають не тільки загальне інформаційне забезпечення, а й загальне математичне забезпечення — бази моделей, тобто реалізована ідея розподілу обчислень подібно до того, як розподіл даних став вирішальним фактором у звичайних інформаційних системах.
Зі зростанням кількості прикладних програм для надання персоналізованої оперативної підтримки, а також кількості інформаційних систем збільшувався обсяг обчислювального дублювання, що стало значною мірою гальмівним фактором: для індивідуальної оперативної підтримки необхідно виконувати досить багато персоналізованих версій однієї й тієї самої прикладної програми, причому кожна версія підлягає багаторазовій модифікації протягом періоду її експлуатації з тією метою, щоб вона відповідним чином реагувала на зміни в можливостях, знаннях, позиції і побажаннях користувача. Більш того, дубльована версія часто виявлялась менш ефективною, призводила до взаємної несумісності програм і меншої продуктивності обчислень. Виходом із такої ситуації стала концепція утворення єдиної централізовано керованої бази моделей.
Нехай на підприємстві діють дві прикладні задачі:
Задача А — обчислення повного обсягу збуту продукції за n періодів часу (наприклад, місяць);
Задача В — обчислення середнього обсягу збуту продукції за n періодів часу.
Математичні моделі цих задач і інші характеристики наведені на рис. 2.3. В інформаційних системах першого покоління для розв’язування цих задач необхідно створити дві незалежні системи зі своїми файлами даних і своїми обчислювальними функціями:
для задачі А — файл даних М 1 і обчислювальна функція ПОВН, що охоплює операції підсумовування і присвоєння (знак рівності “=”);
для задачі В — файл даних М 1 і величина п; обчислювальні функції: ПОВН, ДІЛ (ділення), ПРИС (присвоєння).
| Індекс задачі | Назва задачі | Математична модель | Дані | Обчислювальні функції |
| А | Обчислення повного обсягу збуту V продукції за n періодів часу | 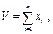 де xi — обсяг збуту за період i
де xi — обсяг збуту за період i
| 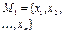
| 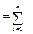 — ПОВН — ПОВН
|
| В | Обчислення середнього обсягу S збуту продукції за n періодів часу | 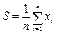 або
або
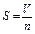
| 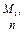
| ПОВН
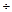 — ДІЛ
= — ПРИС — ДІЛ
= — ПРИС
|
|
|
|
|
|
Дата добавления: 2014-12-07; Просмотров: 412; Нарушение авторских прав?; Мы поможем в написании вашей работы!