КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Представление связного списка
|
|
|
|
Активные структуры данных
Примеры этой и предыдущих лекций часто используют понятие списка или последовательности, характеризуемой в каждый момент " позицией курсора ", указывающей точку доступа, вставки и удаления. Такой вид структуры данных широко применим и заслуживает детального рассмотрения.
Для понимания достоинств такого подхода полезно начать с общего рассмотрения и оценки его ограничений.
Обсуждение будет основываться на примере списков. Хотя результаты не зависят от выбора реализации, необходимо иметь некоторое представление, позволяющее описывать алгоритмы и иллюстрировать проблемы. Будем использовать популярный выбор - односвязный линейный список. Наша общецелевая библиотека должна иметь классы со списковыми структурами и среди них класс LINKED_LIST.
Вот некоторые сведения о связных списках, применимые ко всем стилям интерфейса, обсуждаемым далее, - с курсором и без курсора.
Связный список является полезным представлением последовательной структуры с эффективно реализуемыми операциями вставки и удаления элементов. Элементы хранятся в отдельных ячейках, называемых звеньями (linkables). Каждое звено содержит значение и ссылку на следующий элемент списка:
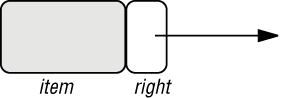
Рис. 5.3. Элемент списка - звено (linkable)
Соответствующий класс должен быть универсальным (синонимы: родовым, параметризованным), так как структура должна быть применима к спискам с элементами любого типа. Значение звена, заданное компонентом item, имеет тип G - родовой параметр. Оно может быть непосредственно встроено, если фактический родовой параметр развернутого типа, например, для списка целых, или быть ссылкой в общем случае. Другой атрибут right типа LINKABLE[G] всегда представляет ссылку.
Сам список задается отдельной ячейкой - заголовком, содержащим ссылку first_element на первое звено, и, возможно, дополнительной информацией, например count - текущим числом элементов списка. Вот как выглядит связный список символов:
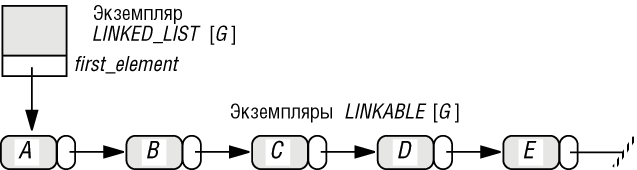
Рис. 5.4. Связный список (linked list)
Это представление позволяет быстро выполнять операции вставки и удаления, если есть ссылка, указывающая на звено слева от цели операции. Достаточно выполнить несколько манипуляций над ссылками, как показано на следующем рисунке:
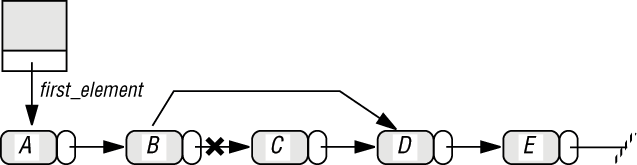
Рис. 5.5. Удаление в связном списке
Но, с другой стороны, списковое представление не очень подходит для таких операций как поиск элемента по его значению или позиции, поскольку они требуют прохода по списку. Представление массивом, по контрасту, хорошо подходит для получения нужного элемента по индексу (позиции), но не подходит для операций вставки и удаления. Существует много других представлений, некоторые из которых объединяют преимущества обоих миров. Связный список остается одной из наиболее употребительных реализаций, предлагая эффективную технику для приложений, где большинство операций связано со вставкой и удалением и почти не требуется случайный доступ.
Технический момент: рисунок не фиксирует в деталях атрибуты LINKED_LIST кроме first_element, показывая просто затененную область. Хотя можно обойтись first_element, классы ниже включают атрибут count. Этот запрос может быть функцией, но неэффективно при каждом проходе по списку подсчитывать число элементов. Конечно, при использовании атрибута каждая операция вставки и удаления должна обновлять его значение. Здесь применим Принцип Унифицированного Доступа - можно менять реализацию, не нанося вреда клиентам класса.
Пассивные классы
Ясно, что нам нужны два класса: LINKED_LIST для списка (более точно, заголовка списка), LINKABLE для элементов списка - звеньев. Оба они являются универсальными.
Понятие LINKABLE является основой реализации, но не столь важно для большинства клиентов. Следует позаботиться об интерфейсе, обеспечивающем модули клиентов нужными примитивами, но не следует беспокоить их такими деталями реализации как представление элементов в звене списка. Атрибуты, соответствующие рисунку, появятся как:
indexing
description: "Звенья, используемые в связном списке"
note: "Частичная версия, только атрибуты"
class
LINKABLE1 [G]
feature {LINKED_LIST}
item: G
-- Значение звена
right: LINKABLE [G]
-- Правый сосед
end
Тип right можно было бы задавать как like Current, но предпочтительнее на этом этапе сохранить больше свободы в переопределении, поскольку пока непонятно, что может потребовать изменений у потомков LINKABLE.
Для получения настоящего класса следует добавить подпрограммы. Что допустимо для клиентов при работе со звеньями? Они могут изменять поля item и right. Можно также ожидать, что многие из клиентов захотят при создании звена инициализировать его значение, что требует процедуры создания. Вот подходящая версия класса:
indexing
description: "Звенья, используемые в связном списке"
class LINKABLE [G] creation
make
feature {LINKED_LIST}
item: G
-- Значение звена
right: LINKABLE [G]
-- Правый сосед
make (initial: G) is
-- Инициализация item значением initial
do put (initial) end
put (new: G) is
-- Замена значения на new
do item:= new end
put_right (other: LINKABLE [G]) is
-- Поместить other справа от текущего звена
do right:= other end
end
Для краткости в классе опущены очевидные постусловия процедуры (такие как ensure item = initial для make). Предусловий здесь нет.
Ну, вот и все о LINKABLE. Теперь рассмотрим сам связный список, внутренне доступный через заголовок. Рассмотрим его экспортируемые компоненты: запрос на получение числа элементов (count), пуст ли список (empty), значение элемента по индексу i(item), вставка нового элемента в определенную позицию (put), изменение значения i -го элемента (replace), поиск элемента с заданным значением (occurrence). Нам также понадобится запрос, возвращающий ссылку на первый элемент (void, если список пуст), который не должен экспортироваться.
Вот набросок первой версии. Некоторые тела подпрограмм опущены.
indexing
description: "Односвязный список"
note: "Первая версия, пассивная"
class
LINKED_LIST1 [G]
feature -- Access
count: G
empty: BOOLEAN is
-- Пуст ли список?
do
Result:= (count = 0)
ensure
empty_if_no_element: Result = (count = 0)
end
item (i: INTEGER): G is
-- Значение i-го элемента
require
1 <= i; i <= count
local
elem: LINKABLE [G]; j: INTEGER
do
from
j:= 1; elem:= first_element
invariant j <= i; elem /= Void variant i - j until
j = i
loop
j:= j + 1; elem:= elem.right
end
Result:= elem.item
end
occurrence (v: G): INTEGER is
-- Позиция первого элемента со значением v (0, если нет)
do... end
feature -- Element change
put (v: G; i: INTEGER) is
-- Вставка нового элемента со значением v,
-- так что он становится i-м элементом
require
1 <= i; i <= count + 1
local
previous, new: LINKABLE [G]; j: INTEGER
do
-- Создание нового элемента
create new.make (v)
if i = 1 then
-- Вставка в голову списка
new.put (first_element); first_element:= new
else
from
j:= 1; previous:= first_element
invariant
j >= 1; j <= i - 1; previous /= Void
-- previous - это j-й элемент списка
variant
i - j - 1
until j = i - 1 loop
j:= j + 1; previous:= previous.right
end
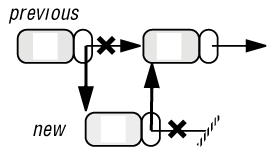
Вставить после previous
previous.put_right (new)
new.put_right (previous.right)
end
count:= count + 1
ensure
one_more: count = old count + 1
not_empty: not empty
inserted: item (i) = v
-- For 1 <= j < i,
-- элемент с индексом j не изменил свое значение
-- For i < j <= count,
-- элемент с индексом j изменил свое значение
-- на то, которое элемент с индексом j - 1
-- имел перед вызовом
end
replace (i: INTEGER; v: G) is
-- Заменить на v значение i-го элемента
require
1 <= i; i <= count
do
...
ensure
replaced: item (i) = v
end
feature -- Removal
prune (i: INTEGER) is
-- Удалить i-й элемент
require
1 <= i; i <= count
do
...
ensure
one_less: count = old count - 1
end
... Другие компоненты...
feature {LINKED_LIST} -- Implementation
first_element: LINKABLE [G]
invariant
empty_definition: empty = (count = 0)
empty_iff_no_first_element: empty = (first_element = Void)
end
Это хорошая идея попытаться самому закончить определение occurrence, replace и prune в этой первой версии. Убедитесь при этом, что поддерживается истинность инварианта.
Инкапсуляция и утверждения
До рассмотрения лучших версий несколько комментариев к первой попытке.
Класс LINKED_LIST1 показывает, что даже на совершенно простых структурах манипуляции со ссылками - это некий вид трюков, особенно в сочетании с циклами. Использование утверждений помогает в достижении корректности (смотри процедуру put и инвариант), но явная трудность операций этого типа является сильным аргументом в пользу их инкапсуляции раз и навсегда в повторно используемых модулях, как рекомендуется ОО-подходом.
Обратите внимание на применение Принципа Унифицированного Доступа; хотя count это атрибут и empty это функция, клиентам нет необходимости знать такие детали. Они защищены от возможных последующих изменений в реализации.
Утверждения для put полны, но из-за ограничений языка утверждений они не полностью формальны. Аналогично подробные предусловия следует добавить в другие подпрограммы.
Критика интерфейса класса
Удобно ли использование LINKED_LIST1? Давайте оценим наш проект.
Беспокоящий аспект - существенная избыточность: item и put содержат почти идентичные циклы. Похожий код следует добавить в процедуры, оставленные читателю (occurrence, replace, remove). Все же не представляется возможным вынести за скобки общую часть. Не слишком многообещающее начало.
Это внутренняя проблема реализации, - отсутствие повторно используемого внутреннего кода. Но это указывает на более серьезный изъян - плохо спроектированный интерфейс класса.
Рассмотрим процедуру occurrence. Она возвращает индекс элемента, найденного в списке, или 0 в случае его отсутствия. Недостаток ее в том, что она дает только первое вхождение. Что, если клиент захочет получить последующие вхождения? Но есть и более серьезная трудность. Клиент, выполнивший поиск, может захотеть изменить значение найденного элемента или удалить его. Но любая из этих операций требует повторного прохода по списку!
Проектируя компонент библиотеки общецелевого использования, нельзя допустить такую неэффективность. Любые потери производительности в повторно используемых решениях неприемлемы, в противном случае разработчики просто откажутся платить, обрекая на провал идею повторного использования.
|
|
|
|
|
Дата добавления: 2014-12-07; Просмотров: 639; Нарушение авторских прав?; Мы поможем в написании вашей работы!