КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Введение 1 страница. # include <string.h>
|
|
|
|
2.
1.
# include <string.h>
unsigned int strlen(char * str)
Функция strlen() возращает длину строки str. Завершающий нулевой символ не учитывается.
Пример использования функции:
char s[255]; cin.getline(s,255);
cout<< “Длина строки равна ”<<strlen(s);
#include <string.h>
int strcmp(const char *str1, const char* str2);
Функция strcmp() сравнивает в лексикографическом порядке две строки и возвращает целое значение, зависящее от результата сравнения следующим образом: значение меньше нуля, если str1<str2; ноль, если str1=str2; больше нуля, если str1>str2. Приведем пример использования этой функции – фрагмент программы, проверяющий упорядочены ли два слова по алфавиту:
char s1[20], s2[20];
cin>>s1>>s2;
int k=strcmp(s1,s2);
if (k<0) cout<< “Слова упорядочены по алфавиту”;
else if (k==0) cout<< “Слова одинаковы”;
else cout<< “Слова не упорядочены по алфавиту”;
#include <string.h>
char * strcpy (char *str1, const char* str2);
Функция strcpy() копирует содержимое строки str2 в строку str1 и возвращает значение указателя str1. Если заданные символьные массивы перекрываются, поведение функции не определено. Приведем пример использования этой функции – ввести в клавиатуры слово и скопировать его в новую строку.
char str1[20],str2[20];
cin>>str1;
strcpy(str2,str1);
cout<<str1<<" "<<str2;
Функции для работы с файлами описаны в заголовочном файле stdio.h. ([8] стр. 131). В языке не предусмотрены никакие предопределенные структуры фалов: все файлы рассматриваются как последовательности, потоки байтов. Для файла определен маркер (указатель чтения/записи), который определят текущую позицию, к которой осуществляется доступ. В программе возможно открывать потоки ввода-вывода и связывать их либо с файлами на диске либо с физическими устройствами (например, принтером), записывать в них или считывать из них информацию. Доступ к потоку осуществляется с помощью типа FILE, определенного в файле stdio.h следующим образом:
FILE * идентификатор;
Описанный указатель можно связывать с конкретным файлом в момент открытия данного файл. Это осуществляется с помощью функции
FILE * fopen(const char *fname, const char * mode);
Функция fopen() открывает файл, имя которого задает параметр fname и возвращает поток, связанный с этим файлом. Строка fname должна представлять собой имя файла, которое разрешено определенными в данной операционной системе правилами. Если указанный файл не удается открыть, функция возвращает нулевой указатель. Типы операций, которые разрешено выполнять с файлом, определяются параметром mode. Существует таблица значений параметра mode. Наиболее часто используемые значения:
“r” – открывает текстовый файл для чтения;
“w” – создает текстовый файл для записи;
“a” – открывает текстовый файл для записи в конец файла;
“r+” – открывает текстовый фал для чтения и записи;
“w+” – создает текстовый файл для чтения и записи;
“a+” – открывает текстовый файл для чтения и записи в конец файла.
Приведем фрагмент программы, иллюстрирующий корректный способ открытия файла.
FILE *fp=fopen("1.txt","r");
if (fp==NULL) {cout<<"Не удается открыть файл "; exit(1);}
else {….}
В данном примере происходит попытка открыть файл с именем “1.txt” в текущем каталоге для чтения. Если такого файла не существует, на экран выдается соответствующее сообщение и с помощью функции exit(), описанной в заголовочном файле stdlib.h, происходит завершение программы. При открытии файла для записи с параметром “w” также рекомендуется делать проверку, так как диск может быть защищен от записи или заполнен.
По окончании работы с файлом он должен быть закрыт с помощью функции
int fclose (FILE * stream);
После обращения к функции fclose() указатель stream больше не связан с конкретным файлом. При успешном выполнении функции возвращается ноль, в противном случае возвращается значение EOF. Попытка закрыть уже закрытый файл расценивается как ошибка.
Опишем назначений основных функций ввода и ввода данных.
Функция int fgetc(FILE * stream); считывает из входного потока streаm следующий символ, соответствующий текущей позиции, при достижении конца файла возвращает значение EOF.
Функция char * fgets (char *str, int num, FILE * stream); считывает из входного потока stream не более num-1 и помещает их в массив, адресуемый указателем str. Символы читаются пока не будет прочитан символ новой строки или конец файла либо пока не будет достигнут заданный предел. По завершении чтения символов сразу за последним прочитанным символом размещается нулевой символ. Символ новой строки сохраняется и остается частью строки. При успешном выполнении функции возвращается значение str, при неуспешном – нулевой указатель.
Функция int fscanf (FILE * stream, const char * format, …); читает информацию из потока stream. Управляющая строка, задаваемая параметром format состоит из символов трех категорий: спецификаторы формата, пробельные символы и символы, отличные от пробельных. Спецификаторы формата – им предшествует знак процента – сообщают, какого типа данные будут прочитаны. Например спецификатор %d прочитает целое значение, а спецификатор %с прочитает символ. Пробельные символы заставляют функцию пропустить один или несколько пробельных символов во входном потоке. Не пробельный символ заставляет функцию прочитать и отбросить соответствующий символ из входного потока. Символ *, стоящий после знака % и перед кодом формата прочитает данные заданного типа, но запретит их присваивание. В качестве неопределенных параметров функции могут использовать параметры зависимости от управляющей строки. Например, функция fcsanf (fp, “%d%d”, &a, &b) прочитает очередные два целых числа из файлового потока fp в переменные a, b, а функция fcsanf (fp, “%d%*d”, &a) считает два целый числа, но в переменной а сохранит только первое из них. Функция возвращает количество аргументов, которым действительно присвоены значения.
Функция int fputc(int ch, FILE * stream); записывает символ ch в заданный поток stream в текущую позицию файла, а затем передвигает индикатор позиции файла. Возвращает значение записанного символа, а в случае ошибки значение EOF.
Функция int fputs(const char *str, FILE* stream); записывает в заданный поток stream содержимое строки, адресуемой указателем str. При этом завершающий нулевой символ не записывается. При успешном выполнении возвращается неотрицательное значение, при неудачном – значение EOF.
Функция int fprintf (FILE * stream, const char *format, …); - записывает в файловый поток stream значения параметров из заданного списка параметров в соответствии со строкой форматирования format. Например, функция fprintf(fp, “%d”, a) запишет значение целой переменной a в файловый поток fp. Функция возвращает количество реально выведенных символов, а при возникновении ошибки- отрицательное значение.
Для проверки, достигнут ли конец файла используют функцию
int feof(FILE *stream);
Если индикатор позиции файла, связанного с потоком stream, расположен в конце файла возвращается ненулевое значение, в противном случае - нуль.
Для изменения индикатора позиции файла используют функцию
int fseek (FILE* stream, long offset, int origin);
Функция устанавливает индикатор позиции файла, связанного с потоком stream, в соответствии со значением смещения offset (количество байтов) и исходного положения origin. Параметр origin может принимать одно их следующих значений: 0 - начало файла, 1 – текущая позиция, 2 – конец файла. При успешном выполнении функция возвращает нулевое значение, при возникновении сбоя – ненулевое. Функция очищает признак конца файла. Вообще говоря функцию fseek() следует использовать только при работе с двоичными файлами. При использовании же с текстовыми файлами параметр origin должен иметь значение 0, а параметр offset – значение, полученное в результате вызова функции
long ftell (FILE* stream);
которая возвращает текущее значение индикатора позиции файла.
Приведем фрагмент программы, считывающей из файлового потока fp каждый третий символ
char a;
while ((a=fgetc(fp))!=EOF && fseek(fp,2,1)==0)
cout<<a<<" ";
Если необходимо считать каждое третье число из файла (предполагается, что числа разделены пробелами) программа примет следующий вид:
int a;
while (fscanf(fp, "%d%*d%*d ", &a)!=EOF && fseek(fp,ftell(fp),0)==0)
cout<<a<<" ";
Каждому студенту рекомендуется выполнить хотя бы одно из упражнений 1-12 заданий 1-4.
Задание 1. Определение и вызов функций
1. Определить функцию, проверяющую, является ли целое число совершенным. Совершенное число равно сумме всех своих делителей, включая единицу и не включая себя. Например 6=1+2+3 – совершенное число, 8¹1+2+2+2 - несовершенное. Выяснить, сколько совершенных чисел находится в диапазоне [n..m] (n<m), вывести их на экран.
2. Определить функции, переводящую число в двоичную систему счисления и проверяющую, является ли двоичная запись числа симметричной последовательностью нулей и единиц, начинающейся единицей. Напечатать все числа, не превосходящие n, двоичная запись которых есть симметричная последовательность.
3. Определить функцию, посчитывающую количество инверсий в последовательности цифр натурального числа, то есть количество таких пар соседних цифр, в которых большая находится слева от меньшей. Из массива целых чисел, генерируемом случайным образом, вывести на экран сначала все числа, в записи которых нет инверсий, затем числа, в записи которых 1 инверсия и т.д. до чисел, имеющих максимальное число инверсий в данном массиве. Например, элементы массива {3564, 123, 24, 87, 981, 9871, 54} должны быть выведены следующим образом: 0 инверсий: 123, 24; 1 инверсия: 3564, 87,54; 2 инверсии: 981; 3 инверсии: 9871.
4. Определить функцию, проверяющую, является ли заданная дробь несократимой. (Дробь задается двумя натуральными числами – числителем и знаменателем). Найти все несократимые дроби, заключенные между 0 и 1, знаменатели которых не превышают заданное число n.
5. Определить функцию, проверяющую является ли число простым. Распечатать четверки простых чисел, не превосходящих n, принадлежащих одному десятку. Например, для числа 112 надо напечатать четверки 2 3 5 7; 11 13 17 19; 101 103 107 109.
6. Определить функцию, возвращающую сумму простых делителей натурального числа. Найти все пары “дружественных” чисел в диапазоне [ n 1, n 2]. Два натуральных числа называются “дружественными”, если одно из них равно сумме простых делителей другого.
7. Определить функцию, проверяющую, является ли данное число простым. Составить программу для проверки гипотезы Гольдбаха о том, что каждое четное число, большее 2, можно представить суммой двух простых чисел. (Для любого четного k, не превосходящего n, выдать либо пару простых слагаемых, либо сообщение, что такого разложения нет).
8. Определить функцию, проверяющую, является ли данное число простым, и функцию, вычисляющую количество нулей в двоичной записи натурального числа. (Считается, что первая цифра двоичного числа всегда 1). Среди простых чисел, не превосходящих n, найти первое такое, в двоичной записи которого максимальное количество нулей.
9. Определить функцию, проверяющую, является ли данное число простым, и функцию, подсчитывающую количество единиц в двоичной записи натурального числа. Найти все пары простых чисел, не превосходящих n, сумма единиц в двоичной записи которых совпадает. Например, такой парой является пара 3 (11) и 5 (101).
10. Определить функцию для нахождения наименьшего общего кратного (НОК) и наибольшего общего делителя (НОД) двух натуральных чисел. Определить НОК и НОД для n введенных натуральных чисел.
11. Определить функцию, проверяющую, является ли данное число простым, и функцию, вычисляющую количество единиц в двоичной записи натурального числа. (Считается, что первая цифра двоичного числа всегда 1). Среди простых чисел, не превосходящих n, найти такие, в двоичной записи которых количество единиц не превосходит m.
12. Определить функцию, которая преобразует строку цифр (от двоичных до шестнадцатеричных) в эквивалентное десятичное число, и функцию, которая преобразует целое десятичное число в эквивалентную строку цифр (от двоичных до шестнадцатеричных). Вычислить сумму двух введенных двоичных строк и вывести результат сложения на экран в десятичном и двоичном виде.
Задание 2. Рекурсивные функции
1. Записать алгоритм Евклида вычисления наибольшего общего делителя (НОД) как рекурсивную функцию. Алгоритм основан на том факте, что если a = qb + r, где 0< r < b, то HOD (a, b)= HOD (b, r). В процессе вычислений выводить на экран текущие выражение a = qb + r в численном виде, то есть 37=2*17+3, 17=5*3+2 и т.д. В конце вывести НОD.
2. Записать алгоритм, проверящий является ли заданное число простым как рекурсивную функцию. Вывести на экран все простые числа, не превосходящих n.
3. Записать алгоритм разложения произвольного числа на простые множители как рекурсивную функцию с выводом на экран сомножителей.
4. Записать алгоритм нахождения канторового разложения произвольного числа а – вектора 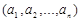 в виде рекурсивной функции. Канторовым разложением положительного числа а называется запись вида:
в виде рекурсивной функции. Канторовым разложением положительного числа а называется запись вида: 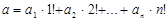 ,
, 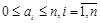 .
.
5. Определить рекурсивную функцию, которая возвращает факториал целого неотрицательного числа. Написать программу, вычисляющую 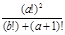 по заданным a и b.
по заданным a и b.
6. Определить рекурсивную функцию, вычисляющую число сочетаний 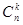 , используя соотношение
, используя соотношение 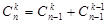 .
.
7. Определить рекурсивную функцию, которая возвращает n -ое число Фибоначчи. Числа Фибоначчи вычисляются следующим образом: 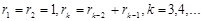 .
.
8. Определить рекурсивную функцию, которая вычисляет сумму цифр натурального числа.
9. Определить рекурсивную функцию, выводящую на экран цифры целого положительного числа.
10. Определить рекурсивную функцию, которая находит корень уравнения f(x)=0 на заданном интервале [a,b] c заданной точностью e. Корень ищется методом деления отрезка пополам по следующему алгоритму. Первоначально предполагается, что f(a)f(b)<0.
1) вычисляются f(а), f(b);
2) вычисляется c=(a+b)/2 и f(c);
3) если f(a)f(c)>0, то а=c, в противном случае b=c;
4) если b-a>e, то перейти к шагу 2, иначе любой из концов отрезка может быть использован в качестве корня уравнения.
11. Определить рекурсивную функцию, выводящее в экран двоичное представление заданного десятичного числа.
12. Определить рекурсивную функцию, возвращающую максимальное из n чисел.
Задание 3. Использование библиотечных функций string.h
Пример. Вывести слова введенной строки, начинающиеся с гласной буквы, на экран столбиком, без разделительных знаков (пробел, табуляция, точка, запятая и т.п.).
Для выделения слов из строки будем использовать библиотечную функцию
char * strtok(char *str1, const char *str2),
которая ищет в строке str1 лексемы, выделенные символами из строки str2 и возвращает указатель на выделенную лексему, причем при отсутствии лексемы возвращается NULL (нулевой указатель, то есть указатель, отличный от указателя на любой объект). Чтобы разделить некоторую строку на лексемы, при первом вызове функции strtok() параметр str1 должен указывать на начало этой строки. При последующих вызовах функции в качестве параметра str1 нужно использовать нулевой указатель.
Для проверки принадлежности первой буквы слова к гласным буквам будем использовать функцию
char * strchr (const char * str, int ch),
которая возвращает указатель на первое вхождение младшего байта параметра ch в строке str. Если совпадение не обнаружено, возвращается нулевой указатель.
# include <iostream.h>
# include <string.h>
# define dlin 80 // директива позволяет в программе вместо
//числа 80 использовать идентификатор dlin
void main()
{
cout<<”Enter string ”;
char stroka[dlin];
cin.getline(stroka,dlin);
char *slova[dlin/2]; //массив указателей для хранения
//слов строки
char *razd=".,:;!? ";// указатель на строку,
//состоящую из разделительный символов
char *glas="aeoiuy"; // указатель на строку,
//состоящую из гласных
int k=0; //определили индекс для массива slova
slova[k]=strtok(stroka,razd); // выделили первое слово
while (slova[k])// пока выделенная из строки
//лексема не равна NULL
{
if (strchr(glas,*slova[k])!=NULL)
cout<<slova[k]<<"\n";//проверили, является ли первая
// буква слова s1[k] гласной
slova[++k]=strtok(NULL,razd); // выделили очередное
//слово.
}
}
В данном решении задачи для хранения слов мы использовали массив, взяв за его размерность максимально возможную – размерность исходной строки, деленную пополам, то есть предполагая, что все слова строки состоят из одной буквы и разделены одним разделителем. Однако, в данной задачи не предполагается дальнейшая обработка выделенных из строки слов, поэтому нет необходимости сохранять их в массиве. Поэтому целесообразнее определять массив указателей char * s1[dlin/2], а определить лишь один указатель char *s1, который и использовать для обработки очередного выделенного слова.
1. Дана текстовая строка. Вывести на печать все ее слова в таком порядке: все однобуквенные, потом все двухбуквенные, потом все трехбуквенные и т.д. до слова максимальной длины, используя функции strtok, strlen.
2. Даны текстовая строка и слово (например, ba). Напечатать все слова, входящие в эту текстовую строку, начинающиеся с букв заданного слова (например, bak, barber, baab, baalam), используя функции strtok, strlen, strnicmp.
3. Дана текстовая строка. Сформировать строку, состоящую из последних букв слов заданной текстовой строки, используя функции strtok, strlen и вывести ее на экран. Например, если задана строка adcd ef ghi jklmn, то на экран должно быть выведено слово dfin.
4. Даны текстовая строка и слово (например, ab). Напечатать все слова, входящие в эту текстовую строку, заканчивающиеся на буквы заданного слова (например, abcdab, ab, kab), используя функции strtok, strlen, strcmp.
5. Даны текстовая строка и слово. Определить, какие слова из этой текстовой строки предшествуют заданному слову в лексикографическом порядке, используя функции strtok, strcmp.
6. Дан набор слов и произвольная текстовая строка. Выбрать из текстовой строки все слова, входящие в данный набор и вывести их на печать, используя функции strtok, strcmp.
7. Дана текстовая строка. Определить, упорядочены ли ее слова по алфавиту, указать первое слово, нарушающее порядок, используя функции strtok, strcmp.
8. Из заданной текстовой строки распечатать только те слова, которые начинаются и оканчиваются одной и тоже буквой, используя функции strtok, strlen.
9. Из заданной строки, распечатать все слова без повторений, используя функции strtok, strcmp.
10. Дана текстовая строка. Сформировать строку, состоящую из третьих букв каждого слова заданной текстовой строки, используя функции strtok, strlen, и вывести ее на экран. Например, если задана строка adcd ef ghi jklmno, то на экран должно быть выведено слово сil.
11. Дана текстовая строка. Распечатать строку, состоящую из слов заданной, расположенных в лексикографическом порядке, используя функции strtok, strlen, strnicmp.
12. Дана текстовая строка. Распечатать из нее все слова, имеющие наименьшую и наибольшую длину, используя функции strtok, strlen.
Задание 4. Использование библиотечных функций stdio.h
Пример. Дан текстовый файл, строки которого содержат не более m (m <=20) символов. Считать строки и записать их в файл result.txt в порядке считывания, причем каждая строка должна быть «перевернута».
#include <iostream.h>
#include <stdio.h>
void main ()
{
char filename[255];
cout<<"Введите имя файла ";
cin>>filename;
FILE *fp=fopen(filename,"r"); //открываем файл для чтения
if (fp!=NULL) // Если файл успешно открыт
{
FILE * fp1=fopen("result.txt","w");//Открываем для файл
// для записи
char s[20];// определяем массив для хранения
//считанной строки
while(fgets(s,21,fp)) //Цикл считывания строк
{
int l=strlen(s);
if (s[l-1]!='\n') fputc(s[l-1],fp1);
/*цикл записи символов строки в обратном порядке*/
for (int j=l-2; j>=0; j--) fputc(s[j],fp1); //
fputc('\n',fp1);//запись символа новой строки
}
fclose(fp);
fclose (fp1);
cout<<"Файл записан";
}
else cout<<"Не существует такого файла!";
}
Заметим, что запись считанной строки s в файл происходит, начиная с символа с индексом strlen(s)‑2, так как последний символ строки это ноль-символ, а предпоследний - символ новой строки, который записывается в строку при ее чтении из файла функций fgets(). Однако исключение может составлять последняя строка файла, после которой в исходном файле может не стоять символа новой строки. Именно для последней строки в цикле введена проверка условия.
1. Дан текстовый фал, содержащий целые числа, разделенные пробелами. Определить является ли последовательность чисел, находящихся в файле, упорядоченной. В новый файл вывести сообщение о том, являются ли последовательность чисел в данном файле упорядоченной по убыванию или по возрастанию либо не упорядоченной, а также - среднее арифметическое всех чисел.
2. Дан файл, содержащий несколько строк. В новый файл переписать строки данного, вставляя символ ‘!’ после каждой строки, содержащей не более n символов. Если строка заканчивается знаком препинания заменить его на символ ‘!’.
3. Дан файл, содержащий несколько строк. Найти максимальную длину строки и вывести в новый файл все строки, имеющую такую длину.
4. Дан файл, содержащий несколько строк (причем строки не содержат пробелов). В новый файл записать строки данного, вставляя пробелы так, чтобы каждая строка имела длину 80 символов (пробелы должны быть расставлены равномерно).
5. Дан текстовый файл. Осуществить посимвольную чередующуюся печать файла в прямом и обратном направлении в новый файл. Например, если в файле было слово ЛУНА, то в результирующем файле должно быть слов ЛАУННУАЛ.
6. В исходном файле находится текст программы на языке С++. Создать файл, в который переписать содержимое исходного файла без однострочных комментариев.
7. Подсчитать количество пустых строк в текстовом файле. Вывести номера этих строк в новый файл.
8. Дан текстовый файл. Переписать его содержимое в новый файл, разбив строки таким образом, чтобы каждая строка либо оканчивалась точкой, либо содержала 40 литер, если среди них нет точки.
9. В текстовом файле подсчитать количество строк, которые начинаются и оканчиваются одной и той же буквой, вывести эти строки их количество в новый файл.
10. Дано два текстовых файла. Сравнить их содержимое и в новый файл записать либо номер первой строки, в которой они различаются, либо сообщение о том, что файлы идентичны.
11. Если в текущем каталоге имеется файл, tabl_umn.txt, то вывести на экран его содержимое. Если нет, то создать такой файл и записать туда таблицу умножения для чисел от 2 до 9.
12. Дан текстовый файл. Переписать его содержимое в новый файл, разбив строки таким образом, чтобы каждая строка имела n символов. Если в последней строке меньше, чем n символов, дополнить ее символами ‘!’.
ГЛАВА 2. Динамические структуры данных
Большинство задач, рассмотренных в предыдущих главах, требовали работы со статическими переменными, - переменными, которые создаются в момент определения и уничтожаются автоматически при выходе программы из области их действия. Статические переменные и структуры данных характеризуются фиксированным размером выделенной для них памяти. Например, если описан массив int a[100] под него будет выдела sizeof(int)*100 байт, хотя в самой программе может реально использоваться лишь несколько первых элементов массива. Существуют задачи, которые исключают использование структур данных фиксированного размера и требуют введения динамических структур данных, способных увеличиваться в размерах в процессе работы программы. Если до начала работы с данными невозможно определить, сколько памяти потребуется для их хранения, то память должна выделять по мере необходимости отельными блоками, связанными друг с другом указателями. Динамическая структура может занимать несмежные участки оперативной памяти.
Динамические структуры широко применяют и для более эффективной работы с данными, размер которых известен, особенно для решения задач сортировки, поскольку упорядочивание динамических структур не требует перестановки элементов, а сводится к изменению указателей на эти элементы. Например, если в процессе выполнения программы требуется многократно упорядочивать большой массив данных, имеет смысл организовать его в виде динамической структуры.
Для реализации элементов динамической структуры данных в С++ используют тип данных, называемый структура (struct). (В многих языках программирования такой тип данных называют записью).
Структура - это поименованная совокупность поименованных элементов, имеющих в общем случае разный тип, и расположенных в памяти компьютера последовательно. Каждая структура включает в себя один или несколько объектов, называемых элементами структуры. Элементы структуры также называют полями структуры.
Формат описания структуры:
struct [имя типа]
{
тип1 имя_элемента1;
тип2 имя_элемента 2;
…
тип n имя_элемента n;
}[список определителей];
Элементы структуры могут иметь любой тип, кроме типа этой же структуры.
Например, опишем структуру с тремя полями:
struct student
{
char fio[30];
int group;
int mark;
} s1, *s2;
Такое определение вводит новый тип данных student, который может быть использован при определении программных объектов. Например, создадим структурированный объект и массив структурированных объектов.
student s3,s4[10];
Структурированные объекты можно определять сразу после описания структуры - в списке определений. В нашем случае в списке определений определен объект s1, и указатель на структурированный объект s2.
Для обращения к объектам, входящим в качестве элементов в конкретную структуру, обычно используют уточненные имена, то есть конструкцию вида
имя_структуры.имя_элемента_структуры
Например,
s1.group= 121;
s1.mark=5;
Если определен указатель на структуру, то для обращения к элементам структуры можно использовать операцию выбора компонентов структурного объекта ->
имя указателя->имя элемента структуры
Например,
student *st;
st->group= 222; //это равносильно (*st).group=222;
Инициализировать конкретную структуру можно только при описании перечислением ее элементов в скобках {} в порядке их описания, например
student s4= {“Fedorov”, 122, 4};
Для переменных одного и того же структурного типа определена операция присваивания, то есть поэлементное копирование, например s3=s1;
Часто в качестве поля структуры используют объединения. Объединение представляет собой частный случай структуры, все поля которой располагаются по одному и тому же адресу. Формат описания такой же, но используются ключевое слово union. Размер объединения равен наибольшему размеру из его полей.
Основное достоинство объединения – возможность разных трактовок одного и того же содержимого участка памяти.
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 591; Нарушение авторских прав?; Мы поможем в написании вашей работы!