КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Системы распределенных вычислений (grid)
|
|
|
|
Вычислительные кластеры
Кластеры используются в вычислительных целях, в частности в научных исследованиях. Для вычислительных кластеров существенными показателями являются высокая производительность процессора в операциях над числами с плавающей точкой (flops) и низкая латентность объединяющей сети, и менее существенными — скорость операций ввода-вывода, которая в большей степени важна для баз данных и web-сервисов. Специально выделяют высокопроизводительные кластеры (Обозначаются англ. аббревиатурой HPC Cluster — High-performance computing cluster).
Такие системы не принято считать кластерами, но их принципы в значительной степени сходны с кластерной технологией. Их также называют grid-системами. Главное отличие — низкая доступность каждого узла, то есть невозможность гарантировать его работу в заданный момент времени (узлы подключаются и отключаются в процессе работы), поэтому задача должна быть разбита на ряд независимых друг от друга процессов. Такая система, в отличие от кластеров, не похожа на единый компьютер, а служит упрощённым средством распределения вычислений. Нестабильность конфигурации, в таком случае, компенсируется больши́м числом узлов. Грид с точки зрения сетевой организации представляет собой согласованную, открытую и стандартизованную среду, которая обеспечивает гибкое, безопасное, скоординированное разделение вычислительных ресурсов и ресурсов хранения[1] информации, которые являются частью этой среды, в рамках одной виртуальной организации.
Наборы инструкций процессора: RISC (restricted (reduced) instruction set computer) — архитектура процессора, в которой быстродействие увеличивается за счёт упрощения инструкций, чтобы их декодирование было более простым, а время выполнения — короче. Упрощение инструкций облегчает повышение тактовой частоты. CISC (сomplex instruction set computing) — архитектура процессора, в которой реализуется расширенный набор инструкций. Данная концепция проектирования процессоров характеризуется следующим набором свойств: 1. нефиксированное значение длины команды; 2.арифметические действия кодируются в одной команде; 3.небольшое число регистров, каждый из которых выполняет строго определённую функцию.
2. Классификации архитектур вычислительных систем. Классификации Флинна, Ванга-Бриггса, Фенга, Шора, Хендлера, Хокни, Скилликорна.
Классификация по Флинну Общая классификация архитектур ЭВМ по признакам наличия параллелизма в потоках команд и данных. Все разнообразие архитектур ЭВМ в этой таксономии сводится к четырем классам:
SISD, Single Instruction stream over a Single Data stream Вычислительная система с одиночным потоком команд и одиночным потоком данных; К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа, например, PDP-11 или VAX 11/780. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Не имеет значения тот факт, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка - как машина CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными попадают в этот класс.
SIMD, Single Instruction, Multiple Data - Вычислительная система с одиночным потоком команд и множественным потоком данных; принцип компьютерных вычислений, позволяющий обеспечить параллелизм на уровне данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1. SM-SIMD (shared memory SIMD) -К этому под-классу относятся векторные процессоры. В научных вычислениях большая часть операций связана с применением какой-то одной операции к большому массиву данных. Причем эту операцию можно осуществлять над каждым элементом данных независимо друг от друга, то есть присутствовал параллелизм данных, для использования которого и были созданы векторные процессоры. DM-SIMD (distributed memory SIMD) К этому под-классу относятся так называемые «матричные процессоры». Они представляют собой массив процессоров, которые контролируются одним управляющим процессором, выполняя по его команде одну операцию над своей собственной порцией данных, хранящихся в локальной памяти. Так как обмена данными между процессорами нет, не требуется никакой синхронизации, что позволяет достигать огромных скоростей вычислений и с легкостью расширять систему, просто увеличивая количество процессоров. Для понимания работы матричного процессора достаточно представить себе утренние телевизионные уроки по аэробике, где актер в студии задает движения, а миллионы телезрителей повторяют их в такт одновременно по всей стране. SIMT – Single Instruction Multiple Thread (GPU).
MISD, Multiple Instruction Single Data - Вычислительная система со множественным потоком команд и одиночным потоком данных; К классу MISD ряд исследователей относит конвейерные ЭВМ, однако это не нашло окончательного признания, поэтому можно считать, что реальных систем — представителей данного класса не существует.
MIMD, Multiple Instruction Multiple Data - Вычислительная система со множественным потоком команд и множественным потоком данных. Класс MIMD включает в себя многопроцессорные системы, где процессоры обрабатывают множественные потоки данных. Сюда принято относить традиционные мультипроцессорные машины, многоядерные и многопоточные процессоры, а также компьютерные кластеры. Также делится на: SM-MIMD (shared memory MIMD) В эту группу попадают многопроцессорные машины с общей памятью, многоядерные процессоры с общей памятью; и DM-MIMD (distributed memory MIMD) В этот под-класс попадают многопроцессорные MIMD-машины с распределенной памятью.У каждого процессора имеется своя собственная локальная память, которая не видна другим процессорам. Каждый процессор в такой системе выполняет свою задачу со своим набором данных в своей локальной памяти.
Не официально(!):
SPMD (Single Program Multiple Data) — описывает систему, где на всех процессорах MIMD-машины выполняется только одна единственная программа, и на каждом процессоре она обрабатывает разные блоки данных.
MPMD (Multiple Programs Multiple Data) — описывает систему, а) где на одном процессоре MIMD-машины работает мастер-программа, а на других подчиненная программа, работой которой руководит мастер-программа (принцип master/slave или master/worker); б) где на разных узлах MIMD-машины работают разные программы, которые по-разному обрабатывают один и тот же массив данных (принцип coupled analysis), большей частью они работают независимо друг от друга, но время от времени обмениваются данными для перехода к следующему шагу.
Дополнения Ванга и Бриггса Класс SISD разбивается на два подкласса: архитектуры с единственным функциональным устройством (PDP-11); архитектуры, имеющие в своем составе несколько функциональных устройств (CDC 6600, CRAY-1, FPS AP-120B, CDC Cyber 205, FACOM VP-200). В классе SIMD также вводится два подкласса: архитектуры с пословно-последовательной обработкой информации (ILLIAC IV, PEPE, BSP); архитектуры с разрядно-последовательной обработкой (STARAN, ICL DAP). В классе MIMD: вычислительные системы со слабой связью между процессорами, к которым они относят все системы с распределенной памятью (Cosmic Cube); вычислительные системы с сильной связью (системы с общей памятью), куда попадают такие МВС, как C.mmp, BBN Butterfly, CRAY Y-MP, Denelcor HEP.
Классификация Фенга В 1972 году Фенг (T. Feng) предложил классифицировать вычислительные системы (ВС) на основе двух простых характеристик. Первая характеристика – число n бит в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Вторая характеристика – число m слов, обрабатываемых одновременно. Немного изменив терминологию, функционирование ВС можно представить как параллельную обработку n битовых слоёв, на каждом из которых независимо преобразуются m бит. Тогда каждую вычислительную систему можно описать парой чисел (n, m). Произведение P = n \cdot m определяет интегральную характеристику потенциала параллельности архитектуры, которую Фенг назвал максимальной степенью параллелизма ВС.
Классификация Шора Классификация Дж.Шора появившаяся в начале 70-х годов, интересна тем, что представляет собой попытку выделения типичных способов компоновки вычислительных систем на основе фиксированного числа базисных блоков: устройства управления, арифметико-логического устройства, памяти команд и памяти данных. Итак, согласно классификации Шора все компьютеры разбиваются на шесть классов, которые он так и называет: машина типа I, II и т.д. Машина I - это вычислительная система, которая содержит устройство управления, арифметико-логическое устройство, память команд и память данных с пословной выборкой. Если в машине I осуществлять выборку не по словам, а выборкой содержимого одного разряда из всех слов, то получим машину II. Слова в памяти данных по прежнему располагаются горизонтально, но доступ к ним осуществляется иначе. Если в машине I происходит последовательная обработка слов при параллельной обработке разрядов, то в машине II - последовательная обработка битовых слоев при параллельной обработке множества слов. Если объединить принципы построения машин I и II, то получим машину III. Эта машина имеет два арифметико-логических устройства - горизонтальное и вертикальное, и модифицированную память данных, которая обеспечивает доступ как к словам, так и к битовым слоям. Если в машине I увеличить число пар арифметико-логическое устройство <==> память данных (иногда эту пару называют процессорным элементом) то получим машину IV. Единственное устройство управления выдает команду за командой сразу всем процессорным элементам. Если ввести непосредственные линейные связи между соседними процессорными элементами машины IV, например в виде матричной конфигурации, то получим схему машины V. Любой процессорный элемент теперь может обращаться к данным как в своей памяти, так и в памяти непосредственных соседей.Заметим, что все машины с I-ой по V-ю придерживаются концепции разделения памяти данных и арифметико-логических устройств, предполагая наличие шины данных или какого-либо коммутирующего элемента между ними. Машина VI, названная матрицей с функциональной памятью (или памятью с встроенной логикой), представляет собой другой подход, предусматривающий распределение логики процессора по всему запоминающему устройству. Примерами могут служить как простые ассоциативные запоминающие устройства, так и сложные ассоциативные процессоры.
Классификация Хэндлера В основу классификации В.Хендлер закладывает явное описание возможностей параллельной и конвейерной обработки информации вычислительной системой. Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения программ:
уровень выполнения программы — опираясь на счетчик команд и некоторые другие регистры, устройство управления (УУ).
уровень битовой обработки — все элементарные логические схемы процессора (ЭЛС) разбиваются на группы, необходимые для выполнения операций над одним двоичным разрядом.
Подобная схема выделения уровней предполагает, что вычислительная система включает какое-то число процессоров каждый со своим устройством управления. Если на какое-то время не рассматривать возможность конвейеризации, то число устройств управления k, число арифметико-логических устройств d в каждом устройстве управления и число элементарных логических схем w в каждом АЛУ составят тройку для описания данной вычислительной системы C: (k, d, w) k — число УУ, d — число АЛУ в каждом УУ, w — число разрядов в слове, обрабатываемых в АЛУ параллельно.
Классификация Хокни Классификация машин MIMD -архитектуры:
Переключаемые — с общей памятью и с распределённой памятью. (В данный класс попадают машины, в которых возможна связь каждого процессора с каждым, реализуемая с помощью переключателей — машины с распределённой памятью. Если же память есть разделяемый ресурс, машина называется с общей памятью.)
Конвейерные (В класс конвейерных архитектур (по Хокни) попадают машины с одним конвейерным устройством обработки, работающим в режиме разделения времени для отдельных потоков.)
Сети — регулярные решётки, гиперкубы, иерархические структуры, изменяющие конфигурацию. (Имеют распределенную память. Дальнейшую классификацию он проводил в соответствии с топологией сети.)
Классификация Скилликорна (1989) была очередным расширением классификации Флинна. Архитектура любого компьютера в классификации Скилликорна рассматривается в виде комбинации четырёх абстрактных компонентов: процессоров команд (Instruction Processor — интерпретатор команд, может отсутствовать в системе), процессоров данных (Data Processor — преобразователь данных), иерархии памяти (Instruction Memory, Data Memory — память программ и данных), переключателей (связывающих процессоры и память). Переключатели бывают четырёх типов — «1-1» (связывают пару устройств), «n-n» (связывает каждое устройство из одного множества устройств с соответствующим ему устройством из другого множества, то есть фиксирует попарную связь), «n x n» (связь любого устройства одного множества с любым устройством другого множества). Классификация Скилликорна основывается на следующих восьми характеристиках:
· Количество процессоров команд IP
· Число ЗУ команд IM
· Тип переключателя между IP и IM
· Количество процессоров данных DP
· Число ЗУ данных DM
· Тип переключателя между DP и DM
· Тип переключателя между IP и DP
· Тип переключателя между DP и DP
3. Архитектуры SMP, MPP, PVP. Кластерная архитектура.
Symmetric multiprocessing (SMP)
Преимущества:
Простота и универсальность программирования. Нет ограничений на модель программирования
 Простота эксплуатации и тех. обслуживания
Простота эксплуатации и тех. обслуживания 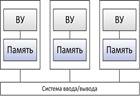
Невысокая цена комплектующих
Недостатки:
Плохая масштабируемость
Massive parallel processing (MPP)
Преимущества:
Хорошая масштабируемость
Большинство рекордов производительности устанавливаются на машинах MPP-архитектуры
(I don't see how this is a +?)
Недостатки:
Отсутствие общей памяти снижает скорость межпроцессорного обмена
Каждый процессор может использовать только ограниченный объем банка памяти
Высокая цена программного обеспечения
Параллельные векторные системы (PVP)
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Как правило, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций.
Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP).
Эффективное программирование подразумевает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
Кластерные системы Набор рабочих станций (или даже ПК) общего назначения, используется в качестве дешевого варианта MPP-архитектуры.
Для связи узлов используется одна из стандартных сетевых технологий на базе шинной архитектуры или коммутатора (к примеру Ethernet)
При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о гетерогенных (неоднородных) кластерах.
Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций. (несколько функций у узлов кластера)
Программирование, как правило, в рамках модели передачи сообщений (к примеру MPI)
Дешевизна подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач.
4. Особенности организации памяти в современных персональных компьютерах и МВС. Различные виды памяти. Различные архитектуры МВС по типу доступа к памяти. (UMA. NUMA, NORMA и т.д.) Классификация архитектур. Общая схема.
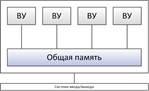
ВС соднородным доступом – UMA (Uniform memory access)
Наиболее распространена
Процессоры обращаются к памяти: единообразно, содинаковойскоростью
Реализации: единая память на шине; коммутатор между процессорами и памятью.
С единой шиной: Простота
Низкая пропускная способность (1 процессор блокирует шину, при N>2
производительность обмена быстро падает)
C коммуникатором: Одновременный доступ разных процессоров к разным банкам памяти. Блокирует каждый отдельный банк на время доступа к нему.
ИТОГО Ограничения модели: Не очень хорошо масштабируется. Типичный размер: 4-8 процессоров, реже 32-64. Низкая отказоустойчивость, отказ одного устройства приводит к отказу всей ВС.
Модель NUMA ВС с неоднородным доступом – NUMA (Non-Uniform memory access)
• Сохраняется единая адресация
• Каждый процессор имеет локальную память
• доступ к локальной памяти быстрее
• Может дополняться глобальной памятью
• локальная память служит кэшем для глобальной
• обращение к глобальной памяти происходит реже
за счёт кэша 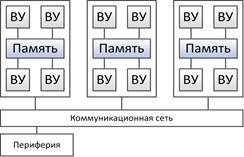
В рамках концепции есть несколько подходов:
• COMA (Cache-Only Memory Architecture)
• CC-NUMA (Cache Coherent Non-UniformMemory Architecture)
• NCC-NUMA (Non-Cache Coherent Non-
Uniform Memory Architecture
|
|
|
|
|
Дата добавления: 2015-01-03; Просмотров: 979; Нарушение авторских прав?; Мы поможем в написании вашей работы!