КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Временные параметры периодических задач
|
|
|
|
Назовите Достоинства и недостатки способа выполнения задач в бесконечном цикле. Clock-driven scheduling
Преимущества Clock-driven scheduling:
· простота;
· справедливость (как в очереди покупателей во время перестройки – каждому по килограмму).
Недостатки Clock-driven scheduling:
· если частые переключения (квант – 4мс, а время переключения равно 1мс), то происходит уменьшение производительности;
· Если редкие переключения (квант – 100мс, а время переключения равно 1мс), то происходит увеличение времени ответа на запрос.
Циклическое планирование (cyclic / clock-driven / off-line sheduling) – применяется к набору периодических задач и некоторых спорадических.
Самый простой алгоритм планирования и часто используемый.
Каждому процессу предоставляется квант времени процессора. Когда квант заканчивается процесс переводится планировщиком в конец очереди. При блокировке процесс выпадает из очереди.
Спорадические задачи планируются следующим образом: ищется НОК (наименьшее общее кратное) периодов всех составляющих этот набор задач, это значения является т.н. большим циклом планирования, через который последовательность этих задач повторяется. Если задач много, то необходимо распланировать цикл так, чтобы максимальное их число (в идеале ВСЕ) выполнялось.
Эту задачу можно решить жадными алгоритмами (упаковка рюкзака).
38. Что такое Slack Stealing?
Slack Stealing – воровство запасов времени. Нет никакой выгоды от того, что периодические задачи с жестким deadline будут завершены раньше deadline.
39. Классификация задач по периодичности.?
Периодические – реализуют действия, период которых заранее известен и строго определен.
Спорадические – которые имеют ограничения во времени между двумя входами (максимальная частота поступления) термин спорадическая задача может быть определен как задача, последующее поступление которой (запроса о выполнении) отделено некоторым минимальным временем ssn.
Возникают в произвольный момент времени, но для них известна наибольшая возможная частота возникновения и относительный крайний срок выполнения (deadline).
Апериодические задачи - Задачи, выполнение которых, не может ожидаться, так как определено возникновением некоторых внутренних или внешних факторов (например, задача, отвечающая на запрос от оператора). Эти задачи обычно характеризуются мягким крайним сроком.
· Период задания Т представляет собой интервал времени между поступлениями двух последовательных заданий одного типа.
· Частота заданий (измеряемая в Hz) 1/Т представляет собой величину, обратную периоду (в секундах). Например, задание с периодом 50 мс имеет частоту 20 Гц. Обычно окончание периода задания является жестким предельным сроком завершения задания, хотя некоторые задания могут иметь и более ранние предельные сроки.
· Время выполнения (вычисления) С представляет собой количество процессорного времени, требующегося для каждого задания определенного типа.
41. На каком американском космическом аппарате инверсия приоритета привела к многократной перезагрузке бортового компьютера?
Инверсия приоритета в Mars Pathfinder
При разработке ПО для бортового компьютера космического аппарата Mars Pathfinder, была принята архитектура, которую сами разработчики называли "общей шиной" - глобальная разделяемая область памяти, которую все процессы в системе использовали для коммуникации. Доступ к этой области защищался мутексом.
В системе существовала высокоприоритетная нить, занимавшаяся управлением шиной, которая периодически запускалась по сигналам таймера и собирала из "шины" некоторую важную для нее информацию. Эта же нить должна была сбрасывать сторожевой таймер, подтверждая, что система функционирует нормально.
Кроме того, в системе существовало еще несколько нитей, осуществлявших доступ к шине, в частности нить сбора метеорологических данных. Эта нить также запускалась по расписанию и копировала данные в буфер "шины", разумеется, захватывая при этом мутекс.
Таким образом, если нить управления "шиной" запускалась во время работы "метеорологической" нити, то она должна была ждать некоторое дополнительное время. В моменты, когда в системе не было других активных нитей, это не приводило к проблемам.
Однако когда накладывалось исполнение трех нитей, интервал ожидания сильно увеличивался, и это приводило к срабатыванию сторожевого таймера и сбросу бортового компьютера - в данном случае, ложному, потому что система все-таки оставалась работоспособной.
При тестировании на Земле сбросы такого рода несколько раз происходили, но разработчики не смогли воспроизвести условия их возникновения (срабатывание ошибки требует наложения трех нитей, каждая из которых сама по себе большую часть времени заблокирована) и отправили на Марс аппарат с недиагностированной проблемой. При эксплуатации непредсказуемые и происходящие, в среднем, раз в несколько дней сбросы бортового компьютера доставляли много неудобств центру управления полетом; к тому же, специалисты центра вынуждены были объяснять происходящее журналистам. На копии системы на Земле сбросы долгое время не удавалось воспроизвести; наконец, под утро, когда в лаборатории оставался только один разработчик, сброс все-таки произошел и по анализу отладочного дампа системы проблему удалось решить.
42. Сколько флагов на уровне пользовательской программы требуется для организации взаимоисключающего доступа двух задач к разделяемым данным?
Перед тем как начать работу с разделяемым ресурсом поток должен захватить мьютекс. Единовременно владеть мьютексом может только один поток. Поэтому, если потоку удается захватить мьютекс, это означает, что мьютекс был свободен. Если мьютекс занят, система переводит поток в режим ожидания до тех пор, пока мьютекс не освободится. Захватив мьютекс, поток начинает работать с ресурсом, имея гарантию на то, что, сколько бы потоков не пыталось захватить тот же самый мьютекс, все они будут ждать его освобождения. Закончив работу с ресурсом, поток освобождает мьютекс. Даже если в этот момент мьютекс ожидает несколько потоков, захватить его сможет только один поток (какой именно - решает планировщик). Таким образом, мьютекс гарантирует, что только один поток получает монопольный доступ к ресурсу.
Два флага занят либо свободен.
43. Какие недостатки у способа регулирования доступа к критическим данным двух задач с помощью одной переменной-флага?
Пусть имеются два (или более) циклических процесса, в которых есть абстракт-ные критические секции, то есть каждый из процессов состоит из двух частей: некоторого критического интервала и оставшейся части кода, в которой нет работы с общими (критическими) переменными. Пусть эти два процесса асинхронно разделяют во времени единственный процессор либо выполняются на отдельных процессорах, каждый из которых имеет доступ к некоторой общей области памяти, 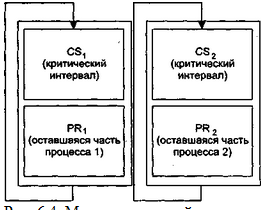 с которой и работают критические секции. Проиллюстрируем эту ситуацию с помощью рис. 6.4.
с которой и работают критические секции. Проиллюстрируем эту ситуацию с помощью рис. 6.4.
Проблема кажется легко решаемой, если потребовать, чтобы процессы ПР1 и ПР2 входили в свои критические интервалы попеременно. Для этого одна общая переменная может хранить указатель того, чья очередь войти в критическую секцию.
Однако если бы часть программы PR1 была намного длиннее, чем программа PR2, или если бы процесс ПР1 был заблокирован в секции PR1, или если бы процессор для ПР2 был с большим быстродействием, то процесс ПР2 вскоре вынужден был бы ждать (и, может быть, чрезвычайно долго) входа в свою критическую секцию CS2, хотя процесс ПР1 и был бы вне CS1. То есть при таком решении один процесс вне своей критической секции может помешать вхождению другого в свою критическую секцию.
44. Какие средства организации взаимоисключающего доступа задач к разделяемым данным можно использовать в программах?
1.He использовать алгоритмы планирования задач с вытеснением. Это решение, правда, не всегда приемлемо.
2. Использовать специальный сервер ресурса, то есть задачу ответственную за упорядочивание доступа к ресурсу. В этом случае запрос на изменение значения глобальных данных посылается этому серверу в виде сообщения. Аналогичный подход применим и для физических устройств. Так, например, задача может послать данные на печать в виде сообщения, направленного к серверу принтера.
3. Запретить прерывания на время доступа к разделяемым данным. Кардинальное решение, которое, впрочем, не приветствуется в системах реального времени.
4. Использовать для упорядочивания доступа к глобальным данным семафоры. Наиболее часто применяемое решение, которое, впрочем, может привести в некоторых случаях к «инверсии приоритетов».
Семафор — это как раз то средство, которое часто используется для синхронизации доступа к ресурсам. В простейшем случае семафор представляет собой байтовую переменную, принимающую значение 0 или 1. Задача, перед тем как использовать ресурс, захватывает семафор, после чего остальные задачи, желающие использовать тот же ресурс, должны ждать, пока семафор (ресурс) освободится.
Проникнувшись сознанием того, насколько опасно изменять глобальные переменные в условиях, когда все вокруг так и норовят друг друга вытеснить, наверно, не удивительно, что участки кода программ, где происходит обращение к разделяемым ресурсам, называются критическими секциями.
Так как процессы обычно не имеют доступа к данным друг друга, а ресурсы физических устройств, как правило, управляются специальными задачами-серверами (драйверами), наиболее типична ситуация, когда «гонки» за доступ к глобальным переменным устраивают различные потоки, исполняемые в рамках одного программного модуля. Для того чтобы гарантировать, что критическая секция кода исполняется в каждый момент времени только одним потоком, используют механизм взаимоисключающего доступа, или попросту мутексов (Mutual Exclusion Locks, Mutex). Практически мутекс представляет собой разновидность семафора, который сигнализирует другим потокам, что критическая секция кода кем-то уже выполняется.
45. Какие проблемы взаимоисключающего доступа задач к разделяемым данным с помощью флагов решает алгоритм Петерсона?
Организация взаимоисключения для критических участков, конечно, позволит избежать возникновения race condition, но не является достаточной для правильной и эффективной параллельной работы кооперативных процессов. Сформулируем пять условий, которые должны выполняться для хорошего программного алгоритма организации взаимодействия процессов, имеющих критические участки, если они могут проходить их в произвольном порядке.
1. Задача должна быть решена чисто программным способом на обычной машине, не имеющей специальных команд взаимоисключения. При этом предполагается, что основные инструкции языка программирования (такие примитивные инструкции, как load, store, test) являются атомарными операциями.
2. Не должно существовать никаких предположений об относительных скоростях выполняющихся процессов или числе процессоров, на которых они исполняются.
3. Если процесс Pi исполняется в своем критическом участке, то не существует никаких других процессов, которые исполняются в соответствующих критических секциях. Это условие получило название условия взаимоисключения (mutual exclusion).
4. Процессы, которые находятся вне своих критических участков и не собираются входить в них, не могут препятствовать другим процессам входить в их собственные критические участки. Если нет процессов в критических секциях и имеются процессы, желающие войти в них, то только те процессы, которые не исполняются в remainder section, должны принимать решение о том, какой процесс войдет в свою критическую секцию. Такое решение не должно приниматься бесконечно долго. Это условие получило название условия прогресса (progress).
5. Не должно возникать неограниченно долгого ожидания для входа одного из процессов в свой критический участок. От того момента, когда процесс запросил разрешение на вход в критическую секцию, и до того момента, когда он это разрешение получил, другие процессы могут пройти через свои критические участки лишь ограниченное число раз. Это условие получило название условия ограниченного ожидания (bound waiting).
46. Какие виды семафоров вы знаете?
Существует несколько видов семафоров: семафор событий, взаимного исключения, взаимного ожидания и именованный.
Когда семафор событий находится в нерабочем состоянии, операционная система блокирует исполнение всех процессов, которые запрашивают состояние семафора.
Семафоры взаимного исключения предотвращают возникновение тупиков при обращении к разделяемым ресурсам. Операционная система блокирует доступ к разделяемому ресурсу до тех пор, пока соответствующий семафор не будет свободен. При использовании разделяемого ресурса система устанавливает значение семафора в рабочее состояние, показывая тем самым, что ресурс занят.
Семафор взаимного ожидания представляет собой пакет из семафоров взаимного исключения или семафоров событий. Система может приостановить процесс до тех пор, пока один или все семафоры внутри именованного семафора не окажутся в состоянии 'свободен'(в зависимости от потребности процесса).
Реакция на именованный семафор зависит от процессов, совместно использующих его. В операционных системах OS/2 и выньДОС существует специальный механизм для взаимодействия процессов в реальном масштабе времени. Этот механизм называется DDE (Dynamic Data Exchange - динамический обмен данными). Он стандартизирует процесс обмена командами, сообщениями и объектами для обработки между задачами. Наиболее распространенные действия, для которых используются DDE - печать.
47. Какие основные подходы к управлению совместно выполняемыми задачами используются в системах реального времени (СРВ) для предсказуемого по времени их поведения?
В связи с проблемой дедлайнов главной проблемой в ОСРВ становится планирование задач (scheduling), которое обеспечивало бы предсказуемое поведение системы при всех обстоятельствах. Процесс с дедлайнами должен стартовать и выполняться так, чтобы он не пропустил ни одного своего дедлайна. Если это невозможно, процесс должен быть отклонен.
В связи с проблемами планирования в ОСРВ изучаются и развиваются два подхода – статические алгоритмы планирования (RMS – Rate Monotonic Scheduling) [LL73] и динамические алгоритмы планирования (EDF – Earliest Deadline First).
RMS используется для формального доказательства условий предсказуемости системы. Для реализации этой теории необходимо планирование на основе приоритетов, прерывающих обслуживание (preemptive priority scheduling). В теории RMS приоритет заранее назначается каждому процессу. Процессы должны удовлетворять следующим условиям:
• процесс должен быть завершен за время его периода,
• процессы не зависят друг от друга,
• каждому процессу требуется одинаковое процессорное время на каждом интервале,
• у непериодических процессов нет жестких сроков,
• прерывание процесса происходит за ограниченное время.
Процессы выполняются в соответствии с приоритетами. При планировании RMS предпочтение отдается задачам с самыми короткими периодами выполнения.
В EDF приоритет присваивается динамически, и наибольший приоритет выставляется процессу, у которого осталось наименьшее время выполнения. При больших загрузках системы у EDF имеются преимущества перед RMS.
Во всех системах реального времени требуется политика планирования, управляемая дедлайнами (deadline-driven scheduling). Однако этот подход находится в стадии разработки.
48 Что такое mutex?
Мьютекс (взаимоисключение, mutex) - это объект синхронизации, который устанавливается в особое сигнальное состояние, когда не занят каким-либо потоком. Только один поток владеет этим объектом в любой момент времени, отсюда и название таких объектов - одновременный доступ к общему ресурсу исключается. Например, чтобы исключить запись двух потоков в общий участок памяти в одно и то же время, каждый поток ожидает, когда освободится мьютекс, становится его владельцем и только потом пишет что-либо в этот участок памяти. После всех необходимых действий мьютекс освобождается, предоставляя другим потокам доступ к общему ресурсу.
49. В чём отличие мутекса от семафора?
Взаимоисключения (mutex, мьютекс) — это объект синхронизации, который устанавливается в особое сигнальное состояние, когда не занят каким-либо потоком. Только один поток владеет этим объектом в любой момент времени, отсюда и название таких объектов (от английского mutually exclusive access — взаимно исключающий доступ) — одновременный доступ к общему ресурсу исключается. После всех необходимых действий мьютекс освобождается, предоставляя другим потокам доступ к общему ресурсу. Объект может поддерживать рекурсивный захват второй раз тем же потоком, увеличивая счетчик, не блокируя поток, и требуя потом многократного освобождения. Таков, например, mutex в Win32и KMUTEX в ядре Windows. Тем не менее есть и такие реализации, которые не поддерживают такое и приводят к взаимной блокировке потока при попытке рекурсивного захвата. Это FAST_MUTEX в ядре Windows и критическая секция в Win32.
Семафоры представляют собой доступные ресурсы, которые могут быть приобретены несколькими потоками в одно и то же время, пока пул ресурсов не опустеет. Тогда дополнительные потоки должны ждать, пока требуемое количество ресурсов не будет снова доступно. Семафоры очень эффективны, поскольку они позволяют одновременный доступ к ресурсам. Семафор есть логическое расширение мьютекса — семафор со счетчиком 1 эквивалентен мьютексу, но счетчик может быть и более 1.
50. Что такое инверсия приоритета?
Инверсия приоритетов – это ситуация, в которой, в результате взаимных синхронизаций, управление получает не та ветвь исполнения, которая должна была бы получить из соображений приоритетности, а другая, с более низким приоритетом.
Механизмы, порождающие это явление, могут быть разнообразны (счетные семафоры).
51. При каких схемах планирования задач инверсия приоритета возникает? Фиксированные приоритеты - приоритет задаче назначается при ее создании и не
меняется в течение ее жизни. Эта схема с различными дополнениями применяется в
большинстве систем реального времени. В схемах планирования ОСРВ часто требуется,
чтобы приоритет каждой задачи был уникальным, поэтому часто ОСРВ имеют большое
число приоритетов (обычно 255 и более).
52. Что необходимо для возникновения инверсия приоритета?
Представим, что у нас есть высокоприоритетная Задача A, среднеприоритетная Задача B и низкоприоритетная Задача C.
Пусть в начальный момент времени Задачи A и B блокированы в ожидании какого-либо
внешнего события. Допустим, получившая в результате этого управление Задача C захватила
Ресурс A, но не успела его отдать, как была прервана Задачей A. В свою очередь, Задача A при
попытке захватить Ресурс A будет блокирована, так как этот ресурс уже захвачен Задачей C.
Если к этому времени Задача B находится в состоянии готовности, то управление после этого
получит именно она, как имеющая более высокий, чем у Задачи C, приоритет. Теперь Задача B может занимать процессорное время, пока ей не надоест, а мы получаем ситуацию, когда
высокоприоритетная Задача A не может функционировать из-за того, что необходимый ей
ресурс занят низкоприоритетной Задачей C.
Блокировка (Lockout). Процесс ожидает ресурс, который никогда не освободится.
Голодовка (Starvation). Процесс монополизировал процессор.
|
|
|
|
|
Дата добавления: 2014-12-24; Просмотров: 1027; Нарушение авторских прав?; Мы поможем в написании вашей работы!