КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Прямолинейная
|
|
|
|
Корреляционный анализ(показатели)
Важнейшей целью статистики является изучение объективно существующих связей между явлениями. В ходе статистического исследования этих связей необходимо выявить причинно-следственные зависимости между показателями, т.е. насколько изменение одних показателей зависит от изменения других показателей. Корреляционная связь - это связь, где воздействие отдельных факторов проявляется только как тенденция (в среднем) при массовом наблюдении фактических данных. Примерами корреляционной зависимости могут быть зависимости между размерами активов банка и суммой прибыли банка, ростом производительности труда и стажем работы сотрудников.
Наиболее простым вариантом корреляционной зависимости является парная корреляция, т.е. зависимость между двумя признаками. Математически эту зависимость можно выразить как зависимость результативного показателя у от факторного показателя х. Связи могут быть прямые и обратные. В первом случае с увеличением признака х увеличивается и признак у, при обратной связи с увеличением признака х уменьшается признак у.
Важнейшей задачей является определение формы связи с последующим расчетом параметров уравнения, или, иначе, нахождение уравнения связи (уравнения регрессии).
Могут иметь место различные формы связи:
криволинейная в виде: параболы второго порядка (или высших порядков) гиперболы, показательной функции
Параметры для всех этих уравнений связи, как правило, определяют из системы нормальных уравнений, которые должны отвечать требованию метода наименьших квадратов (МНК):
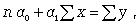
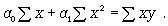 (8.5)
(8.5)
Если связь выражена параболой второго порядка (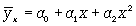 ), то систему нормальных уравнений для отыскания параметров a0, a1, a2 (такую связь называют множественной, поскольку она предполагает зависимость более чем двух факторов) можно представть в виде
), то систему нормальных уравнений для отыскания параметров a0, a1, a2 (такую связь называют множественной, поскольку она предполагает зависимость более чем двух факторов) можно представть в виде
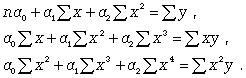 (8.6)
(8.6)
Другая важнейшая задача - измерение тесноты зависимости - для всех форм связи может быть решена при помощи вычисления эмпирического корреляционного отношения 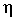 :
:
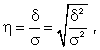 где -
где - 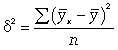 дисперсия в ряду выравненных значений результативного показателя
дисперсия в ряду выравненных значений результативного показателя 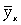 ;
; 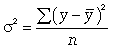 - дисперсия в ряду фактических значений у.
- дисперсия в ряду фактических значений у.
Для определения степени тесноты парной линейной зависимости служит линейный коэффициент корреляции r, для расчета которого можно использовать, например, две следующие формулы:
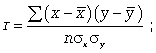
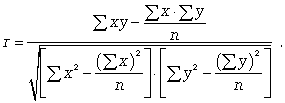
Линейный коэффициент корреляции может принимать значения в пределах от -1 до + 1 или по модулю от 0 до 1. Чем ближе он по абсолютной величине к 1, тем теснее связь. Знак указывает направление связи: «+» - прямая зависимость, «-» имеет место при обратной зависимости.
В статистической практике могут встречаться такие случаи, когда качества факторных и результативных признаков не могут быть выражены численно. Поэтому для измерения тесноты зависимости необходимо использовать другие показатели. Для этих целей используются так называемые непараметрические методы.
Наибольшее распространение имеют ранговые коэффициенты корреляции, в основу которых положен принцип нумерации значений статистического ряда. При использовании коэффициентов корреляции рангов коррелируются не сами значения показателей х и у, а только номера их мест, которые они занимают в каждом ряду значений. В этом случае номер каждой отдельной единицы будет ее рангом.
Коэффициент корреляции рангов Спирмэна (р) основан на рассмотрении разности рангов значений результативного и факторного признаков и может быть рассчитан по формуле
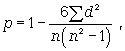 где d = Nx - Ny, т.е. разность рангов каждой пары значений х и у; n - число наблюдений.
где d = Nx - Ny, т.е. разность рангов каждой пары значений х и у; n - число наблюдений.
Ранговый коэффициент корреляции Кендэла (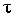 ) можно определить по формуле
) можно определить по формуле
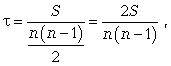 где S = P + Q.
где S = P + Q.
К непараметрическим методам исследования можно отнести коэффициент ассоциации Кас и коэффициент контингенции Ккон, которые используются, если, например, необходимо исследовать тесноту зависимости между качественными признаками, каждый из которых представлен в виде альтернативных признаков.
Для определения этих коэффициентов создается расчетная таблица (таблица «четырех полей)
Коэффициент ассоциации можно расcчитать по формуле
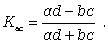 (8.11)
(8.11)
Коэффициент контингенции рассчитывается по формуле
 (8.12)
(8.12)
Нужно иметь в виду, что для одних и тех же данных коэффициент контингенции (изменяется от -1 до +1) всегда меньше коэффициента ассоциации.
Если необходимо оценить тесноту связи между альтернативными признаками, которые могут принимать любое число вариантов значений, применяется коэффициент взаимной сопряженности Пирсона (КП).
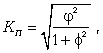 где
где 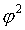 - показатель средней квадратической сопряженности:
- показатель средней квадратической сопряженности:
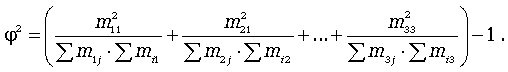
Коэффициент взаимной сопряженности изменяется от 0 до 1.
Наконец, следует упомянуть коэффициент Фехнера, характеризующий элементарную степень тесноты связи, который целесообразно использовать для установления факта наличия связи, когда существует небольшой объем исходной информации. Данный коэффициент определяется по формуле
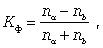 где na - количество совпадений знаков отклонений индивидуальных величин от их средней арифметической; nb - соответственно количество несовпадений.
где na - количество совпадений знаков отклонений индивидуальных величин от их средней арифметической; nb - соответственно количество несовпадений.
60. Способы оценки полученных моделей регрессии
Регрессионный анализ раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным. Цель Р. а. состоит в определении общего вида уравнения регрессии, построении оценок неизвестных параметров, входящих в уравнение регрессии, и проверке статистических гипотез о регрессии. При изучении связи между двумя величинами по результатам наблюдений (x 1, y 1),..., (x n, y n) в соответствии с теорией регрессии предполагается, что одна из них Y имеет некоторое распределение вероятностей при фиксированном значении х другой, так что
Е(Y | х) = g (x, β) и D(Y | х) = σ2 h 2(x),
где β обозначает совокупность неизвестных параметров, определяющих функцию g (х), a h (x) есть известная функция х (в частности, тождественно равная 1). Выбор модели регрессии определяется предположениями о форме зависимости g (х, β) от х и β. Наиболее естественной с точки зрения единого метода оценки неизвестных параметров β является модель регрессии, линейная относительно β:
g (x, β) = β0 g 0(x) +... + βk g k(x).
Относительно значений переменной х возможны различные предположения в зависимости от характера наблюдений и целей анализа. Для установления связи между величинами в эксперименте используется модель, основанная на упрощённых, но правдоподобных допущениях: величина х является контролируемой величиной, значения которой заранее задаются при планировании эксперимента, а наблюдаемые значения у представимы в виде
yi = g (xi, β) + εi, i = 1,..., k,
где величины ε i характеризуют ошибки, независимые при различных измерениях и одинаково распределённые с нулевым средним и постоянной дисперсией σ2. Случай неконтролируемой переменной х отличается тем, что результаты наблюдений (xi, yi),..., (xn, yn) представляют собой выборку из некоторой двумерной совокупности. И в том, и в другом случае Р. а. производится одним и тем же способом, однако интерпретация результатов существенно различается (если обе исследуемые величины случайны, то связь между ними изучается методами корреляционного анализа).
Предварительное представление о форме графика зависимости g (x) от х можно получить по расположению на диаграмме рассеяния (называемой также корреляционным полем, если обе переменные случайные) точек (xi, y̅ (xi)), где y̅ (xi) — средние арифметические тех значений у, которые соответствуют фиксированному значению xi. Например, если расположение этих точек близко к прямолинейному, то допустимо использовать в качестве приближения линейную регрессию. Стандартный метод оценки линии регрессии основан на использовании полиномиальной модели (m ≥ 1)
y (x, β) = β0 + β1 x +... + βm x m
(этот выбор отчасти объясняется тем, что всякую непрерывную на некотором отрезке функцию можно приблизить полиномом с любой наперёд заданной степенью точности). Оценка неизвестных коэффициентов регрессии β0,..., βm и неизвестной дисперсии σ2 осуществляется Наименьших квадратов методом. Оценки 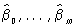 0,..., βm, полученные этим методом, называются выборочными коэффициентами регрессии, а уравнение
0,..., βm, полученные этим методом, называются выборочными коэффициентами регрессии, а уравнение
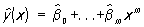
определяет т. н. эмпирическую линию регрессии. Этот метод в предположении нормальной распределённости результатов наблюдений приводит к оценкам для β0,..., βm и σ2, совпадающим с оценками наибольшего правдоподобия.Оценки, полученные этим методом, оказываются в некотором смысле наилучшими и в случае отклонения от нормальности. Так, если проверяется гипотеза о линейной регрессии, то
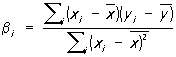
где 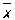 xi и yi, и оценка
xi и yi, и оценка  g(х), а её дисперсия будет меньше, чемдисперсия любой другой линейной оценки. При допущении, что величины yi нормально распределены, наиболее эффективно осуществляется проверка точности построенной эмпирической регрессионной зависимости и проверка гипотез о параметрах регрессионной модели. В этом случае построение доверительных интервалов для истинных коэффициентов регрессии β0,..., βm и проверка гипотезы об отсутствии регрессионной связи βi = 0, i = 1,..., m) производится с помощью Стьюдента распределения.
g(х), а её дисперсия будет меньше, чемдисперсия любой другой линейной оценки. При допущении, что величины yi нормально распределены, наиболее эффективно осуществляется проверка точности построенной эмпирической регрессионной зависимости и проверка гипотез о параметрах регрессионной модели. В этом случае построение доверительных интервалов для истинных коэффициентов регрессии β0,..., βm и проверка гипотезы об отсутствии регрессионной связи βi = 0, i = 1,..., m) производится с помощью Стьюдента распределения.
В более общей ситуации результаты наблюдений y1,..., yn рассматриваются как независимые случайные величины с одинаковыми дисперсиями и математическими ожиданиями
Eyi, = β1 x1i +... + βkxki, i = 1,..., n,
где значения xji, j = 1,..., k предполагаются известными. Эта форма линейной модели регрессии является общей в том смысле, что к ней сводятся модели более высоких порядков по переменным x1,..., xk. Кроме того, некоторые нелинейные относительно параметров βi; модели подходящим преобразованием также сводятся к указанной линейной форме.
|
|
|
|
|
Дата добавления: 2014-12-24; Просмотров: 532; Нарушение авторских прав?; Мы поможем в написании вашей работы!