КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Кодирование для сжатия информации
|
|
|
|
Алгоритмы кодирования нередко используются для сжатия не только при передаче, но и при архивации данных. Одним из таких примеров является кодирование текстовой информации в сервисе коротких сообщении в мобильной связи (SMS сервис). Текст в сообщении передается в сжатом виде. В большинстве случаев для каждого символа текста отводится один байт, что верно и для представления текстовой (строковой) информации в языке Си. Однако, из ASCII таблицы чаще всего используются лишь первые 127 символов, включающие в себя английский алфавит, цифры, основные знаки препинания и служебные дополнительные символы (например, * или \). Очевидно, что для хранения этих символов достаточно лишь 7 бит (127 значений для кода символа), что несколько меньше байта. Такой подход как раз и используется при кодировании SMS сообщений, что позволяет передать больше символов в одном сообщении. Первые поколения GSM сетей не позволяли передавать данные на большой скорости и не позволяли совмещать передачу данных и голосовой звонок. Поэтому, чем короче сообщение, тем меньше занимает эфирного времени его передача и тем меньше времени абонент занят для голосового звонка. Стандарт GSM выделяет максимум 160 байт для одного текстового сообщения, 20 из которых – это служебная информация. На сам текст остается 140 байт, в которых при 7 битовом кодировании, можно разметить 160 текстовых символов.
Рассмотрим алгоритм реализации такого кодирования. Однако прежде чем перейти к коду алгоритма, следует учесть еще один факт. Большинство устройств, отвечающих за передачу данных в GSM сетях, являются модемами, которые взаимодействуют с другими устройствами посредством стандартного протокола, т.е. при помощи так называемых AT-команд. Эти команды можно посылать модему через терминал (последовательный поток ввода и поток вывода). При этом передаваемая бинарная информация представляется побайтово в шестнадцатеричном виде, чтобы не возникало конфликтов с управляющими AT командами.
Т.е., например, если в тексте сообщения содержится символ '1' (имеющий ASCII код 49), то для 1 байтового кодирования он имел бы двоичное представление:
0011 0001
Для 7-ми битного кодирования он имеет вид:
011 0001
А при передаче го через терминал он будет представлен двумя символами как:
«31»
Т.е. в виде шестнадцатеричного числа 31, представленного как текст (т.е. именно двумя символами, а не одним символом с кодом 31).
Поэтому при кодировании текста для передачи SMS необходимо его не просто закодировать в 7-ми битный код, но затем еще и представить его в виде шестнадцатеричного текстового кода, «понятного» GSM модему.
Из 1 байтового представления текста 7 битный код получается следующим образом. Для первого символа берутся 7 младших бит и записываются в 7 младших бит первого байта результата. Далее от второго символа исходного текста берутся 6 младших бит и записываются в 6 младших бит второго байта результата. От второго символа остается один (7-й) значащий бит, который записывается в старший 8-й бит первого байта результата (который как раз не использован для хранения первого символа). Для третьего входного символа в третий байт результата записывается только 5 младших байт. А два остающихся значащих бита (7-й и 6-й) сохраняются соответственно в 8-м и 7-м битах второго байта результата (они как раз не использованы для хранения второго символа). Дойдя до восьмого символа получается, что от него надо записать 0 бит в восьмой байт результата, а все 7 значащих бита запишутся в старшие 7 бит 7-го байта результата. Таким образом, для 8 символов потребуется 7 байт. Далее процесс повторяется. Описанная схема представлена на рисунке 8.
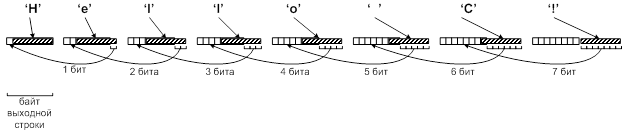
Рисунок 8. 7-битное кодирование строки «Hello C!» в SMS
Реализация метода кодирования на языке Си может иметь следующий вид.
void encodeToPDU(char *text, char *res) {
int len;
int i, j;
int shift;
unsigned char prevNum, curNum, tmpVal1, tmpVal2, curValue;
j = 0;
i = 0;
prevNum = 0;
len = length(text);
tmpVal1 = 0;
tmpVal2 = 0;
while(i < len) {
curNum = (unsigned char)text[i];
/* special code for symbol @ */
if (text[i] == '@') {curNum = 0;}
shift = (i % 8);
curValue = curNum & 127;
curValue = (curValue >> shift);
tmpVal2 = curValue;
if (i > 0) {
prevNum = (curNum << (8 - shift));
tmpVal1 = tmpVal1 | prevNum;
}
if (shift!= 7) {
if (i > 0) {
res[j] = decToHex(tmpVal1 / 16);
res[j + 1] = decToHex(tmpVal1 % 16);
j+=2;
}
tmpVal1 = tmpVal2;
}
i++;
}
res[j] = decToHex(tmpVal1 / 16);;
res[j + 1] = decToHex(tmpVal1 % 16);
res[j + 2] = '\0';
}
Здесь используется функция нахождения длины строки length:
int length(char *str) {
int i;
i = 0;
while(*str++) {
i++;
}
return i;
}
Выделение нужного количества бит в байте реализуется в Си посредством сдвига. При помощи этой же операции можно выставить значащие биты на нужные позиции. Для «удаления» незначащих бит можно использовать логическую операцию И с числом-маской, в котором на позиции незначащих бит выставляются нули, а на позиции значащих – единицы. После операции И с таким числом-маской все незначащие биты становятся равными нулю.
Приведенная функция encodeToPDU принимает на вход текст из параметра text и двигается по нему посимвольно, для задания текущей позиции используется переменная i. Выходная строка res также формируется последовательно в один проход, рис 9.

Рисунок 9. Работа функции encodeToPDU для строки «Hello C!»
Для всех входных символов перед их обработкой выполняется операция И с маской 127 (0111 1111) для выставления в 0 незначащего старшего бита:
curNum = (unsigned char)text[i];
curValue = curNum & 127;
Далее для каждого символа входной строки вычисляется сдвиг, на который необходимо сдвинуть значащие биты вправо, чтобы далее записать оставшееся количество значащих бит в текущий выходной байт. Текущий выходной байт сохраняется в переменную tmpVal2:
curValue = (curValue >> shift);
tmpVal2 = curValue;
Количество записываемых в текущий выходной байт бит как раз равно сдвигу. Сдвиг считается как:
shift = (i % 8);
Т.е. для первого символа он равен нулю, далее возрастает на каждом шаге на единицу. Для 8-го символа он оказывается равен 7, т.е. все значащие биты сдвигаются и ни один из них не записывается в текущий выходной байт (в 8-й выходной байт). Все сдвинутые биты записываются в предыдущий выходной байт, который сохраняется в переменной tmpVal1. Для этого текущий входной байт сдвигается на (8 - shift) бит, т.е. нужное количество значащих бит оказывается в старших битах.
if (i > 0) {
prevNum = (curNum << (8 - shift));
tmpVal1 = tmpVal1 | prevNum;
}
И только для первого входного символа и соотвествующего ему первого выходного байта не надо сохранять ничего в предыдущий выходной байт.
Для 8-го входного символа все 7 значащих бит записываются в 7-й байт результата. После каждого перехода к следующему символу во входной строке необходимо сохранить текущий выходной байт в переменную tmpVal1, чтобы «освободить» для следующего шага переменную tmpVal2:
if (shift!= 7) {
...
tmpVal1 = tmpVal2;
}
Такое перемещение не надо выполнять только для каждого 8-го входного символа, когда все семь значащих бит сохраняются в предыдущий выходной байт, а текущий оказывается не заполненным (shift = 7).
Как уже было отмечено, кодирование происходит в один проход. В результате выполнения функции получается не бинарный код, реально отправляемый в SMS, а его шестнадцатеричное представление, которое можно передать GSM модему посредством терминала. Поэтому каждый выходной байт представляется в виде пары шестнадцатеричных цифр:
res[j] = decToHex(tmpVal1 / 16);
res[j + 1] = decToHex(tmpVal1 % 16);
Функция decToHex преобразует десятичную цифру в шестнадцатеричную.
char decToHex(unsigned char val) {
if ((val >= 0) && (val <= 9)) {
return (char)(val + (unsigned char)'0');
} else {
if ((val >= 10) && (val <= 15)) {
return (char)(val + (unsigned char)'A' - 10);
} else {
return 0;
}
}
}
Деление десятичного числа на 16 дает первый разряд шестнадцатеричного числа, а остаток от деления – второй. Отметим, что в выходную строку записывается не текущий получаемый выходной байт (tmpVal2), а предыдущий - tmpVal1, т.к. к нему в старшие биты уже добавлены биты следующего входного символа (получаемые как curNum << (8 - shift)). Поэтому после прохождения всей входной строки в цикле
while(i < len) {...}
в переменной tmpVal2 остается последний формируемый выходной символ, который в конце цикла записывается в tmpVal1. Его приходится дополнительно кодировать в шестнадцатеричное представление после завершения цикла:
res[j] = decToHex(tmpVal1 / 16);;
res[j + 1] = decToHex(tmpVal1 % 16);
res[j + 2] = '\0';
В конец строки согласно правилам представления строки в Си дописывается символ '\0'.
Теперь рассмотрим функцию декодирования сообщения decodeFromPDU.
void decodeFromPDU(char *str, char *res) {
int len;
int i, j;
int shift;
unsigned char prevNum, d1, d2, curNum, curRes;
j = 0;
len = length(str);
i = 1;
prevNum = 0;
while(str[i-1]) {
if(str[i]) {
d1 = hexToDec(str[i-1]);
d2 = hexToDec(str[i]);
curNum = d1*16 + d2;
shift = ((((i + 1) / 2)-1) % 7);
if(((shift) == 0)&&(i>1)) {
prevNum = prevNum & 127;
res[j++] = prevNum;
/* special code for symbol @ */
if (res[(j-1)] == 0) {res[(j-1)] = (unsigned char)'@';}
prevNum = (curNum >> (7 - shift));
}
curRes = (curNum << shift) + prevNum;
curRes = curRes & 127;
res[j++] = curRes;
/* special code for symbol @ */
if (res[(j-1)] == 0) {res[(j-1)] = (unsigned char)'@';}
prevNum = (curNum >> (7 - shift));
} else {
break;
}
i+=2;
}
if(shift == 6) {
prevNum = prevNum & 127;
/* special code for symbol @ */
if (res[(j-1)] == 0) {res[(j-1)] = (unsigned char)'@';}
res[j++] = prevNum;
}
res[j] = '\0';
}
Она так же последовательно движется по входной строке str, в которой закодированный текст SMS сообщения представлен в шестнадцатеричном текстовом виде.
Поэтому шаг равен двум (на каждой итерации цикла прохода по строке str выполняется i+=2) и очередные два символа переводятся в один байт кода SMS:
d1 = hexToDec(str[i-1]);
d2 = hexToDec(str[i]);
curNum = d1*16 + d2;
Функция hexToDec переводит шестнадцатеричную текстовую цифру в десятичное число:
unsigned char hexToDec(char hexDigit) {
if ((hexDigit >= '0') && (hexDigit <= '9')) {
return (unsigned char)hexDigit - (unsigned char)'0';
} else {
if ((hexDigit >= 'A') && (hexDigit <= 'F')) {
return (unsigned char)hexDigit - (unsigned char)'A' + 10;
} else {
return 0;
}
}
}
Далее рассчитывается сдвиг, на который в текущем кодированном байте сдвинут код текущего символа:
shift = ((((i + 1) / 2)-1) % 7);
Здесь ((i + 1) / 2) дает номер входного байта (i – это счетчик шестнадцатеричных символов, начинающийся с 0, на каждый входной кодированный байт занято две шестнадцатеричные цифры).
На первом шаге (i=1) сдвиг равен нулю, на втором он равен 1, для 7-го входного кодированного байта (i=13) сдвиг равен 6. Для 8-го входного байта сдвиг снова равен 0, т.к. в его 7 младших байтах полностью содержится 9-й выходной символ. А 8-й выходной символ хранятся в 7 старших битах 7-го входного байта. Чтобы его декодировать, на каждом 7-м входном байте для которого сдвиг оказывается равен 0, надо сделать двойную обработку – «вынуть» символ и предыдущего байта с учетом одного бита из текущего байта и «вынуть» символ из текущего байта, для чего дополнительно выполняется следующий код:
if(((shift) == 0)&&(i>1)) {
prevNum = prevNum & 127;
res[j++] = prevNum;
/* special code for symbol @ */
if (res[(j-1)] == 0) {res[(j-1)] = (unsigned char)'@';}
prevNum = (curNum >> (7 - shift));
}
Следует отметить, что если количество байт кода кратно 8, то на последнем шаге обрабатывается лишь один младший бит последнего байта кода, а сдвиг равен 6. «Вынимание» последнего закодированного символа (их первых 7 бит последнего байта кода) по алгоритму выполняется на следующей итерации, который уже не будет, поэтому надо после цикла отдельно сформировать последний символ:
if(shift == 6) {
prevNum = prevNum & 127;
/* special code for symbol @ */
if (res[(j-1)] == 0) {res[(j-1)] = (unsigned char)'@';}
res[j++] = prevNum;
}
res[j] = '\0';
В GSM кодировка символов определяется стандартом GSM 03.38 и несколько отличается от стандартной таблицы ASCII. В частности, символ '@’ имеет код 0 и совпадает с кодом конца строки в Си. Из-за этого в приведенном примере символ с кодом '\0' заменяется символом '@’:
if (res[(j-1)] == 0) {res[(j-1)] = (unsigned char)'@';}
А при работе с кодировкой GSM 03.38 на языке Си необходимо знать длину строки, иначе в случае 8-ми символов текста, в которых последний символ равен '@’, последний значащий байт строки равен 0, что соответствует символу конца строки и он не будет корректно обрабатываться стандартными функциями как значащий.
В случае, когда необходимо передать символы, отсутствующие в GSM 03.38 используется Unicode, в котором один символ кодируется 2 байтами. В Unicode можно хранить сразу несколько алфавитов, но в этом случае 140 байт вмещают лишь 70 символов текста. Поэтому, если в SMS сообщении содержатся русские буквы (которых нет в таблице GSM 03.38), то оно кодируется в формате Unicode и содержит максимум 70 символов. Если же использовать только английский алфавит, то как уже было показано, в сообщении можно использовать целых 160 символов!
|
|
|
|
|
Дата добавления: 2014-12-26; Просмотров: 953; Нарушение авторских прав?; Мы поможем в написании вашей работы!