КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Описание алгоритма
|
|
|
|
Алгоритм k-средних (k-means)
Наиболее распространен среди неиерархических методов алгоритм k-средних, также называемый быстрым кластерным анализом. В отличие от иерархических методов, которые не требуют предварительных предположений относительно числа кластеров, для возможности использования этого метода необходимо иметь гипотезу о наиболее вероятном количестве кластеров. Алгоритм k-средних строит k кластеров, расположенных на возможно больших расстояниях друг от друга. Основной тип задач, которые решает алгоритм k-средних, - наличие предположений (гипотез) относительно числа кластеров, при этом они должны быть различны настолько, насколько это возможно. Выбор числа k может базироваться на результатах предшествующих исследований, теоретических соображениях или интуиции.
Общая идея алгоритма: заданное фиксированное число k кластеров наблюдения сопоставляются кластерам так, что средние в кластере (для всех переменных) максимально возможно отличаются друг от друга.
Первоначальное распределение объектов по кластерам.
Выбирается число k, и на первом шаге эти точки считаются "центрами" кластеров. Каждому кластеру соответствует один центр.
Выбор начальных центроидов может осуществляться следующим образом:
· выбор k-наблюдений для максимизации начального расстояния;
· случайный выбор k-наблюдений;
· выбор первых k-наблюдений.
В результате каждый объект назначен определенному кластеру.
Итеративный процесс.
Вычисляются центры кластеров, которыми затем и далее считаются покоординатные средние кластеров. Объекты опять перераспределяются.
Процесс вычисления центров и перераспределения объектов продолжается до тех пор, пока не выполнено одно из условий:
· кластерные центры стабилизировались, т.е. все наблюдения принадлежат ккластеру, которому принадлежали до текущей итерации;
· число итераций равно максимальному числу итераций.
На рис. 24 приведен пример работы алгоритма k-средних для k, равного двум.
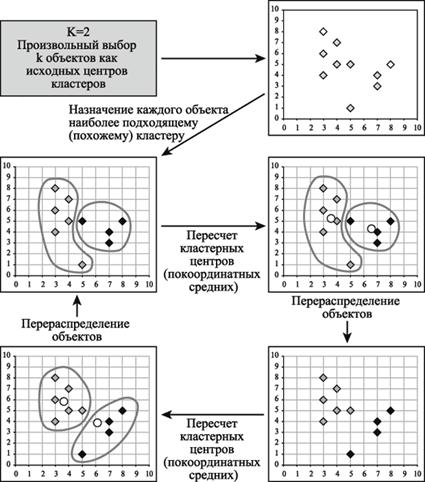
Рис. 24. Пример работы алгоритма k-средних (k=2)
Выбор числа кластеров является сложным вопросом. Если нет предположений относительно этого числа, рекомендуют создать 2 кластера, затем 3, 4, 5 и т.д., сравнивая полученные результаты.
Проверка качества кластеризации
После получений результатов кластерного анализа методом k-средних следует проверить правильность кластеризации (т.е. оценить, насколько кластеры отличаются друг от друга). Для этого рассчитываются средние значения для каждого кластера. При хорошей кластеризации должны быть получены сильно отличающиеся средние для всех измерений или хотя бы большей их части.
Достоинства алгоритма k-средних:
· простота использования;
· быстрота использования;
· понятность и прозрачность алгоритма.
Недостатки алгоритма k-средних:
· алгоритм слишком чувствителен к выбросам, которые могут искажать среднее. Возможным решением этой проблемы является использование модификации алгоритма - алгоритм k-медианы;
· алгоритм может медленно работать на больших базах данных. Возможным решением данной проблемы является использование выборки данных.
Анализ результатов кластеризации. Этот этап подразумевает решение таких вопросов: не является ли полученное разбиение на кластеры случайным; является ли разбиение надежным и стабильным на подвыборках данных; существует ли взаимосвязь между результатами кластеризации и переменными, которые не участвовали в процессе кластеризации; можно ли интерпретировать полученные результаты кластеризации.
Проверка результатов кластеризации. Результаты кластеризации также должны быть проверены формальными и неформальными методами. Формальные методы зависят от того метода, который использовался для кластеризации. Неформальные включают следующие процедуры проверки качества кластеризации:
· анализ результатов кластеризации, полученных на определенных выборках набора данных;
· кросс-проверка;
· проведение кластеризации при изменении порядка наблюдений в наборе данных;
· проведение кластеризации при удалении некоторых наблюдений;
· проведение кластеризации на небольших выборках.
Один из вариантов проверки качества кластеризации - использование нескольких методов и сравнение полученных результатов. Отсутствие подобия не будет означать некорректность результатов, но присутствие похожих групп считается признаком качественной кластеризации.
Если нет предположений относительно числа кластеров, рекомендуют использовать иерархические алгоритмы. Однако если объем выборки не позволяет это сделать, возможный путь - проведение ряда экспериментов с различным количеством кластеров, например, начать разбиение совокупности данных с двух групп и, постепенно увеличивая их количество, сравнивать результаты. За счет такого "варьирования" результатов достигается достаточно большая гибкость кластеризации.
При использовании иерархических методов существует возможность достаточно легко идентифицировать выбросы в наборе данных и, в результате, повысить качество данных. Эта процедура лежит в основе двухшагового алгоритма кластеризации. Такой набор данных в дальнейшем может быть использован для проведения неиерархической кластеризации.
Главное назначение кластерного анализа – разбиение множества исследуемых объектов и признаков на однородные в некотором смысле группы, или кластеры. В области медицины кластеризация заболеваний, лечения заболеваний приводит к широко используемым таксономиям. Иными словани, всякий раз, когда необходимо классифицировать большие информационные массивы на пригодные для дальнейшей обработки группы, применяется кластерный анализ. Большое достоинство кластерного анализа в том, что он позволяет проводить разбиение генеральной совокупности не по одному, а по ряду параметров одновременно. Кроме этого, он не накладывает никаких ограничений на вид рассматриваемых объектов и позволяет исследовать множество исходных данных практически произвольной природы.
Приложение.

 Таблица 1. Критические точки распределения Фишера - Снедекора
Таблица 1. Критические точки распределения Фишера - Снедекора
при а = 0,05
| k; k 2 | ||||||||||||
| 18,51 | 19,00 | 19,16 | 19,25 | 19,3 | 19,33 | 19,36 | 19,37 | 19,38 | 19,39 | 19,40 | 19,41 | |
| 10,13 | 9,55 | 9,28 | 9,12 | 9,01 | 8,94 | 8,88 | 8,84 | 8,81 | 8,78 | 8,76 | 8,74 | |
| 7,71 | 6,94 | 6,90 | 6,39 | 6,60 | 6,16 | 6,09 | 6,04 | 6,00 | 5,96 | 5,93 | 5,91 | |
| 6,61 | 5,79 | 5,41 | 5,19 | 5,05 | 4,95 | 4,88 | 4,82 | 4,78 | 4,74 | 4,70 | 4,68 | |
| 5,99 | 5,14 | 4,76 | 4,53 | 4,39 | 4,28 | 4,21 | 4,15 | 4,10 | 4,06 | 4,03 | 4,00 | |
| 5,59 | 4,74 | 4,35 | 4,12 | 3,97 | 3,87 | 3,79 | 3,73 | 3,68 | 3,63 | 3,60 | 3,57 | |
| 5,32 | 4,46 | 4,07 | 3,84 | 3,69 | 3,58 | 3,50 | 3,44 | 3,39 | 3,34 | 3,31 | 3,28 | |
| 5,12 | 4,26 | 3,86 | 3,63 | 3,48 | 3,37 | 3,29 | 3,23 | 3,18 | 3,13 | 3,10 | 3,07 | |
| 4,96 | 4Д | 3,71 | 3,48 | 3,33 | 3,22 | 3,14 | 3,07 | 3,02 | 2,97 | 2,94 | 2,91 | |
| 4,84 | 3,98 | 3,59 | 3,36 | 3,20 | 3,01 | 2,95 | 2,90 | 2,86 | 2,82 | 2,79 | ||
| 4,75 | 3,88 | 3,49 | 3,26 | 3,11 | 3,00 | 2,92 | 2,85 | 2,80 | 2,76 | 2,72 | 2,69 | |
| 4,67 | 3,8 | 3,41 | 3,18 | 3,02 | 2,92 | 2,84 | 2,77 | 2,72 | 2,67 | 2,63 | 2,60 | |
| 4,60 | 3,74 | 3,34 | 3,11 | 2,96 | 2,85 | 2,77 | 2,70 | 2,65 | 2,60 | 2,56 | 2,53 | |
| 4,54 | 3,68 | 3,29 | 3,06 | 2,90 | 2,79 | 2,70 | 2,64 | 2,59 | 2,55 | 2,51 | 2,48 |
Таблица 2. Значение хи-квадрат в зависимости от различных уровней значимости а и числа степеней свободы k
| k | а | k | а | ||
| 0,05 | 0,01 | 0,05 | 0,01 | ||
| 3,84 | 6,64 | 26,3 | 32,0 | ||
| 5,99 | 9,21 | 27,6 | 33.4 | ||
| 7,82 | 11,34 | 28,9 | 34,8 | ||
| 9,49 | 13,28 | 30,1 | 36,2 | ||
| 11,07 | 15,09 | 31,4 | 37,6 | ||
| 12,59 | 16,81 | 32,7 | 38,9 | ||
| 14,07 | 18,48 | 33,9 | 40,3 | ||
| 15,51 | 20,1 | 35,2 | 41,6 | ||
| 16,92 | 21,7 | 36,4 | 43,0 | ||
| 18,31 | 23,2 | 37,7 | 44,3 | ||
| 19,68 | 24,7 | 38,9 | 45,6 | ||
| 21,0 | 26,2 | 40,1 | 47,0 | ||
| 22,4 | 27,7 | 41,3 | 48,3 | ||
| 23,7 | 29,1 | 42,6 | 49,6 | ||
| 25,0 | 30,6 | 43,8 | 50,9 |
Приложение
Критические значения коэффициента Стьюдента (t-критерия) для различной доверительной вероятности p и числа степеней свободы f:
| f | p | |||||||
| 0.80 | 0.90 | 0.95 | 0.98 | 0.99 | 0.995 | 0.998 | 0.999 | |
| 3.0770 | 6.3130 | 12.7060 | 31.820 | 63.656 | 127.656 | 318.306 | 636.619 | |
| 1.8850 | 2.9200 | 4.3020 | 6.964 | 9.924 | 14.089 | 22.327 | 31.599 | |
| 1.6377 | 2.35340 | 3.182 | 4.540 | 5.840 | 7.458 | 10.214 | 12.924 | |
| 1.5332 | 2.13180 | 2.776 | 3.746 | 4.604 | 5.597 | 7.173 | 8.610 | |
| 1.4759 | 2.01500 | 2.570 | 3.649 | 4.0321 | 4.773 | 5.893 | 6.863 | |
| 1.4390 | 1.943 | 2.4460 | 3.1420 | 3.7070 | 4.316 | 5.2070 | 5.958 | |
| 1.4149 | 1.8946 | 2.3646 | 2.998 | 3.4995 | 4.2293 | 4.785 | 5.4079 | |
| 1.3968 | 1.8596 | 2.3060 | 2.8965 | 3.3554 | 3.832 | 4.5008 | 5.0413 | |
| 1.3830 | 1.8331 | 2.2622 | 2.8214 | 3.2498 | 3.6897 | 4.2968 | 4.780 | |
| 1.3720 | 1.8125 | 2.2281 | 2.7638 | 3.1693 | 3.5814 | 4.1437 | 4.5869 | |
| 1.363 | 1.795 | 2.201 | 2.718 | 3.105 | 3.496 | 4.024 | 4.437 | |
| 1.3562 | 1.7823 | 2.1788 | 2.6810 | 3.0845 | 3.4284 | 3.929 | 4.178 | |
| 1.3502 | 1.7709 | 2.1604 | 2.6503 | 3.1123 | 3.3725 | 3.852 | 4.220 | |
| 1.3450 | 1.7613 | 2.1448 | 2.6245 | 2.976 | 3.3257 | 3.787 | 4.140 | |
| 1.3406 | 1.7530 | 2.1314 | 2.6025 | 2.9467 | 3.2860 | 3.732 | 4.072 | |
| 1.3360 | 1.7450 | 2.1190 | 2.5830 | 2.9200 | 3.2520 | 3.6860 | 4.0150 | |
| 1.3334 | 1.7396 | 2.1098 | 2.5668 | 2.8982 | 3.2224 | 3.6458 | 3.965 | |
| 1.3304 | 1.7341 | 2.1009 | 2.5514 | 2.8784 | 3.1966 | 3.6105 | 3.9216 | |
| 1.3277 | 1.7291 | 2.0930 | 2.5395 | 2.8609 | 3.1737 | 3.5794 | 3.8834 | |
| 1.3253 | 1.7247 | 2.08600 | 2.5280 | 2.8453 | 3.1534 | 3.5518 | 3.8495 | |
| 1.3230 | 1.7200 | 2.2.0790 | 2.5170 | 2.8310 | 3.1350 | 3.5270 | 3.8190 | |
| 1.3212 | 1.7117 | 2.0739 | 2.5083 | 2.8188 | 3.1188 | 3.5050 | 3.7921 | |
| 1.3195 | 1.7139 | 2.0687 | 2.4999 | 2.8073 | 3.1040 | 3.4850 | 3.7676 | |
| 1.3178 | 1.7109 | 2.0639 | 2.4922 | 2.7969 | 3.0905 | 3.4668 | 3.7454 | |
| 1.3163 | 1.7081 | 2.0595 | 2.4851 | 2.7874 | 3.0782 | 3.4502 | 3.7251 | |
| 1.315 | 1.705 | 2.059 | 2.478 | 2.778 | 3.0660 | 3.4360 | 3.7060 | |
| 1.3137 | 1.7033 | 2.0518 | 2.4727 | 2.7707 | 3.0565 | 3.4210 | 3.6896 | |
| 1.3125 | 1.7011 | 2.0484 | 2.4671 | 2.7633 | 3.0469 | 3.4082 | 3.6739 | |
| 1.3114 | 1.6991 | 2.0452 | 2.4620 | 2.7564 | 3.0360 | 3.3962 | 3.8494 | |
| 1.3104 | 1.6973 | 2.0423 | 2.4573 | 2.7500 | 3.0298 | 3.3852 | 3.6460 | |
| 1.3080 | 1.6930 | 2.0360 | 2.4480 | 2.7380 | 3.0140 | 3.3650 | 3.6210 | |
| 1.3070 | 1.6909 | 2.0322 | 2.4411 | 2.7284 | 3.9520 | 3.3479 | 3.6007 | |
| 1.3050 | 1.6883 | 2.0281 | 2.4345 | 2.7195 | 9.490 | 3.3326 | 3.5821 | |
| 1.3042 | 1.6860 | 2.0244 | 2.4286 | 2.7116 | 3.9808 | 3.3190 | 3.5657 | |
| 1.303 | 1.6839 | 2.0211 | 2.4233 | 2.7045 | 3.9712 | 3.3069 | 3.5510 | |
| 1.320 | 1.682 | 2.018 | 2.418 | 2.6980 | 2.6930 | 3.2960 | 3.5370 | |
| 1.301 | 1.6802 | 2.0154 | 2.4141 | 2.6923 | 3.9555 | 3.2861 | 3.5258 | |
| 1.300 | 1.6767 | 2.0129 | 2.4102 | 2.6870 | 3.9488 | 3.2771 | 3.5150 | |
| 1.299 | 1.6772 | 2.0106 | 2.4056 | 2.6822 | 3.9426 | 3.2689 | 3.5051 | |
| 1.298 | 1.6759 | 2.0086 | 2.4033 | 2.6778 | 3.9370 | 3.2614 | 3.4060 | |
| 1.2997 | 1.673 | 2.0040 | 2.3960 | 2.6680 | 2.9240 | 3.2560 | 3.4760 | |
| 1.2958 | 1.6706 | 2.0003 | 2.3901 | 2.6603 | 3.9146 | 3.2317 | 3.4602 | |
| 1.2947 | 1.6686 | 1.997 | 2.3851 | 2.6536 | 3.9060 | 3.2204 | 3.4466 | |
| 1.2938 | 1.6689 | 1.9944 | 2.3808 | 2.6479 | 3.8987 | 3.2108 | 3.4350 | |
| 1.2820 | 1.6640 | 1.9900 | 2.3730 | 2.6380 | 2.8870 | 3.1950 | 3.4160 | |
| 1.2910 | 1.6620 | 1.9867 | 2.3885 | 2.6316 | 2.8779 | 3.1833 | 3.4019 | |
| 1.2901 | 1.6602 | 1.9840 | 2.3642 | 2.6259 | 2.8707 | 3.1737 | 3.3905 | |
| 1.2888 | 1.6577 | 1.9719 | 2.3578 | 2.6174 | 2.8598 | 3.1595 | 3.3735 | |
| 1.2872 | 1.6551 | 1.9759 | 2.3515 | 2.6090 | 2.8482 | 3.1455 | 3.3566 | |
| 1.2858 | 1.6525 | 1.9719 | 2.3451 | 2.6006 | 2.8385 | 3.1315 | 3.3398 | |
| 1.2849 | 1.6510 | 1.9695 | 2.3414 | 2.5966 | 2.8222 | 3.1232 | 3.3299 | |
| 1.2844 | 1.6499 | 1.9679 | 2.3388 | 2.5923 | 2.8279 | 3.1176 | 3.3233 | |
| 1.2837 | 1.6487 | 1.9659 | 2.3357 | 2.5882 | 2.8227 | 3.1107 | 3.3150 | |
| 1.2830 | 1.6470 | 1.9640 | 2.3330 | 2.7850 | 2.8190 | 3.1060 | 3.3100 |
Литература.
4. Налимов В. В., Чернова H. А., Статистические методы планирования экстремальных экспериментов, M., 1965;
5. Хикс Ч. Р., Основные принципы планирования эксперимента, пер. с англ., M., 1967;
6. Маркова E. В., Лисенков A. H., Планирование эксперимента в условиях неоднородностей, M., 1973;
7. Зедгинидзе И. Г., Планирование эксперимента для исследования многокомпонентных систем, M., 1976;
8. Адлер Ю. П., Маркова E. Б., Грановский Ю.В., Планирование эксперимента при поиске оптимальных условий, 2 изд., M., 1976;
9. Рузинов Л. П., Слободчикова P. И., Планирование эксперимента в химии и химической технологии, M., 1980;
10. Новик Ф. С., Арсов Я. Б., Оптимизация процессов технологии металлов методами планирования экспериментов, М.-София, 1980;
11. Ахназарова С. Л., Кафаров В. В., Методы оптимизации эксперимента в химической технологии, 2 изд., M., 1985.
12. Дёрфель К., Статистика в аналитической химии, пер.с нем., под ред. Адлера Ю.П., М., «Мир», 1994.
13. Богуцкая Г.А., Тетерятник О.В. Вища математика і математична статистика, Запоріжжя, 2007.
14. Халафян А.А. STATISTICA 6. Статистический анализ данных. М., Издательство БИНОМ, 2007
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 789; Нарушение авторских прав?; Мы поможем в написании вашей работы!