КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Содержимое содержимое
|
|
|
|
Рис 2.3
Универсальный набор команд явно отражал как иерархию, так и адресацию памяти, включая в себя набор функционально одинаковых команд с различным расположением операндов. Существовали команды формата «регистр-регистр», «регистр-память», и «память-память», где для адресации операнда в памяти необходимо было указать явное смещение и номера двух регистров общего назначения. Наличие разноформатных команд существенно увеличивало общий набор команд процессора (150-200 машинных команд).
Управление процессором осуществлялось через регистр адреса команды, который содержал ряд дополнительных полей. Например в процессоре IBM 370/165 этот регистр назывался словом состояния программы (PSW) и имел длину в 64 бита. Регистр содержал следующую информацию:
- адрес следующей команды в оперативной памяти;
- результат последней команды сравнения;
- коды состояний процессора;
- ключ защиты памяти.
2.4 Обработка особых ситуаций и прерывания
Особые ситуации, возникающие при работе процессора, требуют специальной обработки со стороны операционной системы, т.е. некоторым образом выполнение текущей программы должно быть прервано и ресурс процессора должен быть предоставлен специальным программам операционной системы. Для обработки таких ситуаций в классической архитектуре был предложен специальный механизм, который получил название прерываний. Для иллюстрации разделения прерываний по типам и механизма их обработки рассмотрим обработку особых ситуаций, принятую в семействе ЭВМ IBM 360/370.
При разработке этого семейства ЭВМ были выделены следующие типы прерываний:
- программные прерывания - особые ситуации при выполнении команд (деление на ноль, переполнение порядка, потеря значимости и т.д.);
- прерывания ввода/вывода - особые ситуации, возникающие при нормальном или ненормальном завершении операций ввода/вывода;
-прерывания от часов и интервального таймера;
-прерывания от схем контроля - особые ситуации, когда специальные схемы, контролирующие работу процессора, обнаруживали ошибки аппаратуры;
- прерывания по обращению к операционной системе - прерывания, инициируемые обрабатываемой программой, для выполнения функций, находящихся в ведении операционной системы (прерывания по обращению к супервизору).
Механизм обработки прерываний включал в себя загрузку пар PSW для каждого типа прерываний при загрузке операционной системы. Новое PSW прерывания содержало адрес обработчика прерываний данного типа внутри операционной системы. При возникновении прерывания аппаратно производилась смена PSW, как это показано на рис 2.4, что и приводило к запуску обработчика прерываний. Старое PSW было необходимо для возврата из обработчика прерываний в прерванную программу.
Схема обработки прерываний в IBM 360/370
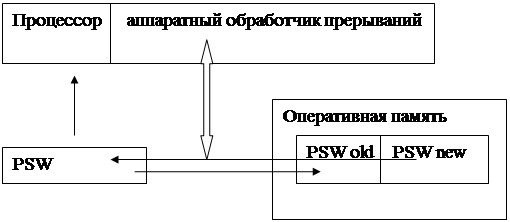
Рис 2.4
3. СТЕКОВЫЕ ПРОЦЕССОРЫ
3.1 Этапы выполнения команды в фон Неймановском процессоре
Для понимания принципов, на которых основывается идеология стекового процессора необходимо более подробно рассмотреть этапы выполнения команд в классической фон - Неймановской архитектуре и ряд узких мест, приводящих к определенной потере времени при выполнении последовательности операций.
Можно выделить следующие этапы выполнения команды в классической фон - Неймановской архитектуре:
1) выборка устройством управления команды из ОП (или из кэш памяти) в регистр команд;
2) модификация адреса в регистре команд на длину выбранной команды;
3) обработка кода операции - коммутация АЛУ на соответствующую микропрограмму или операционную схему;
4) коммутация регистров и АЛУ в соответствии с информацией команды;
5) вычисление адреса операнда в ОП;
6) выборка операнда из ОП в АЛУ;
7) выполнение команды процессором (АЛУ);
8) обработка результата выполнения команды - запись результата.
Схема взаимодействия регистров процессора и АЛУ представлена на рис 3.1:
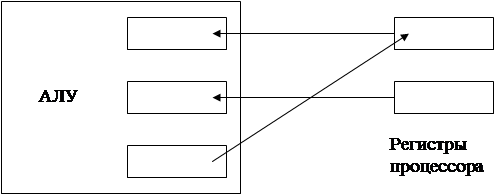
Схема взаимодействия регистров процессора и АЛУ
Рис 3.1
3.2 Архитектурные особенности стекового процессора
 |
Основной идеей разработчиков стекового процессора был отказ от программно адресуемых регистров в пользу аппаратного стека. Стек представляет собой блок памяти с двумя фиксированными операциями - операцией помещения информации в стек, при этом новая информация размещается вверху стека, а все ранее хранимые элементы проталкиваются вниз, и операцией выборки из стека, при которой верхний элемент стека выталкивается и передается на обработку, а все остальные элементы продвигаются на единицу вверх. Таким образом, непосредственно доступным является только верхний элемент стека. Схема стека приведена на рис 3.2.
Упрощенная схема стека
Рис 3.2
Прямое использование стека вместо регистров приводит к структуре, в которой остаются внутренние регистры АЛУ. Эта структура обладает тем недостатком, что остаются операции пересылки операндов в АЛУ, приводящие к увеличению времени выполнения операции. Структура простого стекового процессора приведена на рис 3.3
Структура простого стекового процессора
 |
Рис 3.3
Очевидное усовершенствование такой структуры связано с использованием верхних элементов стека в качестве регистров АЛУ. Таким образом, мы приходим к структуре стекового процессора с прямой коммутацией, работающего по следующему принципу:
1) выполнение команды, операндами которой всегда являются верхний и непосредственно следующий за ним элементы стека (для бинарных операций);
2) формируемый в АЛУ результат пересылается по месту операнда №2 в стеке;
3) стек продвигается на один элемент вверх - тем самым результат предыдущей команды автоматически становится операндом следующей команды.
Отметим, что в этом случае АЛУ работает не с чисто стековой структурой, так как доступными (коммутированными) являются два элемента стека.
Отметим положительные особенности данной архитектуры:
- отсутствие этапа коммутации АЛУ с операндами приводит к сокращению времени выполнения команды;
- прямая передача результатов операций от одной к другой через верхний элемент стека позволяет упростить подготовку следующей команды;
- короткие команды без операндов, так как положение операндов фиксировано в двух верхних элементах стека, приводят к более короткому машинному коду программы.
Схема стекового процессора с прямой коммутацией приведена на рис 3.4
 |
Схема стекового процессора с прямой коммутацией
Рис 3.4
Специфика стекового процессора заключается, прежде всего, в необходимости специальных подходов к программированию, связанных с представлением арифметических выражений в так называемой польской постфиксной записи и проблеме хранения промежуточных результатов, которая решается введением специальной команды, дублирующей содержимое верхнего элемента стека вниз.
3.3 Операции с оперативной памятью
В системе команд стекового процессора должны быть предусмотрены специальные команды, осуществляющие загрузку стека содержимым по адресу ОП и выталкивание элемента стека в ОП. Такие команды будут содержать в той или иной форме адреса ОП, которые в дальнейшем будут для простоты представляться символическими именами.
Будем обозначать операции «из ОП в стек» и «из стека в ОП» с учетом символических адресов следующим образом:
- А¯ - содержимое по адресу А помещается в стек, все остальные элементы стека проталкиваются вниз;
- Y - содержимое верхнего элемента стека помещается в память по адресу Y, стек продвигается на один элемент вверх.

Реализация операций перемещения элементов стека должна быть достаточна быстрой по времени, при этом поэлементная перезапись, как это показано слева на рис 3.5 не обеспечивает временных характеристик. Для реализации быстрого стека применяется идея регистров параллельного переноса, как это показано справа на рис 3.5:
Схема проталкивания элементов стека
Рис 3.5
3.4 Программирование на стековом процессоре
Рассмотрим несколько простых примеров вычисления арифметических выражений с учетом особенностей архитектуры стекового процессора. В дополнение к командам работы с памятью введем обозначение команд арифметических операций в виде знаков операций и унарную операцию 1/a для обозначения операции вычисления обратной величины.
1. Выражение C=A+B
Фрагмент программы A¯, B¯,+,C
2. Выражение D=A+B+C
Фрагмент программы A¯, B¯, +, C¯, +, D
Или A¯, B¯, D¯, +, +, C
3. Выражение Y=((A+B)*E)/X
Фрагмент программы A¯, B¯, +, E¯, *, X¯, 1/a, *, Y
Или X¯, E¯, B¯, A¯, +, *, /, Y
3.5 Замечания по реализации
Первые реализации стековых процессоров относятся ко второму поколению ЭВМ, т.е. к началу 1960-х годов. Стековую идею впервые широко использовала фирма Burroughs, начиная с машины В 5000 и далее в машинах серии В 6000 и В 6600, из отечественных разработок следует упомянуть машину БЭСМ - 6 с одними из лучших показателей производительности в своем классе.
В настоящее время идеи стековой архитектуры используются для построения сопроцессоров с плавающей точкой (математических сопроцессоров) в процессорах Intel и AMD.
Отметим еще одну идею, связанную с использованием стека - стековую выборку команд. Идея предполагает реализацию быстрого буфера команд в устройстве управления в виде стека, в этом случае в УУ явно отсутствует регистр адреса команды, так как очередная команда выбирается из верхнего элемента стека. Возникающая очевидно при этом проблема выполнения команды перехода по адресу может быть решена с использованием циклического стека с адресацией.
4. КОНВЕЙЕРНЫЕ ПРОЦЕССОРЫ
4.1 Предпосылки создания конвейера данных
Общая идея конвейера связана с разбиением некоторого процесса обработки объектов на независимые этапы и организацией параллельного выполнения во времени различных этапов обработки различных объектов, передвигающихся по конвейеру от одного этапа к другому. Поэтому основой разработки конвейера является разбиение процесса на независимые этапы. Рассмотрим такое разбиение на примере машинной команды умножения чисел с плавающей точкой.
 |
Формат хранения действительных чисел - чисел с плавающей точкой (FP) представлен на рис 4.1:
Формат хранения действительных чисел (FP)
Рис 4.1
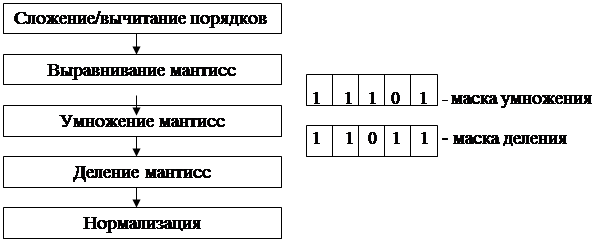
Этапы выполнения машинной команды умножения:
1) Сложение порядков;
2) Нормализация мантисс (приведение мантисс к виду 0,1хххх);
3) Умножение мантисс;
4) Нормализация результата.
Таким образом, команда умножения может быть разделена на четыре этапа, которые могут быть реализованы аппаратно в виде четырех операционных блоков (сегментов), как это показано на рис 4.2
 |
Операционные блоки для машинной команды умножения действительных чисел
Рис 4.2
4.2 Структура конвейера данных
Создание конвейера предполагает выполнение следующих действий:
1) Деление машиной команды на этапы;
2) Аппаратная реализация этапов в виде конвейерных блоков (сегментов);
3) Создание входных / выходных регистров блоков для передачи результатов.
Таким образом каждый сегмент конвейера имеет структуру, показанную на рис 4.3, где ОР1 и ОР 2 - входные и выходные операнды блока (регистры), а R - поле результата

Структура конвейерного сегмента
Рис 4.3
Последовательно соединяя конвейерные блоки (сегменты) в порядке следования этапов выполнения машинной команды мы получаем конвейер данной машинной операции для обработки потока данных, в связи с чем такие конвейеры получили название конвейеров данных.
4.3 Сокращение времени при использовании конвейера данных
Пусть при конвейерной обработке машинная команда, как показано на рис. 4.2, разбивается на несколько (допустим, n) блоков, и каждая пара операндов последовательно обрабатывается в каждом таком блоке, начиная с первого по n -й, причем, как только одна пара операндов заканчивает обрабатываться на некотором операционном блоке, то этот блок начинает обрабатывать пару другую пару операндов, переданных с предыдущего блока. Таким образом, все блоки операционного конвейера работают одновременно и выполняют n разных этапов обработки для n разных пар операндов. Допустим, что конвейер спроектирован таким образом, что время прохождения одной пары операндов в обычном АЛУ и конвейере одинаково и равно Т, а число пар операндов, которые можно последовательно пропускать через конвейер, достаточно велико и равно N. В таком случае в исходном операционном блоке АЛУ на выполнение одной операции потребуется время Т, но если используется n-звенный конвейер, то на обработку N операций потребуется время (n + N) • (Т/n).
При этом на одну операцию потребуется время ((n + N)*T)/(n*N). Если отношение N/n достаточно велико, то это время приближается к Т/n, т. е. скорость вычислений возрастает приблизительно в n раз, где n -количество блоков или сегментов конвейера.
4.4 Конвейер команд
В случае, если процессор содержит конвейер данных, то скорость подачи очередной команды из УУ на конвейер должна быть согласована со скоростью конвейера данных. Таким образом, необходима синхронизация конвейера данных и устройства управления процессором.
Реально при N сегментном конвейере необходимо подавать данные на первый блок конвейера данных в N раз быстрее, чем при обычной реализации процессора. При фиксированной тактовой частоте реальным единственным решением данной проблемы является построение конвейера команд. По аналогии с конвейером данных в устройстве управления выделяются самостоятельные этапы подготовки команды к выполнению, они реализуются аппаратно в виде конвейерных блоков, и через эти блоки пропускается поток команд.
Например, в устройстве управления можно выделить следующие конвейерные блоки (сегменты):
1) выборка команды по адресу из ОП (или из КЭШ памяти);
2) дешифрация и обработка кода операции;
3) выборка первого операнда;
4) выборка второго операнда.
Таким образом, мы получаем конвейер команд, позволяющий при определенных условиях согласовать скорость конвейера данных и устройства управления.
4.5 Многооперационные конвейеры
При реализации идеи конвейерной обработки для различных операций процессора возможны два следующих подхода, которые называются конвейером в ширину и конвейером в глубину.
 |
Конвейер в ширину предполагает аппаратную реализацию каждой операции в виде набора конвейерных сегментов. Поскольку некоторые этапы выполнения разных машинных команд совпадают (например - нормализация), то такая реализация является аппаратно избыточной, но позволяет повысить наблюдаемую скорость процессора для рядя специфических задач. Структура конвейера в ширину приведена на рис 4.4
Структура конвейера в ширину
Рис 4.4
Конвейер в глубину предполагаетпоследовательное соединение конвейерных сегментов в один «глубокий» конвейер, при этом вместе с операндами некоторой команды устройство управления передает на такой конвейер значение регистра маски, содержащего единицы в тех позициях, которые соответствуют необходимым для данной операции конвейерными сегментам.
Пример конвейера в глубину фирмы Texas Instruments в системе ASC приведен на рис 4.5. В этой структуре отсутствует дублирование конвейерных блоков, но затрачивается время на передачу операндов через блоки, неиспользуемые в данной операции.
 |
Конвейер в глубину
Рис. 4.5
4.6 Проблемы конвейерных процессоров:
a) Стоимость аппаратных средств. Стоимость аппаратной реализации растёт за счёт конвейерных блоков, входных и выходных регистров блоков, особенно для конвейеров в ширину и конвейера команд;
b) Обработка особых ситуаций. На одном из конвейерных сегментов возникает ситуация, аналогичная программному прерыванию в фон - Неймановском процессоре - например - результат сложения порядков превышает разрядную сетку числа. При этом возникает проблема остановки конвейера, и, следовательно, обработка особых ситуаций в конвейерном процессоре будет более сложной.
c) Синхронизация. Устройство управления должно выполнять синхронизацию конвейерных блоков, конвейера команд и конвейера данных.
4.7 Особенности программирования конвейерных процессоров.
Собственно наличие аппаратно реализованного конвейера данных и конвейера команд еще не означает значительного увеличения наблюдаемой скорости работы процессора из-за наличия ряда условий, при которых конвейер данных может быть нормально загружен - это отсутствие связей по данным и связей по управлению в потоке конвейеризируемых команд
Связанные по данным операции - это ситуация, при которой результат предыдущей (не обязательно непосредственно, но в рамках глубины конвейера) команды является операндом следующей:
Y D*C;
……….
Z Y *E:
В этой ситуации команда умножения Y *E должна быть задержана до выхода значения Y из конвейера умножения, как результата умножения D*C.
Таким образом, необходимы особые подходы к программированию конвейерных процессоров, которые мы продемонстрируем на следующих двух задачах:
1. Задача суммирования элементов массива:
Приемлемый для конвейера алгоритм должен обеспечить поток несвязанных операндов сложения, что приводит к алгоритму попарного сложения, схема которого в виде бинарного дерева сложений глубиной log2N приведена на рис 4.6 справа.
Схема попарного сложения элементов массива
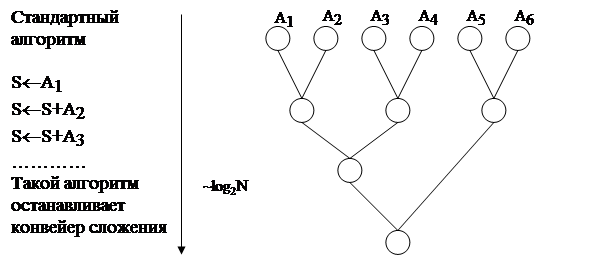
Рис 4.6
2. Задача умножения матрицы на вектор
Умножение ` А * `Х = В
Прямая схема умножения:
b1=x1*a11+x2*a12+x3*a13+…..
b2=x1*a21+x2*a22+x3*a23+…..
b3=x1*a31+x2*a32+x3*a33+…..
Если мы реализуем алгоритм умножения по вышеприведенной схеме, то, несмотря на наличие независимых пар по умножению, мы сталкиваемся с необходимостью добавления очередного результата умножения в B[i], что приводит к задержке конвейера сложения.
Оптимальный для конвейера алгоритм связан с переворотом порядка умножения на 90° - т.е. мы умножаем вектор Х не на строки матрицы А, а на столбцы матрицы и добавляем полученные произведения ко всем элементам вектора В. При этом добавление происходит параллельно во все элементы столбца, и следовательно может быть успешно конвейеризировано. Схема такого умножения приведена на рис 4.7
 |
Схема конвейерно - оптимального умножения матрицы на вектор
Рис. 4.7
4.8 Замечания по реализации
Необходимость решать крупные вычислительные задачи с более высокой скоростью привела в 60-е годы к необходимости разработки ЭВМ с высокоскоростной параллельной обработкой данных. К первым машинам такого типа относятся LARC фирмы UNIVAC и IBM 7030, в которых впервые был применен принцип конвейера команд.
Что касается области конвейерных суперкомпьютеров, то здесь одной из первых была фирма Control Dada Corporation (CDC). В. 1964 г. была создана ЭВМ CDC - 6600, а в 1969 г. - CDС - 7600, которые объединились в семейство CYBER. Конвейерные принципы были использованы так же в машинах STAR 100 фирмы CDC и ASC формы Texas Instuments, наиболее полно конвейерные принципы нашли свое отражение в архитектуре CRAY процессора.
5. CRAY - ПРОЦЕССОР
5.1 Предпосылки создания суперкомпьютеров
a) задачи вычислительной математики и в особенности векторные и матричные задачи большой размерности с трудоемкостью порядка нескольких MY (1MY=1 миллион операций в секунду в течении года);
b) задачи реального времени с большой трудоёмкостью (например - обсчет информации, поступающей за 1 оборот локатора), требующие повышенной надежности аппаратных средств;
c) задачи моделирования сложных объектов и систем (например - задачи моделирования в области ядерной физики).
5.2 Недостатки фон Неймановской архитектуры
a) Смешанная адресация в большинстве команд:
Команда «Сложить содержимое регистра и содержимое по адресу оперативной памяти» приводит к:
- выборке команды из ОП;
- выборке операндов из ОП.
b) Векторные операции - реализация циклами:
|
|
|
|
|
Дата добавления: 2015-04-25; Просмотров: 385; Нарушение авторских прав?; Мы поможем в написании вашей работы!