КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Буферизация команд 1 страница
|
|
|
|
В состав центрального процессора машины Сгау-1 входит регистровая буферная память значительного объема для промежуточного хранения команд программы, исполняемой в данный момент. Эта буферная память состоит из четырех секций, каждая по 16 слов. Последовательность команд программы предварительно поступает в этот буфер. Если она содержит условный переход, то в буфере накапливаются также команды, относящиеся к последовательности, на которую возможен этот условный переход. Буфер команд является средством ускорения работы устройства управления, минимизируя время ожидания чтения команд из главной памяти.
5.4 Общая структура и состав процессора CRAY.
В состав центрального процессора Сгау-1 входят:
• главная (оперативная) память, разделенная на 16 независимых по обращению блоков;
• регистровая память, состоящая из пяти групп быстрых регистров, предназначенных для хранения и преобразования адресов и данных;
• функциональные модули АЛУ, в состав которых входят 12 параллельно работающих конвейерных блоков, служащих для выполнения арифметических и логических операций;
• устройство управления (УУ), выполняющее функции управления параллельной работой модулей, блоков и устройств центрального процессора.
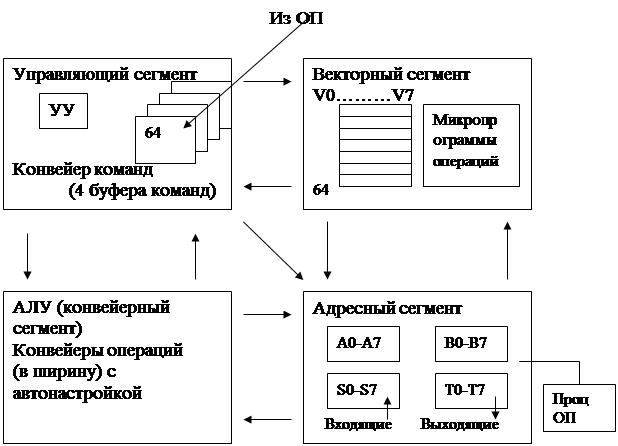
Обобщенная структура процессора приведена на рис 5.3
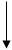 |
Обобщенная структура Cray процессора
Рис 5.3
5.5 Производительность и области применения
CRAY процессор разрабатывался как специальный процессор с высокой производительностью для решения научно-технических задач. Это предопределило отсутствие развитых средств динамического перераспределения адресов, аппаратное базирование и наличие простых методов обработки прерываний и зашиты памяти.
Совокупность целого ряда оригинальных технических решений (регистровый ассемблер, прозрачная память, векторные регистры) и ориентация на максимальное повышение производительности позволили получить ощутимые результаты в области «научных» вычислений. В 1976 году процессор CRAY-1 был одним из наиболее быстрых процессоров - Cray-конвейерный сегмент FP имел цикл 12,5 нс. ~ 85 MFOPS или 250 MIPS
MIPS (Million Instructions Per Second)-Миллион операций в секунду
MFLOPS (Million Floating Point Operation Per Second)- миллион операций с действительными числами в секунду (плавающая точка)
6. ПРОЦЕССОР ПЕРЕСЫЛОК
6.1 Иерархия памяти в классической архитектуре
Классические принципы построения процессора предусматривают наличие развитой иерархии памяти, в которой внутренние регистры АЛУ не адресуются программой, быстрая память процессора представлена регистрами общего назначения с собственной адресацией, а выборка команд и данных происходит из оперативной памяти, имеющей сквозную адресацию. Схематично эта иерархия представлена на рис 6.1. В неймановских машинах пересылки данных между процессором и памятью выполняются довольно часто и поочередно, а так как ширина канала пересылки мала, то здесь образуется
|
Фон - Неймановская иерархия памяти
Рис 6.1
С другой стороны иерархия памяти приводит к тому, что в машинной команде применяется много разных способов адресации, при этом разные уровни иерархии рассматриваются логически как разные устройства.
6.2 Организация памяти в процессоре пересылок
Основной идеей разработчиков процессора пересылок был отказ от классической иерархии памяти в пользу логического объединения адресного пространства. Эта идея получила название сквозной адресации. При этом разная память может представлять собой физически различные устройства, но с точки зрения устройства управления процессором - это единое адресное пространство, имеющее единый способ адресации в машинной команде и каждый элемент такой сквозной памяти является программно доступным.
Таким образом, с точки зрения машинной команды можно единым образом адресовать и обращаться, как к специальным регистрам управления процессором, внутренним регистрам схем выполнения машинных команд АЛУ, регистрам общего назначения (РОН), так и к словам оперативной памяти (ОП). Схема сквозного адресного пространства представлена на рис 6.2.
  |
Сквозное адресное пространство в процессоре пересылок
Рис 6.2
Такой подход к организации памяти порождает и специфический подход к организации работы процессора и механизму выполнения машинных команд.
6.3 Организация процессора пересылок
6.3.1 Адресная фиксация схем исполнения машинных команд
С учетом механизма сквозной адресации следующей идеей разработчиков было распределение схем выполнения машинных команд АЛУ со своими собственными регистрами операндов и результатов по фиксированным адресам сквозной памяти.
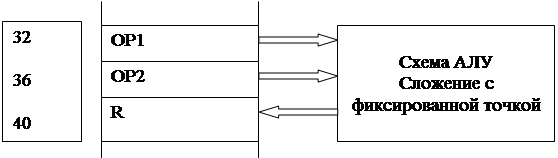 |
Адресная фиксация схемы АЛУ
Рис 6.3
Таким образом, например, схема сложения чисел с фиксированной точкой, обладающая собственными регистрами двух операндов и регистром результата оказывалась фиксированной в определенных адресах сквозной памяти, а именно в тех, которые назначались для регистров этой схемы. Вариант такой фиксации схемы АЛУ приведен на рис 6.3.
Таким образом область сквозного адресного пространства, соответствующая входным/выходным регистрам схем АЛУ оказывалась жестко разделена и закреплена за соответствующими схемами, и следовательно за машинными командами.
6.3.2 Механизм запуска машинной команды

Механизм запуска машинной команды предусматривал пересылку операндов в соответствующие входные регистры исполнительной схемы, что в принятой системе сквозной адресации реализовывалось пересылкой содержимого из одного слова памяти в другое. Именно этот механизм и дал название данной архитектуре - «процессор пересылок». Поскольку каждая машинная команда оказывалась жестко закрепленной за фиксированными адресами сквозной памяти, то запуск той, или иной операции был связан только с адресами расположения соответствующих входных регистров - процессор пересылок не имеет поля кода машинной команды, и следовательно устройство управления процессором выполняет только одну команду - команду пересылки слова. Механизм запуска машинной команды проиллюстрирован на рис 6.4
Запуск машинной команды в процессоре пересылок
Рис 6.4
Для синхронизации процесса выполнения машинных команд внутри схем АЛУ предусматривались биты готовности операндов, которые устанавливались в «1» после пересылки операнда команды. Наличие всех необходимых операндов запускало по схеме «И» выполнение команды, после чего результат помещался схемой в выходной регистр, а биты готовности операндов сбрасывались в «0». Во время выполнения очередной команды УУ задерживало следующую команду пересылки до появления результата в выходном регистре.
6.4 Пример программы в процессоре пересылок
Рассмотрим фрагмент программы процессора пересылок для вычисления следующего арифметического выражения, в рамках стандартного понимания символических имен:
Y = ((a+b)*(c+d))
Будем считать, что схемы АЛУ для операций с плавающей точкой фиксированы на следующие адреса сквозной памяти (операнд 1, операнд 2, результат), а сами операнды имеют длину в 4 байта:
Сложение - 64, 68, 72;
Умножение - 76, 80, 84;
Фрагмент программы (операция пересылки справа на лево):
64, a; (пересылка первого операнда для сложения)
68, b; (пересылка второго операнда для сложения)
(выполнение команды сложения - результат по адресу 72)
64, 76; (пересылка результата, как операнда для умножения)
64, c; (пересылка первого операнда для сложения)
68, d; (пересылка второго операнда для сложения)
(выполнение команды сложения - результат по адресу 72)
64, 80; (пересылка результата, как операнда для умножения)
(выполнение команды умножения - результат по адресу 84)
Y, 84; (пересылка результата в оперативную память)
6.5 Реализация перехода по адресу и сравнения
Реализация операции сравнения в процессоре пересылок аналогично обычным арифметическим операциям - схемы сравнения фиксированы на определенные адреса сквозной памяти, но в поле результата схема помещает «0» или «1», в зависимости от результата сравнения операндов. Эта реализацию проиллюстрирована на рис 6.5 слева.
Более интересно реализован механизм выполнения команды перехода по адресу. Регистр адреса команды УУ так же является словом в едином адресном пространстве (и следовательно доступен программисту!) и расположен по адресу «0». По адресу «4» расположено поле смещения, которое или вычисляется компилятором, и следовательно расположено в области загруженной программы, или вычисляется в программе. Со словами по адресам «0», «4» и «8» коммутирована схема целочисленного сложения. При установке битов готовности операндов, т. е. после пересылки смещения и результата сравнения, эта схема выполняет сложение смещения и текущего адреса команды, при условии, что слово по адресу «8» содержит «1», т.е. при истинности результата сравнения - рис 6.5 справа. Поскольку это приводит к модификации текущего адреса команды, то тем самым процессор выполняет переход на другую команду в программе.

Реализация сравнения и перехода по адресу в процессоре пересылок
Рис 6.5
6.6 Замечания по реализации процессора пересылок
Основным достоинством данной архитектуры является независимость устройства управления от набора машинных команд и возможность универсально расширять этот набор путем включения регистров исполнительной схемы команды в сквозную память процессора. Недостатки архитектуры связаны с большим объемом пересылок данных, однако определенная часть этих пересылок - пересылки между регистрами схем АЛУ. Очевидно, что должны быть приняты определенные решения по гибкой адресации операндов ОП, что приводит к введению регистров базы и индекса.
Эта архитектура нашла свое применение в ряде специализированных процессоров, например в TMS 320 - процессоре обработки сигналов.
7. АРХИТЕКТУРЫ ПРОЦЕССОРОВ
И ФОРМАТЫ ДАННЫХ
7.1. Процессоры с универсальным набором команд
В связи с необходимостью решения различных прикладных задач на ЭВМ общего назначения, уже начиная с машин второго поколения отчетливо наметилась тенденция к созданию универсального набора команд. Такой универсальный набор охватывал как разнообразные форматы данных, т.е. количество занимаемых объектом битов, так и различные типы данных, т.е. внутреннюю структуру формата данных. Наиболее широко используемые в рамках универсальных ЭВМ форматы и типы приведены в таб. 7.1.
| Форматы | Типы |
| ® полуслово | числа с фиксированной точкой числа с плавающей точкой числа в двоично - десятичном представлении |
| ® слово | |
| ® двойное слово | |
| ® длинное слово |
Таблица 7.1 Форматы и типы данных
Идея универсального набора команд предполагала самостоятельную реализацию одинаковой обработки, например сложения, для разных форматов и типов в виде отдельных машинных команд. Таким образом возникало несколько машинных команд (до 10 и более) для одной операции обработки, в результате чего общий набор машинных команд имел порядок 150 - 200.
Такие процессоры получили название «CISC процессоры», т.е. процессоры с универсальным или общим набором команд.
7.2 RISC – процессоры
Для быстрого выполнения программы, написанной на языке высокого уровня, не нужны сложные машинные команды - гораздо более важно сократить время выполнения наиболее часто используемых команд. Этот принцип был положен в основу RISC-архитектуры, которая представляет собой улучшенный вариант неймановской архитектуры. Благодаря сокращению набора команд упрощаются аппаратные схемы, а значит, обеспечивается оптимизация выполнения часто используемых команд. Кроме того, за счет применения большого числа регистров уменьшается частота (число) доступов к памяти, что также позволяет повысить скорость выполнения команды.
Таким образом основная идея RISC процессоров – малый фиксированный набор быстрых команды позволяет не только резко сократить набор машинных команд, отметим, что сокращение до 32 команд сокращает так же до 5 битов длину кода операции, но и сократить набор схем, реализующих команды, что позволяет при той же степени интеграции СБИС увеличить количество регистров и объем кэш-памяти.
Типичные представители этих машин: компьютер RISC Калифорнийского университета в Беркли, IBM 801, MIPS Станфордского университета, μ3L Университета шт. Юта, RIDGE 32 - фирмы Midge, Pyramid 90X фирмы Pyramid и др. RISC-архитектуру имеет и транспьютер фирмы «Инмос» - 32-разрядный процессор, спроектированный с оптимальным набором команд, позволяющим использовать язык высокого уровня Оккам.
7.3 Теговые машины
Одним из факторов, усложняющих разработку программного обеспечения, является наличие большого различия между понятиями операций и их объектов на языке программирования высокого уровня и понятиями операций и их объектов, определяемыми архитектурой компьютера. Это отличие носит название семантического разрыва. Иначе говоря, если на языке высокого уровня можно описать различные операции и типы данных, то в неймановской архитектуре разницы между программами и данными нет, как нет и разницы между типами данных. Это обстоятельство тяжелым бременем ложится на плечи программиста при составлении программы. И впоследствии оно является причиной усложнения отладки программы. Из-за отсутствия различий в типах данных и между программами и данными нельзя обнаружить, была ли ошибка связана с выполнением команды или с обращением к данным. Нельзя также обнаружить, выполняются ли данные в качестве команды или что к команде осуществляется обращение, как к данным.
Для решения этой проблемы Илифф предложил с помощью некоторого алгоритма добавлять ко всем данным информацию, необходимую для того, чтобы идентифицировать их как данные, использовать вместо линейного адресного пространства памяти структурированное пространство и добавлять к каждому элементу памяти информацию, показывающую атрибут этого элемента. Эта дополнительная информация получила название «тег». Машины, основанные на этом принципе, называют теговыми машинами. Так, различные типы данных характеризуются своими тегами, а однотипные команды, отличающиеся только типами операндов, никак не различаются. Например, программисту нет необходимости различать команды ADD (сложения) с плавающей и фиксированной запятой, как в CISC процессорах: машина это сделает автоматически, проверив типы операндов. В случае обращения с массивами данных добавляется такая теговая информация, как длина, ширина массива, индексы, а выход за пределы массива автоматически контролируется машиной при обращении к данным.
Майерс предложил проект SWARD - машины, в которой идеи теговых машин получили свое дальнейшее развитие.
В SWARD-машине данные представлены структурным элементом, называемым ячейкой. На рис. 7.1 приведен пример ячейки. Каждая ячейка состоит из поля тега и поля данных. Численные значения представлены в двоично-десятичном коде, и один разряд десятичного числа представлен четырьмя двоичными разрядами (битами). Память разбита на 4-разрядные единицы, которые называются признаками. Разрядность данных, указанных в поле тега, выражается числом признаков. Положительный знак числа выражается кодом 0000, отрицательный - 0001. Если используются массивы данных, то в поле тега указываются размерность массива, тип ячейки элемента массива, длина каждого измерения. Если элементом массива является целое число, то к типу ячейки после 1111 добавляется информация о длине числа. В SWARD-машине теговая информация используется не только применительно к данным, но и применительно к программным модулям.
 |
Представление данных в теговых машинах
Рис 7.1
7.4 Гарвардская архитектура
Еще одна архитектурная идея, связанная с преодолением проблемы семантического разрыва, но теперь в части неразличимости программы и данных, основывается на физическом разделении оперативной памяти на два независимых блока с собственными устройствами управления. Предложенная в Гарвардском университете она получила название «Гарвардская архитектура». Схема такого процессора приведена на рис 7.2
Схема процессора с гарвардской архитектурой
 |
Рис 7.2
Два блока оперативной памяти для хранения программы и данных могут работать параллельно, что важно для конвейерной организации самого процессора. Для предотвращения возможности модификации программы во время выполнения (самомодифицируемые программы), что иногда активно использовалось при программировании в фон-неймановских процессорах, аппаратно запрещена операция записи в область машинного кода.
Такой подход к организации памяти широко используется в настоящее время в микропроцессорах, и в процессорах специального назначения, где чрезвычайно важно сохранить целостность программы, даже при возникновении аппаратной ошибки.
8. ПОДХОДЫ К ОРГАНИЗАЦИИ ВЫЧИСЛИТЕЛЬНОГО ПРОЦЕССА И ПОТОКОВЫЕ МАШИНЫ
Архитектура вычислительной машины во многом определяется принятой моделью обработки данных, т.е. подходом или принципом, в соответствии с которым организуется процесс вычислений. На современном этапе можно выделить следующие три основных подхода к организации вычислительного процесса:
8.1 Процедурное программирование.
Большинство вычислительных машин, существующих в настоящее время, относятся к так называемым неймановским ЭВМ, т. е. вычисления выполняются на основе принципа, который определил Дж. фон Нейман, называемым принципом процедурного программирования. Этот принцип требует, чтобы в процессоре было устройство управления, содержащее программный счетчик, указывающий текущую команду, чтобы команды (указанные программным счетчиком) последовательно считывались и декодировались по заранее заданному в виде программы алгоритму вычислений, вычисления выполнялись в операционном устройстве и данные последовательно перезаписывались в запоминающее устройство.
Особенности принципа работы машин неймановского типа можно определить следующим образом: - последовательное выполнение программы при централизованном управлении с помощью программного счетчика и обработка данных с перезаписью содержимого памяти и регистров.
Прежде всего, при последовательной обработке в неймановской машине скорость обработки определялась быстродействием элементов, что ограничивало производительность ЭВМ. Поэтому для реализации высокой производительности при существующем ограничении на скорость обработки, обусловленной элементной базой, ничего не оставалось, как использовать параллельную обработку.
Кроме того, в программировании, основанном на концепции перезаписи памяти, соответствие между переменной и данными, которые являются ее значением, не обязательно определено однозначно и порядок перезаписи оказывает большое влияние на смысл программы. Это является причиной возникновения ошибок в программе, поэтому при составлении программы нужно быть предельно внимательным. В результате все это приводит к снижению производительности программного обеспечения. В этой связи возникла необходимость отказа от подобной концепции перезаписи памяти и соответствующего алгоритма организации вычислительного процесса.
8.2 Функциональное программирование
Вычислительная модель, в которой программа рассматривается как множество определений функций, называется функциональной моделью. Для описания функциональных моделей используются два метода: первый основан на использовании аппликативного языка, а второй - на использовании языка с однократным присваиванием. Отличительной чертой этих моделей является то, что в основу их положена простая и четкая математическая модель, называемая «лямбда-исчислением».
Рассмотрим основные понятия «лямбда - исчисления». В выражении f(x), которое используется обычно для представления функции, не ясно: то ли оно означает функцию f, то ли ее значение при заданном значении параметра х. Поэтому для четкого описания функции f было введено выражение λxf(x). To есть, когда выражение М хотят рассматривать как функцию от х, следует использовать запись λхМ. Получение выражения λxM из выражения М называют «лямбда - абстракцией». Таким образом, выражение λx(x+y) является функцией от х, а не от у. При этом х называется связанной переменной, а у - свободной переменной. Если f = λхМ, то подстановка выражения А в х внутри М называется применением А к f и записывается как fA. Вычисление выражения в этой модели носит название редукции.
Примерами языков программирования, реализующими вычисления на основе функциональных моделей являются для аппликативного языка «чистый» Лисп, предложенный Маккарти, FP Бэкуса и др., к языкам с однократным присваиванием относятся Id Арвинда, VAL Аккермана и Денниса др.
8.3 Потоковое программирование
Основная идея потокового программирования или модели вычислительного процесса по потоку данных основана на рассмотрении операции обработки данных, активируемой этими данными. Действительно реальное выполнение некоторой операции возможно только тогда, когда мы получаем исходные данные для этой операции. Тем самым данные, передаваемые из одной операции к другим, активируют соответствующие операции.
Потоковая обработка базируется на принципе выполнения программы, называемом управлением по данными. Принцип управляемости потоком данных гласит: «Все операции выполняются только при наличии всех операндов (данных), необходимых для их выполнения». В программе, используемой для потоковой обработки, описывается не поток сигналов управления, а поток данных.
Обработка, управляемая потоком данных, исходя из описанного выше принципа, отличается от обработки неймановского типа следующими моментами.
1) Операцию со всеми операндами (с имеющимися операндами) можно выполнять независимо от состояния других операций, т. е. появляется возможность одновременного выполнения множества операций (параллельная обработка).
2) Обмен данными между операциями четко определен, поэтому отношение зависимости между операциями обнаруживается легко (функциональная обработка).
3) Поскольку управление операциями осуществляется посредством передачи данных между ними, то нет необходимости в управлении последовательностью выполнения и, кроме того, нет необходимости в централизованном управлении (распределенная обработка).
Описание вычислительного процесса в машине потоков данных может быть представлено в виде графа, в котором
 |
вершины суть операции обработки данных, а дуги - процессы пересылки данных, полученных в результате обработки, с помощью которых происходит активация следующих вершин, как это показано на рис 8.1.
Граф вычислительного процесса в схеме потока данных
Рис 8.1
Реализация такой идеи приводит к появлению понятия командной ячейки, которая должна хранить код операции обработки, непосредственные операнды операции с их битами готовности и адресные поля, указывающие поля операндов других командных ячеек, в которые отправляется результат данной опера
 |
ции. Схема командной ячейки приведена на рис 8.2.
Схема командной ячейки
Рис 8.2
Поскольку результат одной операции может активировать несколько других командных ячеек, то для фиксации длины командной ячейки вводится дополнительная операция пересылки. Она имеет один операнд и два адресных поля отсылок, что позволяет, комбинируя командные ячейки пересылок реализовывать отправку поля данных в несколько командных ячеек, как это показано на рис 8.3.
 |
Множественная рассылка результата
Рис 8.3
Для иллюстрации управления командными ячейками с помощью битов готовности рассмотрим вычисление следующего арифметического выражения: Y = (a+b) / (a*b);
Командная ячейка, выполняющая операцию деления, будет активирована, когда в ее поля операндов поступят результаты от командных ячеек выполняющих операции сложения и умножения. Наличие двух битов готовности операндов приведет к установке бита готовности самой командной ячейки и, следовательно, она может быть выбрана для выполнения в процессоре. Эта ситуация приведена на рис 8.3
 |
Активация командной ячейки
Рис 8.3
В общем виде машина потоков данных должна содержать память командных ячеек, процессор, выполняющий активированные командные ячейки и два специальных устройства, называемых арбитражной и распределительной сетью. Назначение арбитражной сети - отслеживать готовые (активированные) командные ячейки и передавать их на выполнение процессору. Назначение распределительной сети - размещение полученного результата в поля операндов других командных ячеек, включая выполнение команды пересылки. Структура машины потоков данных приведена на рис 8.4.
 |
Структура машины потоков данных
Рис 8.4
9. АРХИТЕКТУРЫ ПАМЯТИ
9.1 Классификация архитектур памяти
В любой вычислительной машине с любой процессорной архитектурой программы и данные хранятся в памяти. Объем памяти и скорость доступа определяют размеры задач, которые можно решать на этой машине и скорость обработки данных, особенно для архитектур с большой частотой перезаписи данных.
Компромисс объема и скорости доступа достигается введением иерархии памяти, включающей запоминающие устройства разных типов. Однако такое решение по архитектуре памяти приводит к необходимости особого программирования различных запоминающих устройств.
Могут быть предложены различные архитектуры памяти, повышающие наблюдаемое быстродействие, без изменения элементной базы реализации запоминающих устройств, а именно:
a) архитектуры быстродействующей адресной оперативной памяти:
i) - чередование адресов;
ii) - иерархические структуры (кэш - память);
iii) - сквозная адресация (процессор пересылок);
b) архитектура памяти большой емкости (дисковая память);
c) архитектура виртуальной памяти;
d) архитектура общей памяти (для многопроцессорного доступа)
e) архитектура интеллектуальной памяти (ассоциативная память).
Выбор той, или иной архитектуры обусловлен требованиями, предъявляемыми к вычислительной машине, однако в настоящее время одно из них - требование обеспечения высокой надежности становится достаточно общим.
Высокая надежность определяется двумя факторами - количеством ошибок чтения/записи и защитой информации в памяти от несанкционированного доступа. Снижение уровня ошибок чтения/записи достигается применением кодов, обнаруживающих и исправляющих ошибки. Защита информации может быть обеспечена либо применением криптографических систем, либо путем задания каждому вычислительному процессу условий, разрешающих обращение только к определенным данным. Такие условия носят названия мандата, а механизм разграничения доступа, использующий мандат, носит название механизма с мандатной адресацией.
9.2 Память с чередование адресов
Архитектура быстрой памяти с чередованием адресов возникла для сглаживания различия в скорости между конвейерным процессором с конвейером команд и конвейером данных и обычной адресной оперативной памятью. Анализ обращений в память, особенно при обработке массивов, показывает, что доля обращений с последовательно увеличивающимися адресами достаточно значительна. Для согласования с конвейером необходимо, что бы было реализовано упреждающее чтение в быструю регистровую память для последовательных адресов. Такое упреждающее чтение и реализовано в архитектуре с чередованием адресов.
|
|
|
|
|
Дата добавления: 2015-04-25; Просмотров: 428; Нарушение авторских прав?; Мы поможем в написании вашей работы!