КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Использовать интерфейс FineReader
|
|
|
|
Использовать интерфейс TWAIN-драйвера сканера.
Отсканировать страницу текста, выполнить его распознавание и (при необходимости) корректировку. Результат сохранить в текстовом документе.
Рассмотрим выполнение данного задания с помощью программы FineReader 6.0. Расположим исходную страницу текста в сканере, откроем программу FineReader. Программа работает со сканерами через TWAIN-интерфейс. Это единый международный стандарт для унификации взаимодействия устройств ввода изображений в компьютер с внешними приложениями. Возможно два варианта взаимодействия программы со сканерами через TWAIN-драйвер:
· через интерфейс FineReader доступно сканирование в цикле на сканерах без автоподатчика, сохранение опций сканирования в отдельный файл Шаблон пакета (*.fbt) и возможность применения этих опций в других пакетах;
· через интерфейс TWAIN-драйвера сканера доступна функция предварительного просмотра изображения, позволяющая точно задать размеры сканируемой области, подобрать яркость, тут же контролируя результаты этих изменений. Но диалог TWAIN-драйвера сканера у каждого сканера выглядит по-своему.
Можно переключаться между этими режимами на закладке Сканирование / Открытие пункта Опции (меню Сервис > Опции), нужно установить переключатель в одно из положений:
Чтобы запустить сканирование, можно нажать кнопку Сканировать или в меню Файл выбрать пункт Cканировать.
Спустя некоторое время в Главном окне программы появится окно Изображение с изображением вставленного листа.
Качество последующего распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании. Качество изображения регулируется установкой следующих основных параметров сканирования.
Тип изображения — серый, черно-белый, цветной. Для системы распознавания оптимальным является сканирование в сером режиме, при этом проводится автоматический подбор яркости. Черно-белый режим экономит время сканирования, но может потерять информацию о буквах. Цветной режим выбирают, если нужно сохранить цветные элементы текста.
Разрешение. Следует использовать разрешение 300 dpi для обычных текстов и 400–600 dpi для текстов, набранных мелким шрифтом.
Яркость — в большинстве случаев подходит среднее значение яркости — 50%.
Чтобы установить параметры сканирования, нужно выбрать меню Сервис и пункт Настройки сканера. Появится следующее окно, где можно установить приведенные параметры.
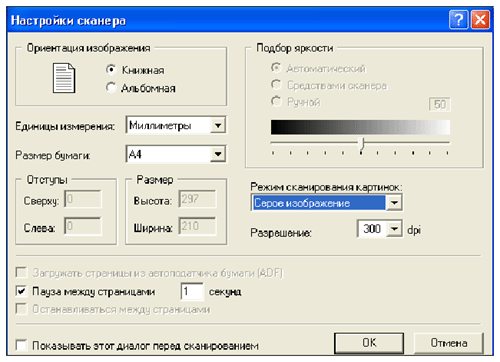
Применив указанные настройки, получим следующее изображение листа:
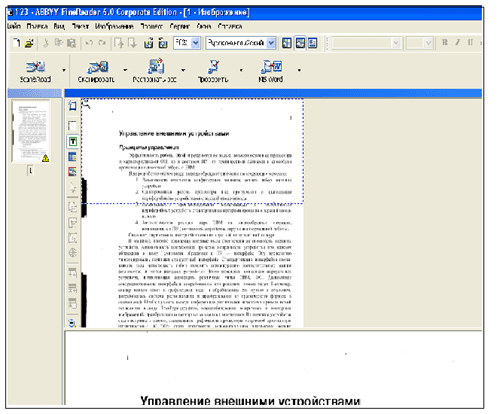
Перед распознаванием следует проверить и откорректировать полученное изображение листа. Изображение может содержать много лишних точек, возникших в результате сканирования документов среднего или плохого качества. Чтобы уменьшить количество лишних точек, можно воспользоваться опцией Очистить от мусора. Для этого в меню Изображение следует выбрать пункт Очистить изображение от мусора. Если требуется очистить от “мусора” отдельный блок, то следует выбрать пункт Очистить блок от мусора.
Если нужно какой-то участок текста исключить из распознавания, то можно стереть такие участки. Для этого нужно выбрать инструмент Ластик (на панели в окне Изображение) и, нажав на левую кнопку мыши, выделить требуемый участок изображения, и отпустить кнопку. Выделенная часть изображения будет удалена.
Прежде чем приступить к распознаванию, следует указать программе, какие участки изображения надо распознавать. Для этого проводится анализ макета страницы, во время которого выделяются блоки с текстом, картинки, таблицы. Автоматический анализ производится по кнопке 2 Распознать одновременно с распознаванием текста. При автоматическом анализе макета страницы FineReader сам выделяет блоки, содержащие тексты, таблицы, картинки.
Блоки — это заключенные в рамку участки изображения. Блоки выделяют для того, чтобы указать системе, какие участки отсканированной страницы надо распознавать и в каком порядке. Также по ним воспроизводится исходное оформление страницы. Блоки разных типов имеют различные цвета рамок:
1. Зона Распознавания — блок используется для распознавания и автоматического анализа части изображения.
2. Текст — блок используется для обозначения текста. Он должен содержать только одноколоночный текст. Если внутри текста содержатся картинки, нужно выделить их в отдельные блоки.
3. Таблица — этот блок используется для обозначения таблиц или текста, имеющего табличную структуру. При распознавании программа разбивает данный блок на строки и столбцы и формирует табличную структуру. В выходном тексте данный блок передается таблицей.
4. Картинка — этот блок используется для обозначения картинок. Он может содержать картинку или любую другую часть текста, которую нужно передать в распознанный текст в качестве картинки.
Задача распознавания состоит в том, чтобы преобразовать отсканированное изображение в текст, сохранив при этом оформление страницы. Прежде чем приступить к распознаванию текста, необходимо установить основные параметры распознавания:
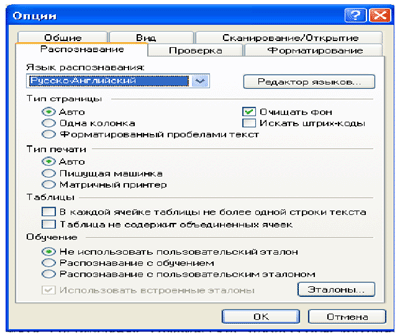
5. Язык распознавания. Программа поддерживает распознавание как одноязычных, так и многоязычных документов. Чтобы указать язык распознаваемого текста, нужно выбрать соответствующую строку в списке на панели Распознавание. Если требуется распознать документ, написанный на нескольких языках, следует в списке языков на панели Стандартная выбрать пункт Выбор нескольких языков… В открывшемся диалоге Язык распознаваемого текста укажите несколько языков.
1. Тип печати распознанного текста. Для большинства текстов тип печати определяется автоматически. При распознавании текстов, напечатанных на матричном принтере в черновом режиме или на пишущей машинке, можно добиться более высокого качества распознавания, установив правильный Тип печати:
· Пишущая машинка — для текстов, напечатанных на пишущей машинке;
· Матричный принтер — для текстов, напечатанных на матричном принтере.
Чтобы поменять тип печати на закладке Распознавание диалога Опции (меню Сервис>Опции), в группе Тип печати можно выбирать требуемый пункт.
2. Тип страницы. Для большинства изображений расположение текста на странице определяется автоматически, чему соответствует значение Авто на закладке Распознавание в группе Тип страницы (меню Сервис > Опции), устанавливаемое системой по умолчанию.
В некоторых случаях может потребоваться установить значение типа страницы вручную. Для этого на закладке Распознавание диалога Опции (меню Сервис>Опции) в группе Тип страницы нужно выбрать нужный пункт.
Укажем некоторые типы страницы:
1. Автоматическое определение — указывает, что расположение текста на странице определяется автоматически. Это значение устанавливается системой по умолчанию, подходит для распознавания всех видов текстов, в том числе многоколоночного текста, текста с таблицами и картинками.
2. Одна колонка —указывает, что текст на странице напечатан в одну колонку. Эта опция используется в случае, если автоматическое определение ошибочно сегментировало страницу как многоколоночный текст.
3. Форматированный пробелами текст —указывает, что текст на странице расположен в одну колонку и напечатан моноширинным шрифтом одного размера. В распознанном тексте сохраняется деление на строки; отступы от левого края передаются пробелами; каждая строка выделяется в отдельный абзац, и расстояния между абзацами передаются пустыми строками. Используется, например, для распознавания распечаток текстов программ.
Зададим опции распознавания в следующем окне:
После завершения распознавания результат появляется в окне Текст:

Окно Текст — это встроенный редактор программы FineReader; в нем можно проверить результаты распознавания и отредактировать распознанный текст. Одна из возможностей текстового редактора FineReader — это встроенная проверка орфографии. Система встроенной проверки орфографии позволяет:
1. Находить неуверенно распознанные слова (слова, в которых есть неуверенно распознанные символы).
2. Находить орфографические ошибки (неправильно написанные слова).
3. Добавлять неизвестные системе FineReader слова в словарь для того, чтобы они распознавались уверенно.
Неуверенно распознанные символы и слова, которых нет в словаре, выделяются различными цветами. По умолчанию для выделения неуверенно распознанных символов используется голубой, для несловарных слов — розовый. Чтобы проверить результаты распознавания, нужно нажать кнопку 3 Проверить на панели Scan&Read или выбрать пункт Проверка в меню Сервис. Откроется диалог Проверка. В диалоге Проверка три окна.
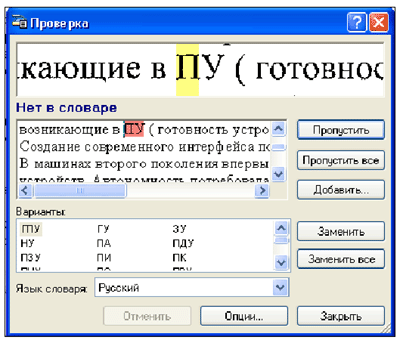
· В верхнем окне показано изображение слова с возможной ошибкой.
· Среднее окно показывает само слово с возможной ошибкой, в строке над этим окном выводится название типа ошибки.
· В нижнем окне Варианты предлагаются варианты замены данного слова.
Есть следующие возможности:
· Нажать кнопку Пропустить, чтобы оставить слово, как есть.
· Нажать кнопку Пропустить все, чтобы оставить все такие слова в распознанном тексте, как есть.
В нашем случае слово “ПУ” распознано правильно, мы нажмем кнопку Пропустить. Чтобы завершить проверку, нажмем кнопку Закрыть.
Результаты распознавания можно сохранить в файл, передать во внешнее приложение, не сохраняя на диск, скопировать в буфер обмена или отправить по электронной почте. Кнопка 4-MS WORD позволяет передать результаты распознавания в выбранное приложение или сохранить их в файл. Чтобы сохранить распознанный текст, нажмем стрелку справа от кнопки 4-MS WORD и в локальном меню выберем пункт Передать страницы в Microsoft Word:
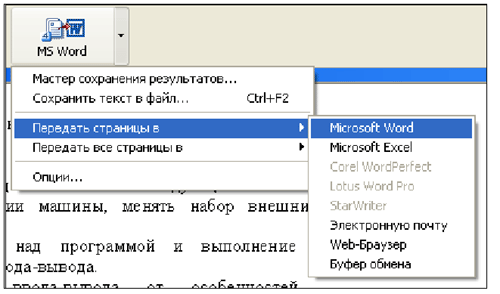
После этого страница отроется как документ Word:
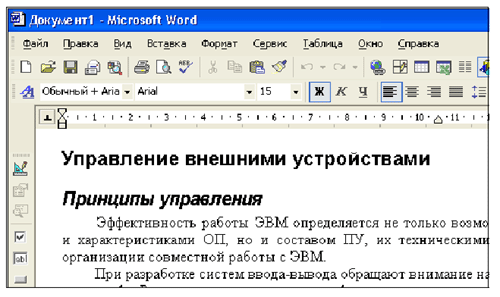
Теперь с ним можно работать, как с текстовым документом, средствами редактора MS Word.
|
|
|
|
|
Дата добавления: 2015-04-23; Просмотров: 1173; Нарушение авторских прав?; Мы поможем в написании вашей работы!