КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Определение энтропии. Ее “социологический” смысл. Энтропийный коэффициент разброса
|
|
|
|
Понятие энтропии всем знакомо по философской, физической, научно-популярной, научно-фантастической литературе – рост энтропии приводит к тепловой смерти вселенной (напомним, что это утверждение связано с идеями статистической термодинамики) и т.д. Мы коснемся этого понятия в очень слабой степени, рассмотрев, как с его помощью характеризуется упомянутая мера неопределенности.
Известно, что степень неопределенности распределения некоторой случайной величины Y (точнее, меры той неопределенности, которую имеет исследователь в смысле знания значения Y для какого-либо случайно выбранного объекта), определяется с помощью энтропии этого распределения. Введем соответствующие определения.
Пусть случайная величина Y принимает конечное число значений 1,2,..., k с вероятностями, равными, соответственно, Р 1, Р 2,..., Рk. (Напомним, что вероятность какого-либо значения для выборки отождествляется с относительной частотой встречаемости этого значения). Введем обозначение:
Рj = P (Y = j)
Энтропией случайной величины Y (или соответствующего распределения; напомним, что случайная величина отождествляется с отвечающими ей распределением вероятностей) Y называется функция
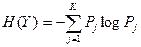 (основание логарифма произвольно)
(основание логарифма произвольно)
(Последняя формула обычно называется формулой Больцмана (Людвиг Больцман, 1844 - 1906 – австрийский физик, основатель статистической термодинамики). Именно формула, связывающая энтропию с термодинамической вероятностью, выгравирована на памятнике Больцману в Вене. Это соотношение дает статистическое обоснование второму началу термодинамики и является основой статистической физики.)
Чтобы лучше раскрыть смысл энтропии, представляется целесообразным пояснить, какого рода содержательные соображения о понятии неопределенности распределения могут навести на мысль об измерении этого понятия с помощью логарифма. Используем рассуждение из [Яглом, Яглом, 1969.С. 45].
Пусть некие независимые друг от друга признаки U и V принимают, соответственно, k и l равновероятностных значений. Рассмотрим, каким свойствам должна удовлетворять некая функция f, характеризующая неопределенность распределений рассматриваемых признаков. Ясно, что f = f (k) (т.е. рассматриваемая функция зависит от числа градаций того признака, неопределенность распределения которого она измеряет) и что f (1) = 0. Очевидно также, что при k >l должно быть справедливо неравенство f (k) > f (l). Число сочетаний значений рассматриваемых признаков равно произведению kl. Естественно полагать, что степень неопределенности двумерного распределения, f (kl) должна быть равна сумме неопределенностей соответствующих одномерных распределений, т.е. f (k l) = f (k) + f (l). Можно показать, что логарифмическая функция является единственной функцией аргумента k, удовлетворяющей условиям: f (k l) = f (k) + f (l), f (1) =0, f(k) >f (l) при k >l.)
Функция H (Y) и служит мерой неопределенности распределения Y.
(представляется очевидным, почему основание логарифма произвольно; как известно из школьной математики, от одного основания можно легко перейти к другому; все интересующие нас формулы при этом будут отличаться только на некоторый постоянный множитель, что несущественно для их интерпретации).
Чтобы лучше понять смысл энтропии, вникнем в смысл двух следующих ее свойств.
1) H (Y) ³ 0. Равенство достигается тогда, когда Y принимает только одно значение. Это – ситуация максимальной определенности: случайным образом выбрав объект, мы точно можем сказать, что для него рассматриваемый признак принимает упомянутое значение. Распределение Y выглядит следующим образом:
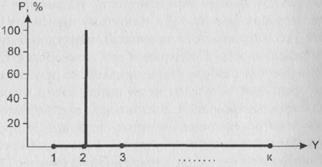
Рис. 12. Пример распределения с нулевой энтропией
Единственная отличная от нуля вероятность здесь равна 1. Нетрудно проверить, что для такого распределения энтропия действительно равна нулю.
2) При фиксированном “k” значение энтропии максимально, когда все возможные значения Y равновероятны. Это – ситуация максимальной неопределенности. Предположим, например, что k=5. Тогда распределение Y для такой ситуации будет выглядеть следующим образом:
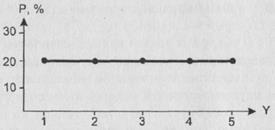
Рис. 13. Пример распределения с максимальной энтропией при заданном числе градаций признака
Ясно, что здесь Pj = 0,2. Нетрудно проверить, что значение энтропии при этом равно log 5, а в общем случае в ситуации полной неопределенности энтропия равна log k. Таким образом, чем больше градаций имеет рассматриваемый признак, тем в принципе большей энтропии может достичь отвечающее ему распределение.
Итак, на рис. 12 – минимальная (нулевая) энтропия, наилучший прогноз, полная определенность. На рис.13 – максимальная энтропия (равная log k и поэтому зависящая от числа градаций рассматриваемого признака), наихудший прогноз, полная неопределенность. Подчеркнем еще и то обстоятельство, что на первом рисунке разброс рассматриваемого признака (в том смысле, который был обсужден нами выше) равен нулю, а на втором – максимально большой. В жизни же, конечно, чаще всего встречаются некоторые промежуточные ситуации. И представляется очевидным, что энтропия будет тем больше, чем реальное распределение ближе к ситуации, отраженной на рис. 13, и тем меньше, чем оно ближе к ситуации, отраженной на рис. 12.
Поэтому будем считать интуитивно ясным тот факт, что энтропия может использоваться при оценке степени разброса значений номинального признака. Однако мы уже упоминали, что максимальное значение энтропии для распределения какого-либо признака зависит от числа его градаций. Следуя той же логике, что была использована нами выше, нетрудно придти к выводу, что сама энтропия, в силу сказанного, не может выступать в качестве меры разброса. Чтобы такое использование было правомерным, значение энтропии необходимо нормировать – поделить на величину максимальной энтропии. Так обычно и поступают: в качестве меры разброса используют энтропийный коэффициент
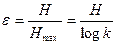
Подробнее об этом см. работу [Паниотто, Максименко, 1982].
В заключение параграфа отметим, что в том направлении науки, которое связано с моделированем социальных процессов, понятие энтропии занимает существенное место. Причины этого нетрудно понять. Скажем, известно, что общества слишком однородные, либо слишком разнородные не является устойчивымы. А однородность может оцениваться как раз с помощью энтропии. Правда, для того, чтобы энтропия могла “работать на прогноз”, необходимо решить серьезные содержательные вопросы и, в первую очередь, определить – для каких признаков энтропию надо измерять.
15. Анализ номинальных данных как одна из главных задач социолога. Роль номинальных данных в социологии. Соотношение между причинно-следственными отношениями и формальными методами их изучения.
Роль номинальных данных в социологии огромна. Объяснить это можно следующими (взаимосвязанными) причинами.
Во-первых, именно номинальные данные чаще всего используются социологами. Вероятно, это можно объяснить сравнительной простотой их получения, естественностью интерпретации, интуитивной уверенностью в состоятельности последней.
Во-вторых, номинальные данные являются более надёжными, чем данные, полученные по шкалам более высокого типа, в том смысле, что за ними обычно не стоят трудно проверяемые модели восприятия (имеется в виду восприятие респондентом предлагаемых ему для оценки объектов, суждений, мнений и т.д.; о моделях, предполагаемых известными методами шкалирования, см., например, [Толстова, 1998]), и, в соответствии с этим, при их интерпретации не используются сложные и зачастую сомнительные допущения.
В-третьих, в методах, используемых для анализа номинальных данных, обычно бывают "заложены" модели, не вызывающие сомнения, отвечающие естественной логике социолога, изучающего собранную информацию "вручную", без использования математики и ЭВМ.
Надеемся, что все сказанное ниже позволит читателю в этом убедиться.
Здесь сделаем небольшое отступление. Среди социологов бытует мнение о том, что достижение интервального уровня измерения всегда является желаемым, поскольку расширяет возможности исследователя, давая ему основания использовать традиционные методы математико-статистического анализа данных. С одной стороны, это, конечно, так: подобные основания действительно имеют под собой почву (хотя надо иметь в виду, что и интервальные данные - не совсем числовые и поэтому к ним применимы не все упомянутые традиционные алгоритмы). Но, с другой стороны, остается вопрос о том, не слишком ли дорога соответствующая цена, не обесценивается ли полученное преимущество несостоятельностью анализируемых данных. Последнее соображение настолько важно, что некоторые авторы вообще полагают, что в социологии только номинальные шкалы имеют право на существование [Чесноков, 1986]. И принять это соображение во внимание имеет смысл еще и потому, что для анализа номинальных данных имеется много достаточно эффективных методов.
Соотношение между причинно-следственными отношениями и формальными методами их изучения
Изучение связей между переменными, как правило, интересует исследователя не само по себе, а как отражение соответствующих причинно-следственных отношений. Представляется излишним доказательство актуальности соответствующих задач, их важность для любого социологического исследования. Однако причинные отношения при изучении социальных явлений не удается выделить в “чистом” виде. Социолог может наблюдать только соответствующие статистические закономерности (статистические связи), в качестве измерителей которых и выступают известные показатели связи (далее мы увидим, в чем именно проявляется статистичность интересующих нас связей).. То устойчивое, необходимое, что скрывает за каждым коэффициентом (или за системой таких коэффициентров) зачастую оказывается возможным отождествить с соответствующей причинной зависимостью.
Подчеркнем, однако, понятия "причина" и "следствие" в принципе не могут быть формализованы. Никакая математика не может нам доказать, что такой-то признак служит причиной (следствием) того или иного явления. Можно привести массу примеров, когда наличие даже самой сильной статистической связи совершенно не означает наличие соответствующей причинной зависимости. Например, у людей, как правило, одновременно появляется желание надеть легкое платье и пойти искупаться не потому, что одно причинно обусловливает другое, а потому, что оба эти желания вызваны одним и тем же обстоятельством – наступлением жаркой погоды. Другой пример: два студента одновременно вдруг проявляют необыкновенную тягу к знаниям или, напротив, стремятся отлынивать от занятий не потому, что один на другого причинно воздействует, а потому, что сессия у них в одно и то же время – одновременное причинное воздействие третьего признака на каждый из двух данных вызывает статистическую связь между данными признаками. Подобные статистические, не являющиеся причинно-следственными, связи в литературе носят название ложной корреляции. Название не очень удачное – корреляция-то (т.е. статистическая связь) как раз истинна, ложно – причинно-следственное отношение.
Итак, математические методы могут лишь навести нас на мысль о существовании причинных отношений, заставить быть более уверенными в своих предположениях, или, напротив, усомниться в них, скорректировать свои априорные представления или даже совсем отказаться от них. Тем не менее, термины "причина" и "следствие" часто употребляются при математическом анализе социологических данных. Однако обычно они отражают лишь априорные исследовательские предположения соответствующего плана.
Правда, в одной из известных ветвей многомерного статистического анализа – т.н. причинном (путевом) анализе [Хейс, 1981] термин "причина" используется именно как нечто формально недоказуемое. В его рамках специально изучаются ситуации с ложными корреляциями, подробно рассматривается, как сложные, опосредованные цепочки причинных отношений могут объяснять их наличие, позволяет понять, за счет чего иногда между какими-то признаками может быть сильная статистическая зависимость при полном отсутствии причинно-следственной, какими сложными опосредованными причинными отношениями эта связь может объясняться.
16. О понятии таблицы сопряженности. Классификация задач анализа связей номинальных признаков.
Представляется естественным использовать для оценки связей между признаками т. н. частотные таблицы, или таблицы сопряженности (по существу мы о них уже говорили – это выборочные оценки вероятностных распределений многомерных случайных величин; так, в таблице 3 части I приведен пример распределения для двумерной величины). Заметим, что последний термин обязан своим происхождением именно тому обстоятельству, что на основе анализа подобных таблиц можно судить о сопряженности (совместной встречаемости) каких-то значений одних признаков с некоторыми значениями других признаков. Как мы увидим, связь между номинальными признаками, собственно говоря, и выражается в виде подобных сопряженностей.
Предположим, что мы имеем два признака X и Y, первый из которых принимает "r" значений 1, 2,..., r, а второй – "c" значений 1, 2,..., c. Назовем двумерной таблицей сопряженности (двумерной частотной таблицей) некоторую матрицу, на пересечении i-й строки и j-го столбца которой стоит число niij, означающее количество объектов, обладающих i-м значением первого признака и j-м значением второго (i =1,..., r; j =1,..., c) (использование латинских букв r и c в указанном смысле принято в литературе; эти буквы сопрягаются с английским словами raw и column, означающими "строка" и "столбец" соответственно; это не позволяет нам забывать, что значения одного признака отвечают строкам таблицы сопряженности, а другого - столбцам). Другими словами, таблица сопряженности выглядит так:
Таблица 6.
Общий вид таблицы сопряженности
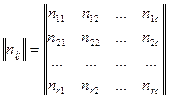
Обычно ее представляют в несколько ином виде, с явно обозначенными наименованиями признаков и их значений и выписанными маргинальными суммами:
Таблица 7
Общий вид таблицы сопряженности
| X | Y | Маргиналы по строкам | |||||
| … | j | … | c | ||||
| n11 | n12 | … | n1j | … | n1c | n1. | |
| n21 | n22 | … | n2j | … | n2c | n2. | |
| … | … | … | … | … | … | … | … |
| i | ni1 | ni2 | … | nij | … | nic | ni. |
| … | … | … | … | … | … | … | … |
| r | nr1 | nr2 | … | nrj | … | nrc | nr. |
| Маргиналы по столбцам | n.1 | n.2 | … | n.j | … | n.c | n |
Правый крайний столбец образуют строковые маргинальные суммы (маргиналы по строкам). Величина ni. равна сумме элементов i-й строки (т.е. числу тех объектов, для которых первый признак принимает значение i). Нижняя строка образуется столбцовыми маргинальными суммами (маргиналами по столбцам). Величина n.j равна сумме элементов j-го столбца (т.е. числу тех объектов, для которых второй признак принимает значение j). n - объем выборки, он равен сумме маргиналов по столбцам (либо по строкам).
В последние годы в литературе все более используется расширительное понимание таблицы сопряженности. Предполагается, что в качестве ее элементов могут фигурировать не только частоты, но и многие другие числа: скажем, в клетках половозрастной таблицы могут стоять средние значения зарплаты тех людей, которые характеризуются отвечающим клетке значениям пола и возраста. Таким же образом в клетки таблицы могут быть помещены средние другого рода (мода, медиана), дисперсии, величины отклонений от средних по строке (столбцу), разница между эмпирической и теоретической частотой (см. п.2.2.1) и т.д. (см., например, [Ростовцев и др., 1997. С.177-179]). О том же расширительном понимании таблицы сопряженности говорится в описании известного пакета SPSS.
Ниже, приводя примеры, под объектами, число которых подсчитывается при построении таблицы сопряженности, мы будем иметь в виду респондентов. Хотелось бы, чтобы читатель давал себе отчет в условности таких примеров, понимая, что отнюдь не только респонденты могут интересовать социолога.
17. Диалектика в понимании признака и его значений. Расширение понятия взаимодействия. Классификация рассматриваемых задач и отвечающих им методов.
2.2. 1. Диалектика в понимании признака и его значений.
Со следующей главы мы начнем описание ряда методов анализа номинальных данных. Придадим цельность нашему изложению путем установления связи между этими методами посредством прослеживания определенного родства заложенных в этих методах моделей. Сделаем это посредством выработки единого основания для классификации всех рассматриваемых алгоритмов, основания, связанного с определенной типологией социологических задач.
Предлагаемое основание будет опираться на то обстоятельство, что для социолога важно осознание необходимости определенной диалектики в понимании признака и его значений: выделение ситуаций, когда отдельной альтернативе имеет смысл придать статус самостоятельного признака.
Приведем пример. Нас может интересовать, каким является отвечающее респонденту значение признака "профессия", а может – является ли этот респондент или не является учителем. Во втором случае мы придали статус признака одному значению признака "профессия" – тому, которое называлось "учитель". К такому переходу нас подталкивает не желание пооригинальничать, а стремление адекватно решать стоящие перед социологом задачи. Скажем, изучая связи между рассматриваемыми переменными, мы можем придти к выводу, что профессия никак не связана с полом (забегая вперед, скажем, что такой вывод можно сделать, использовав какой-либо из известных коэффициентов связи, рассчитывающихся на базе таблицы сопряженности "пол – профессия", скажем, критерий "Хи-квадрат", см. п. 2.3.1). Тем не менее, та же статистика может нам говорить, что почти все учителя – женщины, т.е. что соответствующее отдельное значение признака "профессия" связано с полом. Чтобы не "упустить" эту "локальную" связь, мы и должны рассмотреть отдельный дихотомический признак "быть учителем" с целью измерения величины его связи с признаком "пол".
Описанное требование можно обобщить: самостоятельной переменной может отвечать не одно значение некоторого признака, а сочетание таких значений (скажем, при решении ряда задач имеет смысл объединить, учит е лей и врачей вместе), каждое из которых соответствует, вообще говоря, своему признаку (о таких ситуациях, когда объединяются альтернативы разных признаков, пойдет речь в п.2.5).
Два слова о терминах. В работе [Чесноков, 1982] предлагается называть глобальными коэффициенты парной связи, рассчитывающиеся на основе учета всех градаций рассматриваемых признаков, и локальными – коэффициенты связи, рассчитывающиеся на основе учета одной градации одного признака и одной градации другого. Нам представляется неприемлемым деление всех показателей на глобальные и локальные, поскольку при таком подходе из рассмотрения (во всяком случае на терминологическом уровне), выпадают связи "промежуточных" видов: такие, когда учитываются несколько градаций каждого признака. Однако термин “локальная связь” мы будем использовать, понимая под таковой связь между отдельными альтернативами.
Заметим, что п риведенные выше соображения имеют самое непосредственное отношение к проблеме социологического измерения, к анализу понятия "признак" и, в конечном счете, к проблеме операционализации понятий, к изучению перехода от реальных многогранных объектов к их узкому, всегда ограниченному описанию набором некоторых признаков (к "мышлению признаками", по выражению автора работы [Ноэль, 1993]).
Описанные ситуации возникают в силу того, что, с одной стороны, само понятие признака имеет смысл только при некоторой однокачественности тех объектов, для которых значения признаков вычисляются; с другой стороны, – каждому значению признака отвечает свое собственное качество. Понятие однокачественности относительно. На разных этапах исследования может возникнуть потребность однокачественные объекты считать разнокачественными и наоборот. Так, выше мы показали, что бывают ситуации, когда однокачественными объектами мы считаем всех тех и только тех респондентов, которые имеют профессию учителя. Человек же с профессией врача в такой ситуации будет иметь другое качество. При изучении проблем интеллигенции учитель и врач могут стать однокачественными объектами. Если же мы работаем с признаком "профессия" как единым целым, то тем самым полагаем, что этот признак отражает существование некоторого социального института и однокачественными являются все члены такого общества, в котором этот институт имеется.
В обосновании необходимости "склеивания" отдельных значений разных (вообще говоря) признаков просматривается актуальность решения следующей проблемы социологического измерения: чтобы отразить латентны е свойства объекта, мы вынуждены "выдергивать" отдельные значения разных признаков, формировать из этих "надерганных" значений различные комбинации, надеясь, что какое-то сочетание хотя бы частично явится индикатором определенного "поведения" объекта.
Дальнейшее обобщение требования склеивания отдельных градаций приводит к осознанию возможности рассмотрения в качестве нового признака не сочетания отдельных альтернатив, а сочетания нескольких признаков. Соответствующее обобщение проблемы измерения очевидно: новым измеряемым признаком является здесь комбинация исходных признаков.
Продолжая ту же логику, естественно приходим к необходимости рассмотрения всех признаков сразу как единой системы.
Выделение перечисленных возможностей мы будем рассматривать как основу для дальнейшего изложения (в частности, для классификации методов анализа связей номинальных признаков).
Итак, в соответствии с предлагаемой точкой зрения, каждый рассматриваемый метод можно трактовать как реализацию следующего процесса: все исходные номинальные признаки как бы "рассыпаются" на отдельные градации, которые затем по-разному комбинируются, на их основе строятся новые признаки, взаимоотношения которых далее изучаются. Каждый метод анализа связей номинальных данных предлагается рассматривать как метод поиска либо связей между разными группами альтернатив, либо групп альтернатив, определяющих некоторое поведение респондентов (задаваемое разными способами). Методы систематизируются в зависимости от отвечающих им способов агрегирования отдельных альтернатив в новые признаки.
Использование предлагаемого подхода, на наш взгляд, побуждает исследователя не забывать о существовании многих методов, весьма адекватных социологическим задачам, но мало используемых социологами.
В данном разделе мы будем рассматривать методы, которые включаются в указанную классификацию. Но прежде, чем более подробно ее описать (что будет сделано в п. 2.2.2), представляется важным рассмотреть один момент, позволяющий лучше понять, как модели, заложенные в интересующих нас методах, соотносятся с моделями других известных методов анализа данных (о других моментах такого рода см. п. 2.2.3).
Нетрудно заметить, что упомянутые выше задачи (и отвечающие им методы), связанные с поиском групп альтернатив, определяющих некоторое поведение респондентов, очень похожи на задачи поиска того, что в математической статистике (в частности, в дисперсионном и регрессионном анализе; описание первого можно найти, например, в [Статистические методы..., 1979], о втором пойдет речь в п.2.6), называется взаимодействием.
Напомним, что использование этого термина предполагает выделение среди всех признаков главного признака (зависимого, выходного, целевого, объясняемого, результирующего, признака-функции, признака-следствия) и группы детерминирующих его признаков (независимых, входных, объясняющих, предикторов, признаков - аргументов, признаков-причин; подробнее о подобных терминах см. п. 2.5.3.1). “Взаимодействие” означает сочетание значений независимых признаков, определяющих тот или иной уровень зависимого (заметим, что в дисперсионном анализе зависимый признак предполагается количественным, т.е. таким, значения которого получены по крайней по интервальной шкале; а совокупность независимых признаков фиксируется). Например, при изучении миграционного поведения взаимодействием может служить свойство респондента одновременно быть мужчиной (т.е. обладать, скажем, значением “1” признака 4 - “пол”) и иметь высшее образование (т.е. обладать, например, значением “5” признака 6 - “образование”), если это свойство детерминирует желание обладающего им человека уехать за границу.
Роль по иска взаимодействий в эмпирической социологии вряд ли можно пре увеличить. Однако пр едставляется, что потребность практики делает целесообразным расширение этого понятия. Для того, чтобы пояснить, каким способом это можно сделать, попытаемся вдуматься в смысл того, что значит делать какие-то выводы в терминах рассматриваемых (номинальных) признаков. Вероятно, исходя из здравого смысла, подобные выводы должны иметь вид (мы имеем в виду формальную структуру того статистического утверждения, которое служит социологу основой для дальнейших выводов о причинно-следственных отношениях):
“5-е значение 8-го признака часто встречается с 3-м значением 14-го и 1-м значением 2-го”, “из того, что 3-й признак принимает 2-е значение одновременно с тем, что 4-й принимает 5-е значение, как правило, следует, что 6-й признак принимает либо 2-е, либо 3-е”, “из того, что 3-й признак принимает какое-либо значение, кроме 2-го, следует, что 7-й признак принимает 4-е значение” и т.д. (надеемся, что для понимания сказанного не требуется более конкретно формулировать подобные утверждения: скажем, указывать, что 3-й признак - это возраст, его 5-е значение - указание того, что возраст конкретного респондента заключён в интервале от 35 до 40 лет и т.д.).
(Выражения, подобные сформулированным, являются наиболее естественными для социолога. Они отвечают сути номинальных шкал, тому, что каждое значение признака означает самостоятельное автономное качество объекта. Однако исследователь зачастую стремится по-другому формулировать искомые содержательные выводы, вольно или невольно вписывая их в традиционные рамки классических математико-статистических формулировок: “такие-то два признака имеют сильную статистическую связь”, “второй признак линейно зависит от седьмого” и т.д. Можно показать, что такие формулировки тоже могут быть "переведены" на язык наших взаимодействий.)
Анализ подобного рода выражений заставляет следующим образом обобщить понятие взаимодействия:
совокупность признаков-предикторов будем считать "плавающей" (естественно, - в пределах множества признаков, заданных в исследовании; напомним, что в дисперсионном анализе фиксируется небольшое количество признаков-предикторов и рассматриваются все возможные сочетания их значений; среди этих значений и ищутся взаимодействия); в частности, будем полагать, что какое-то сочетание значений одного набора предикторов может определять одно значение признака-функции, а некоторое сочетание значений другого набора предикторов – другое значение функции; например, в добавление к высказанному выше гипотетическому предположению о том, что у мужчин с высшим образованием появляется желание покинуть Родину, можно добавить еще одно предположение – о том, что женщины, имеющие более двух детей, напротив, выступают против отъезда за границу;
будем полагать, что взаимодействием может быть не только конъюнкция суждений типа “ значение такого-то признака равно тому-то” (именно конъюнкцией суждений “человек – мужчина” и “человек имеет высшее образование” является суждение “человек является мужчиной с высшим образованием”), а любые логические функции от таких выражений (предполагаем, что читатель знает определение основных логических функций - конъюнкции, дизъюнкции, импликации, отрицания; используемые здесь и ниже сведения по логике можно почерпнуть, например, из [ Бочаров, Маркин, 1994 ]); например, взаимодействием будем считать суждение "человек является или пенсионером, или женщиной с маленьким ребенком, или не бизнесменом", если люди, обладающие соответствующими свойствами, не желают покидать родные места; (сравним также с упомянутыми выше "2-м значением 3-го признака и 5-м – 4-го, любым значением 3-го, кроме 2-го";) такого рода функции будем называть объясняющими, или детерминирующими, положениями (выражениями); их будем описывать так, как это обычно делается в литературе: используя для обозначения входящих в них признаков букву Х с индексами (Х 3 (2) & Х 4 (5), u Х 3 (2) и т.д.).
будем полагать, что наше взаимодействие может определять не только некоторое значение непрерывного признака (как в дисперсионном анализе), но и любую логическую функцию значений произвольных, в том числе дискретных (в частности, номинальных) признаков (ср. упомянутые выше "3-е значение 14-го признака и 1-е – 2-го; 2-е или 3-е значение 4-го признака); каким-либо другим образом задаваемое "поведение" респондента (примеры будут приведены в п.2.5, при обсуждении алгоритмов THAID и CHAID); частоту в таблице сопряжённости (ср. “ 5-е значение 8-го признака часто встречается с 3-м значением 14-го и 1-м значением 2-го”; это мы рассматривать не будем; однако подчеркнем, что речь идет об очень актуальных для социологии задачах, решаемых с помощью логлинейного анализа [ Аптон, 1982 ]); а может и ничего не определять, но тогда естественно требовать просто истинность взаимодействия как логической функции; то, что определяет взаимодействие, будем называть объясняемыми, или детерминируемыми, положениями. их будем описывать обычно, используя для входящих в них признаков букву Y с индексами;
О поиске обобщенных взаимодействий будем говорить как о поиске закономерностей или детерминаций.
Рассмотрим еще одну сторону понимания термина "взаимодействие" - то, каким образом могут быть связаны объясняющее и объясняемое положения. Обратим внимание на некоторые аспекты приведенных выше формулировок типичных социологических утверждений в терминах используемых номинальных признаков. “5-е значение 8-го признака часто встречается с 3-м значением 14-го и 1-м значением 2-го”, “из того, что 3-й признак принимает 2-е значение одновременно с тем, что 4-й принимает 5-е значение, как правило, следует, что 6-й признак принимает либо 2-е, либо 3-е”. Представляются очевидными причины появления выделенных слов в приведенных выражениях. Мы имеем дело лишь со статистическими закономерностями, являющимися в определенном смысле приближенными. Например, если даже вполне можно считать, что мужчины с высшим образованием имеют склонность эмигрировать, практически всегда из этого правила будут исключения. И всегда встает вопрос о том, каково должно быть количество подобных исключений для того, чтобы мы все-таки считали найденную закономерность закономерностью. К этому вопросу мы не раз будем возвращаться.
Как формализовать выражения "часто встречается", "как правило" и т.д.? Без формализации мы не можем проверять справедливость рассматриваемых суждений. Формализация же – это фрагмент используемой модели. Он разный в разных методах. Так, в неоднократно упомянутом нами дисперсионном анализе речь идет о статистической значимости различий средних значений выходного признака для респондентов, обладающих разными сочетаниями значений предикторов. Как мы увидим ниже, в других интересующих нас алгоритмах задействованы другие критерии (о них пойдет речь ниже, при описании соответствующих алгоритмов). Возможность разных критериев тоже может рассматриваться как элемент обобщенного подхода к пониманию взаимодействия. Обсуждая подобные критерии, будем говорить о формализации понятия приближенности искомой закономерности.
П ри таком понимании взаимодействия можно сказать, что поиск взаимодействий разного рода служит основой большинства рассматриваемых нами методов анализа номинальных данных. В следующем параграфе будут приведены примеры.
2.2. Классификация рассматриваемых задач и отвечающих им методов
Ниже в скобках бы будем указывать примеры математических методов, направленных на решение задач выделяемых классов. При первом чтении это можно опустить. Мы называем конкретные методы уже сейчас, до того как они будут описаны (а следующие параграфы будут посвящены такому описанию; сами названия этих параграфов отвечают названиям выделенных ниже классов задач), по двум причинам: во-первых, для того, чтобы читатель, знакомый с упоминаемыми методами, лучше понял нашу классификацию; во-вторых, мы надеемся,что читатель вернется к настоящему параграфу после прочтения всей книги с целью более четко представить себе совокупность тех алгоритмов, из числа которых ему предстоить выбрать инструмент для обнаружения интересующих его закономерностей.
Итак, в соответствии с предлагаемым основанием выделяются задачи типа:
"альтернатива-альтернатива", т.е. такие, которые позволяют изучать связь между отдельными значениями любых рассматриваемых признаков (примером является детерминационный анализ [ Чесноков, 1 982 ]);
"(группа альтернатив) - (группа альтернатив)" (анализ фрагментов таблиц сопряженности [ Интерпретация и анализ..., гл. 2], алгоритмы типа "пятна" и "полосы" [Ростовцев, 1985. С. 203-214]); эту группу методов можно расширить, условно назвав результат такого расширения методами типа
" (группа альтернатив) – ("поведение" объектов)", где “ поведение" (подчеркнем, - не одного объекта, а целой совокупности, заданной рассматриваемой группой альтернатив; такое "поведение" в определенном смысле есть описание этой совокупности, которое, в свою очередь, можно интерпретировать как характеристику некоторого типа объектов) может пониматься по-разному: как определенный каким-либо образом "средний" уровень заранее заданного результирующего признака (скажем мы можем искать тип людей с низким уровнем зарплаты и тип людей с высоким уровнем зарплаты), как истинность для рассматриваемой совокупности некоторой логической функции от элементарных формул типа P(a)=1, (так называемых логических закономерностей), где буквой Р обозначен произвольный признак, а приведенное выражение означает: "значение признака P для объекта a равно 1" и т.д. (методы выявления логических закономерностей [Лбов, 1981], методы поиска детерминирующих сочетаний значений рассматриваемых признаков, в том числе известные на Западе алгоритмы, для обозначения которых исп ользуются аббревиатуры, включающие в себя сочетание AID (automatic interaction detector): THAID [ Интерпретация и анализ данных в социологических исследованиях, 1987, с. 136-151; Messenger, Mandell 1972; Morgan, Messenger, 1973]), CHAID [Agresti, 1990; Magidson, 1993; Derrick, Magidson, 1992], AID3 [Sonquist, Morgan, 1973] и т.д. Сравнение THAID и AID3 осуществляется в [ Kass, 1980 ]. Ряд методов описан в [Типология и классификация в социологических исследованиях, 1982, с. 213 - 231 ]. Назовем также брошюру [Ливанова Т. Н. 1990], где подробно описан процесс реализации на ЕС ЭВМ алг о ритма AID3. Хо тя в наше время персональных компьютеров такое описание не является актуальным, тем не менее, на наш взгляд, указанная работа не стала бесполезной для социолога, поскольку в ней помимо правил обращения с ЭВМ серии ЕС подробно раскрывается сущность самого алгоритма).
Частным случаем упомянутых комбинаций явится объединение в одну груп п у альтернатив, отвечающих одному признаку. В соответствии с этим, выделим класс задач:
– "признак - признак" (традиционные, наиболее знакомые социологу коэффициенты парной связи).
Продолжая рассуждения, отвечающие той же логике, нетрудно придти к выводу, что та же специфика измерительных процедур может вызвать потребность объединять не только "надерганные" из разных признаков альтернативы, но и признаки в целом. в соответствии с этим, в рамках нашей классификации выделим группы методов:
– "признак - (группа признаков)" (регрессионный анализ, многие методы построения индексов);
(Отметим, что при использовании регрессионного анализа зачастую решаются также задачи типа "(группа альтернатив) - ("поведение" объекта)"; это ярко демонстрирует его так называемый номинальный вариант [ Аргунова, 1990; Типология и классификация..., 1982; H а rdy, 1993], см. также п. 2.6.)
– "(группа признаков) - (группа признаков)" (канонический анализ [ Интерпретация и анализ..., 1987 ]). Это известный математико-статистический метод. Однако он крайне редко используется социологами, считающими его типично "количественным" методом. В действительности же соответствующий подход является актуальны м для анализа именно номинальных данных: он дает возможность осуществлять их оцифровку (т.е. приписать каждому значению номинального признака некоторое число), изучать связи между признаками с т. н. "совместными" альтернативами, эффективно находить веса признаков при формировании из них индекса. Идеи, заложенные в каноническом анализе используются в таком широко применяющимся в современной западной социологии (в том числе в ставших “модными” в России маркетинговых исследованиях) методе, как корреспонденс-анализ, или анализ соответствий [ Clausen, 1998 ]).
Тип задач, отвечающих рассмотрению всей совокупности признаков как системы, назовем так:
– анализ системы признаков (логлинейный анализ [ Аптон, 1982; Елисеева, Рукавишников, 1977; Мирзоев, 1980,1981; Миркин, 1980 ]; причинный анализ [ Елисеева, Рукавишников, 1982; Осипов, Андреев, 1977; Хейс, 1981 ]).
К сожалению, в настоящей работе мы не имеем возможности рассмотреть последние два типа задач.
Конечно, если строго следовать формальной логике, можно заметить, что почти все упомянутые классы методов могут быть сведены к одному – классу "(группа альтернатив)-(группа альтернатив)", поскольку с формальной точки зрения частным случаем группы альтернатив является и отдельная альтернатива; и набор градаций, отвечающих одному признаку; и совокупности значений сразу нескольких признаков. Но с содержательной точки зрения все же мы не можем игнорировать различие между выделенными выше совокупностями альтернатив. В частности, понятие признака – это нечто, отвечающее вполне определенной социальной реальности. За частью альтернатив признака эта реальность не стоит. И, как мы увидим ниже, методы, позволяющие решать задачи выделенных классов, различны, поскольку различны постановки соответствующих содержательных вопросов.
Казалось бы, изложение надо начинать с описания наиболее простых методов – типа “альтернатива – альтернатива”. Однако исторически сложилось так, что сначала были разработаны коэффициенты парной связи между признаками (т.е. наши методы типа “признак – признак”). А все остальные подходы опирались на соответствующие теоретические положения. Мы не хотим претендовать на разработку новых подходов к обоснованию известных коэффициентов. Поэтому начнем как бы с середины нашей схемы – с описания методов измерения связей между двумя номинальными признаками. Однако прежде позволим себе некоторое отступление от основного содержания настоящей книги. Дело в том, что подходами, рассматриваемыми в настоящей работе, отнюдь не ограничивается ни совокупность всех методов анализа номинальных данных вообще, ни совокупность методов анализа связей между номинальными переменными. Д ля того, ч тобы более четко охарактеризовать круг задач, решение которых становится доступным с помощью подходов, описанных в следующих параграфах, попытаемся очертить то место, которое эти подходы занимают в гораздо более широкой совокупности известных методов анализа номинальных данных. Сделаем это, обратившись к рассуждениям, нетрадиционным для работ по анализу данных.
18. Выделение двух основных групп методов анализа номинальных данных. Место рассматриваемых в книге подходов в этой группировке
|
|
|
|
|
Дата добавления: 2015-04-23; Просмотров: 1169; Нарушение авторских прав?; Мы поможем в написании вашей работы!