КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Модули ответов 1 страница
|
|
|
|
Case-based reasoning;
Instance-based learning;
Алгоритм ID3;
Алгоритм Candidate-elimination;
Алгоритм Find-S;
Inductive bias and unbiased learning;
IB создан для классификации новых невидимых примеров. Индуктивное предубеждение- это любой критерий, используемый обучаемой системой для ограничения пространства понятий или для выбора понятий в рамках этого пр-ва. Пр-во обуч. примеров обычно достаточно велико. Поэтому без нек. его разделения обучение на осн. поиска практически невозможно.
Имеются условия обобщения:
Целевой концепт С содержится в данном пространстве Н.
Если мы рассмотрим обучающий алгоритм L для выбора определенных объектов Х. Пусть С – произвольный концепт, определенный на тех примерах, которые у нас имеются. Dc = {x, C(x)} будет произвольный набор обучающих примеров с целевым концептом С. Пусть L(xi, Dc) обозначает классификацию xi по L после обучения на данных Dc, тогда inductive bias алгоритма обучения L – это минимальный набор предубеждений В такой, что для любого целевого концепта С и обучающего примера Dc будет иметь вид:
где A|- В значит А логическое следует B.
Обучение без предубеждений не способно делать вывод за пределами рассмотренных примеров. Все нерассмотренные примеры будут хорошо расклассифицированы половиной гипотез пространства версий, и расклассифицированы ошибочно другой половиной. Обучение без предубеждений не может делать индуктивные скачки, чтобы классифицировать невидимые примеры.
8. Основні особливості алгоритмів індуктивного навчання концептам;
Concept Learning – это выведение функции, которая имеет булевы значения, целевую функцию и примеры.
Candidate Elimination: манипулирует граничным представлением пространства версий, чтобы оно было совместимо со всеми прежними обучающими примерами + новым. Алгоритм не устойчив к зашумленным данным. Если приходит ошибочный обучающий пример, то происходит истощение пространства версий, что результируется в потере верхней или нижней границы.
Find-S: Целевой концепт должен быть представлен в пространстве гипотез и все примеры, которые являются негативными, влекут за собой другие знания. Ищет в пространстве гипотез от частного к общему наиболее частную гипотезу, совместимую с обучающими примерами, игнорируя отрицательные, не обязательно выдает окончательный концепт, не сигнализирует о том, что обучающие примеры могут быть несовместимыми (противоречивыми).
List-then-Eliminate: выбирает все гипотезы из пространства гипотез, охватывающие обучающие примеры, выдает пространство версий. Недостаток в том, что ввиду обработки всех гипотез он является сложным для вычисления.
Алгоритмы Concept Learning характеризуются простотой реализации и высокой скоростью обучения. Но они не гарантируют получение в результате окончательного концепта. Данные алгоритмы не работают на зашумленных и противоречивых данных, т. к. это может привести к неверному результату и истощению пространства гипотез. Они способны классифицировать невидимые примеры только благодаря их неявному индуктивному предопределению для выбора одной гипотезы, не противоречащей другой.
9. Теорема подання простору версій (Version space representation theorem);
Пускай Х будет произвольным набором примеров, а Н набором гипотез булевых значений, определенных над X. Пусть C: X -> {0,1} будет произв. целевым концептом, опред. над X, и пусть D будет произв. набором учебных примеров {{x, c(x)}}. Для всех X, H, C и D, такой, что S и G четко определены.
Доказательство:
Для док-ва теоремы достаточно показать, что (1) каждый h, удовлетворяет правую сторону вышеуказанные выражения в пространстве версий, и (2) каждый член пространства версий удовлетворяет выражение справа. Пускай g произвольный член G, s произвольный член S, h произв. член H, такие что g >=g h >= g s. Тогда с определения S, s должно удовлетворять все позитивные примеры в D. Так как h >= g s, h должны удовлетворять все позитивные примеры в D. Так же по определению G, g не может удовлетворять любой негативный пример в D, и так как g >= g h, h не может удовлетворять любой негативный пример в D. Поскольку h удовлетворяет все позитивные примеры в D и не удовлетворяет негативные примеры в D, h входит в D и поэтому h входит в пространство версий. Это доказывает шаг (1). Аргументация для (2) сложнее. Это может быть доказано, если допустить что h в простр-ве версий (V S H,D) не удовлетворяет правую сторону выражения, что приведет к непоследовательности.
Идея: начиная с самой частной гипотезы, обобщаем ее каждый раз, когда ей не удается покрыть рассматриваемый положительный обучающий пример. На выходе: одна самая частная гипотеза совместимая с обучающей выборкой.
Инициализируем Н самой частной гипотезы из множества Н;
Цикл for each: положительного обучающего примера Х
For each ограничения атрибута ai в h
if ai в h не удовлетворяет примеру Х, тогда заменяем ai на следующее более общее ограничение, которое удовлетворяет примеру Х
Выдаем полученную гипотезу h.
Недостатки Find-S: Игнорирует отрицательные примеры, не обязательно выдает окончательный концепт, не сигнализирует о том, что обучающие примеры могут быть несовместимыми (противоречивыми).
Алгоритм работает с граничным (S и G) пространством версий. На каждом шаге получает границы, которые соответствуют новому пространству версий, совместимом со всеми предыдущими примерами и текущим новым обучающим примером.
На выходе алгоритма получаем пространство версий в компактном представлении.
Для положительного примера алгоритм при необходимости обобщает S-границу минимально для того, чтобы покрыть новый обучающий пример и остаться совместимой с предыдущими обучающими примерами. А также исключает те гипотезы в G-границе, которые не покрывают новый пример.
Для отрицательного примера алгоритм при необходимости конкретизирует G-границу минимально для того, чтобы она не покрывала новый пример, оставаясь совместимой с предыдущими, а также удаляет из S-границы гипотезы, которые ошибочно покрывают текущий негативный пример.
Алгоритм Candidate-elimination:
1. Инициализируем границу G максимально общей гипотезой, а границу S максимально частной гипотезой.
2. Цикл for each обучающих примеров:
if пример d положительный
- исключаем из границы G все гипотезы, несовместимые с примером d;
- for each гипотезы s в границе S, несовместимой с примером d:
- исключаем несовместимую гипотезу из границы;
- add в границу S все мин обобщения h гипотезы s, такие что совместимые с d и нек гипотезы в границе G являются более общими, чем гипотеза h;
- исключаем из полученной границы S все гипотезы, более общие, чем другие;
if пример d отрицательный
- исключаем из границы S все гипотезы, несовместимые с примером d;
- for each гипотезы g в границе G, несовместимой с примером d:
- исключаем несовместимую гипотезу из границы;
- add в G все мин конкретизации h гипотезы g, такие что совместимые с примером d и нек др гипотезы в границе S явл более частными, чем гипотеза h;
- исключаем из получ границы G все гипотезы, кот явл менее общими, чем др.
3. Выводим S и G.
Алгоритм не работает с зашумленными и противоречивыми данными. В случае противоречивых данных мы получим истощение пространства гипотез. Оно происходит, когда исчезает хотя бы одна из границ.
12. Виснаження простору версій;
Пространство версий - это набор всех гипотез, состоящих в тестовых данных.
Алгоритмы обучения концептам не работают с зашумленными или противоречивыми данными. В случае противоречивых данных мы получим истощение пространства версий. Оно происходит когда исчезает хотя бы одна из границ. Противоречивые примеры - это варианты шума, примеры с same значениями атрибутов, но с разными значениями классов.
13. Особливості побудови дерев рішень. + та -. Передумови застосування д. рішень;
Каждый внутренний узел соответствует атрибуту, каждая ветвь, выходящая из узла соответствует возможному значению атрибута. Каждый лист соответствует значению целевой функции или классу. Каждая ветвь представляет собой конъюнкцию, между ветвями установлено отношение дизъюнкции.
Основная рекурсивная процедура построения дерева:
-выбираем наилучший решающий атрибут для текущего узла;
-for each значения этого атрибута строим ветви и намечаем потомков;
-сортируем текущие обучающие примеры к намеченным потомкам;
-if в потомке все примеры одинаково классифицированы, ставим лист и останавливаемся,
else вызываем эту функцию для узла потомка.
На каждом шаге выбираем тот атрибут, который ведет к самому короткому дереву (индуктивное предубеждение).
Предпосылки использования деревьев решений:
- примеры описываются парами Атрибут – Значение;
- целевая функция принимает дискретные значения;
- может требоваться дизъюнктивная гипотеза в результате обучения;
- возможно небольшое зашумление обучающих примеров.
Достоинства метода:
- быстрый процесс обучения;
- генерация правил в областях, где эксперту трудно формализовать свои знания;
- извлечение правил на естественном языке;
- интуитивно понятная классификационная модель;
- высокая точность прогноза, сопоставимая с другими методами
Недостатки:
- Очень часто алгоритмы построения деревьев решений дают сложные деревья, которые "переполнены данными", имеют много узлов и ветвей. Такие "ветвистые" деревья очень трудно понять. К тому же ветвистое дерево, имеющее много узлов, разбивает обучающее множество на все большее количество подмн-в, сост. из все меньшего количества объектов.
Алгоритм индукции дерева решений ID3 – это жадный алгоритм, который строит дерево сверху вниз (от корня к листьям), в каждом узле выбирая атрибут, который наилучшим образом классифицирует локальные обучающие примеры. Этот процесс продолжается рекурсивно, пока дерево не будет идеально классифицировать все обучающие примеры, или пока не будут использованы все атрибуты.
Входные параметры: Examples – текущие обучающие примеры, целевой атрибут, Attributes – множество атрибутов-кандидатов.
Алгоритм ID3:
1. Создаем корневой узел дерева Root.
2. if все обучающие примеры отрицательные, возвращаем дерево, которое состоит из одного корня с листом «-».
3. if все обучающие примеры положительные, возвращаем дерево, которое состоит из одного корня с листом «+».
4. if множество Attributes пустое, возвращаем дерево, которое состоит из одного корня с пометкой, которая соответствует самому распространенному значению целевого атрибута в множестве Examples.
5. else: цикл:
-выбираем атрибут А из множества Attributes, который наилучшим образом классифицирует примеры Examples;
-ставим атрибут в текущий корень Root;
-for each возможного значения vi атрибута А:
- добавляем новую ветвь от корня Root, соответствующую проверке А= vi;
- выделяем Examplesvi – множество примеров, где А= vi;
- если множество Examplesvi пустое:
-тогда на конце этой ветви добавляем лист с пометкой, соответствующей самому распространенному значению целевого атрибута Examples;
-else на конце ветви строим поддерево ID3 (Examplesvi, целевой атрибут, {Attributes – А}).
6. Возвращаем Root.
Поиск в пространстве гипотез ID3 происходит от общего к частному.
Специфические характеристики:
+ Пространство гипотез ID3 является полным.
- ID3 поддерживает только одну общую гипотезу в процессе поиска.
- ID3 не позволяет возвращаться назад в процессе поиска.
+ ID3 исп мн-во обуч примеров в процессе поиска для принятия статических решений отн улучшения текущей гипотезы. Уменьшается риск принятия ошибочного решения.
15. Пошук в просторі гіпотез для алгоритмів дерев рішень;
Поиск в пространстве гипотез ID3 происходит от общего к частному.
Специфические характеристики:
+ Пространство гипотез ID3 является полным.
- ID3 поддерживает только одну общую гипотезу в процессе поиска. Например, он не может определить сколько альтернативных деревьев решений явл совместимыми с доступными обучающими данными.
- ID3 не позволяет возвращаться назад в процессе поиска.
+ ID3 исп мн-во обуч примеров в процессе поиска для принятия статических решений отн улучшения текущей гипотезы. Уменьшается риск принятия ошибочного решения.
16. Індуктивне упередження (inductive bias) алгоритму ID3;
Обучение с помощью дерева решений – это метод для аппроксимации дискретных значений целевой функции, в которой обученная функция представлена деревом решений. Обученные деревья могут быть также представлены как выборки с правил «если-то» для улучшения читабельности человека. Этот обучающий метод является самым популярным алгоритмом индуктивного вывода и был успешно применен для решения многих задач и проблем. Поиск в пространстве гипотез управляется IG в соответствии с индуктивное предубеждение, которое в ID3 такое:
-Короткие деревья предпочтительнее больших деревьев.
-Предпочтение деревьев, у которых атрибуты с наибольшим выигрышем в информации стоят ближе к корню.
Предпочтение более коротких гипотез более длинным-принцип Бритвы Оккама (на нем и основан метод IB в ID3). Его +: меньше коротких, чем длинных гипотез (короткая гипотеза, подходящая под данные вряд ли случайна, длинная – может быть случайна); -: сущ. Много путей определения маленьких наборов гипотез, и что особенного в маленьких наборах основанных на размере гипотез?
17. Методи відсікання гілок;
Сущ 2 м-да: м-д отсечения уменьшающей ошибки и м-д послед отсечения ветвей.
Метод отсечения уменьшающей ошибки
1) разделяем данные на обучающую выборку и выборку подтверждений;
2) do while (отсечение не ухудшает точность)
- оцениваем влияние отсечения каждого возможного узла (плюс все узлы идущие ниже) на точность дерева на выборке для подтверждений;
- жадно удаляем тот узел, удаление которого максимально повышает точность.
В результате этого метода получаем наименьшую версию самого точного поддерева.
Метод последующего отсечения ветвей (правил):
конвертируем полученное дерево в эквивалентное множество правил
сокращаем каждое правило независимо от остальных с помощью удаления любого условия, которое ведет к улучшению точности правила. На отдельной валидационной выборке. Делается в цикле.
Сортируем сокращенные правила согласно их точности и используем в таком порядке при классификации новых примеров.
Обратно дерево не получаем. При классификации находится первое подходящее правило и остальные уже не рассматриваются.
Положительные моменты конвертации дерева в набор правил перед отсечением: конвертация удаляет различия между атрибутами, стоящими ближе к корню и атрибутами, стоящими ближе к листьям; удобства использования в программных системах, многие из которых имеют встроенные механизмы работы с правилами
18. Метод відсікання гілок зі зменшенням помилки (reduced-error pruning);
Метод рассматривает каждый узел дерева, как кандидата на отсечение, которое состоит в удалении поддерева (для которого данный атрибут являлся корнем) и ставим туда лист, присваивая ему значение, которое наиболее часто встречалось в отсеченном поддереве. Узлы убираются только в случае, если дерево после отсечений такое же эффективное, как и до них. Это приводит к тому, что лист, поставленный в связи со случайной закономерностью в обучающей выборке скорее всего будет отсечен, потому что такие случайности вряд ли будут в проверочной выборке. Узлы отсекаются итерационно – всегда выбирается на отсечение тот узел, чье удаление наиболее увеличит аккуратность дерева на проверочной выборке. В результате этого метода получаем наименьшую версию самого точного поддерева.
Главный недостаток: когда данные ограничены, резервирование части данных под проверочную выборку уменьшает количество возможных обучающих примеров.
19. Метод подальшого відсікання гілок (rule-post prunning);
Шаги:
1.Выводим дерево решений из обучающей выборки, пока оно не покрывает всю выборку, допускаем избыточную подгонку.
2.Конвертируем полученное дерево в эквивалентное множество правил, создавая по правилу для каждого пути из корня в лист.
3.Отсекаем каждое правило, чье удаление ведет к улучшению оценочной точности.
4.Сортируем отсеченные правила по их оценочной точности и рассматриваем их в этой последовательности при классификации последующих примеров.
Оценка точности правила проводится либо по проверочной выборке. Обратно дерево не
получаем. При классификации находится первое подходящее правило и остальные уже не рассматриваются.
Положительные моменты конвертации дерева в набор правил перед отсечением: конвертация удаляет различия между атрибутами, стоящими ближе к корню и атрибутами, стоящими ближе к листьям; удобства использования в программных системах, многие из которых имеют встроенные механизмы работы с правилами; конвертация позволяет получить различия в контекстах, в которых узел дерева решений используется.
20. Надмірне підганяння (overfitting) в деревах рішень та методи боротьби з ним;
Гипотеза h приналд прост-ву гипотез Н является излишне подогнанной под обучающие данные, если существует альтернативная гипотеза h` из Н такая что ошибка h меньше, чем ошибка h` на обучающих примерах, но ошибка h` меньше h на всем распределении примеров.
Методы избежания излишней подгонки. Существует два подхода:
- мы прекращаем рост дерева перед достижением точки, когда оно отлично классифицирует обучающие примеры;
- строим полное дерево с излишней подгонкой, а затем отсекаем некоторые концы ветвей.
Второй подход показал себя на практике лучше, т.к. в первом сложно вычислить, когда точно следует прекратить рост дерева.
«Оптимальный» размер дерева может быть вычислен следующим образом:
-Измеряется точность дерева на обучающей выборке (классический вариант)
-Измеряется точность дерева на отдельной тестовой выборке
Использование принципа MDL (минимальной длины описания): минимизировать следующую сумму: размер дерева решений + размер ошибок этого дерева.
1-ый подход: прекращение роста дерева
1) Расщепление примеров по атрибуту дает принципиально различное число примеров по ветвям. В таком случае вместо атрибута ставится лист со значением целевой функции наиболее часто встречаемой у текущих примеров
2) ставим лист, если разница между примерами с различными классами является очень существенной
2-ой подход: метод отсечения уменьшающей ошибки
1) разделяем данные на обучающую выборку и выборку подтверждений;
2) do пока отсечение не ухудшает точность
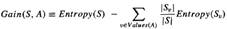 - оцениваем влияние отсечения каждого возможного узла (плюс все узлы идущие ниже) на точность дерева на выборке для подтверждений;
- оцениваем влияние отсечения каждого возможного узла (плюс все узлы идущие ниже) на точность дерева на выборке для подтверждений;
- жадно удаляем тот узел, удаление которого максимально повышает точность.
В результате этого метода получаем наименьшую версию самого точного поддерева.
Метод последующего отсечения ветвей
конвертируем полученное дерево в эквивалентное множество правил
сокращаем каждое правило независимо от остальных с помощью удаления любого условия, которое ведет к улучшению точности правила. На отдельной валидационной выборке. Делается в цикле.
Сортируем сокращенные правила согласно их точности и используем в таком порядке при классификации новых примеров.
Обратно дерево не получаем. При классификации находится первое подходящее правило и остальные уже не рассматриваются.
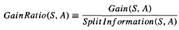 Положительные моменты конвертации дерева в набор правил перед отсечением: конвертация удаляет различия между атрибутами, стоящими ближе к корню и атрибутами, стоящими ближе к листьям; удобства использования в программных системах, многие из которых имеют встроенные механизмы работы с правилами
Положительные моменты конвертации дерева в набор правил перед отсечением: конвертация удаляет различия между атрибутами, стоящими ближе к корню и атрибутами, стоящими ближе к листьям; удобства использования в программных системах, многие из которых имеют встроенные механизмы работы с правилами
21. Обробка безперервних значень для побудови дерев рішень;
В случае поступления непрерывных значений в обучающей выборке для построения дерева решений необходимо произвести дискретизацию. Самый простой, но интеллектуальный способ равномерная дискретизация. Деление диапазона значений на равные интервалы. Для целевого атрибута чаще всего используют этот способ. «Интеллектуальная» дискретизация с учетом значений целевой функции (для определенных атрибутов). Такая дискретизация проводится с использованием IG. Она будет уменьшать энтропию наших примеров и следовательно приведет к более короткому дереву. Критерием IG вычисляется важность каждого возможного порога дискретизации. Порогами-кандидатами для которых подсчитывается IG являются те значения атрибута, где меняется значение класса. Т.е. среднее значение между значениями с разными классами.
Алгоритм:
1.сортируем примеры по возрастанию того атрибута, которому требуется дискретизация
2. Выбираем пороги-кандидаты
3. if(Q порогов-кандидатов) <= (Q требуемых дискретных значений атрибута -1), тогда применяем эти пороги без подсчета IG. Else подсчитываем IG для каждого порога-кандидата и отбираем те пороги, у которых IG наибольший.
4. Применяем отобранные пороги для дискретизации.
IG в данном случае вычисляется по формуле:
G(S)=E(D)- |D<S| * E (D<S) / |D| - |D>S| * E (D>S) / |D|
Где S-значение порога, E – значение энтропии.
22. Розрахунок основних інформ. показників для побудови дерев рішень (entropy, IG);
Обучение с помощью дерева решений – это метод для аппроксимации дискретных значений целевой функции, в которой обученная функция представлена деревом решений. IG- это мера, которая используется для определения наилучшего атрибутов, то есть тех, которые больше всего будет влиять на значение целевой функции. Для расчета IG также понадобится значение энтропии. Энтропия показывает насколько разбросаны примеры, относятся ли они к одному классу или к разным. (Другими словами: энтропия – это мера неопределенности информации и принимает значения от 0 до 1, а IG – это ожидаемое уменьшение энтропии).
Для функции булевых значений расчет энтропии производится по следующей формуле:
E(s) = -P- * log2P- –P+ log2P +, где р+ - отношение позитивных примеров к общ числу примеров, где р- - отношение отрицательных примеров к общ числу примеров.
Если кол-во классов больше чем 2, (записать самому – сумма по n ну и т.д., ты знаешь;)…)
IG: где |Sv| - побвыборка S, в которой у А есть значение, |S| - мощность множестваS, Values(A) – возможные значения атрибута А.
23. Альтернативні методи обрання атрибутів (split information, gain ratio)
Иногда приходится сталкиваться с атрибутами, принимающими множество значений. Например, атрибуты ДАТА (365 значений).Проблема: если у атрибута множество возможных значений велико, то мера IG будет всегда выбирать атрибут в качестве корневого. На практике такое дерево смысла иметь не будет. Решение: для того, чтобы избежать ошибки, необходимо выбирать атрибут другим методом, а не IG.
gain ratio выбраковывает такие атрибуты, вводя понятие split information, чувствительное к тому, насколько широко и однородно атрибут разбивает данные:
При этом С-подмножество примеров в результате разбиения S на С значений атрибута А.
SplitInformation - фактически энтропия S относительно значений атрибута А. Это противоречит предыдущему использованию энтропии, когда мы рассматривали только энтропию S относительно целевого атрибута, чье значение должно быть предсказано обученным деревом. Мера RatioGain определяется в понятиях как прошлой меры Gain, так и SplitInformation:
SplitInformation устраняет выделение атрибутов со многими однородно распространенными значениями.
Один момент, который проявляется при использовании GainRatio вместо Gain - то, что знаменатель может быть нулевым или очень малым, когда Si примерно равно S для одного из Si. Это делает GainRatio или неопределенным, или очень большим для атрибутов, которые могут иметь то же значение для почти всех членов S. Чтобы избежать отбора атрибутов исключительно исходя из этого, мы можем применить некоторую эвристику, например, сначала считать Gain каждого атрибута, затем применять GainRatio, рассматривая только те значения каждого атрибута, которые выше среднего Gain.
Методы обучения на примерах – это прямые подходы для вывода локальной аппроксимации целевой функции дискретных или непрерывных значений. Это ленивые методы, поэтому вывод целевой функции откладывается до прихода нового примера на классификацию. При приходе нового примера на классификацию, вычисляется его отношение ко всем хранящимся обучающим примерам. Исходя из этого назначается классификация/значение целевой ф-ции.
Включает в себя методы: case-based reasoning, которые используют более сложное, символическое представление примеров. Главное преимущество этих методов в том, что вместо того, чтоб оценивать целевой атрибут для всего пространства примеров, они могут оценивать его для каждого нового примера отдельно.
Недостатки: 1) затраты на классификацию нового примера могут быть высокими. Это происходит потому, что все рассчеты производятся в то же время, что и классификация. 2) IBL-методы, особенно методы ближайшего соседа, учитывают все атрибуты, когда извлекают схожие примеры. При этом целевой концепт может зависеть только от нескольких.
Это так же ленивый метод, который классифицирует новый пример анализируя схожие примеры и игнорируя полностью отличные, но, в отличии от методов instance-based learning, не использует Эвклидово пространство для представления примеров в виде вещественных точек. Этот метод обучения на примерах для обучающих данных, представленных символьными логическими описаниями. Существуют задачи обучения, когда обучающие примеры не представляются в виде пар атрибут-значение.
Области применения:
- Проектирование различных механических устройств на основе хранящейся библиотеки предыдущих примеров.
- Область юриспруденции. Поддержка принятия решений в судах на основе аналогий.
- В менеджменте проектов.
26. Теорема Байєса та її застосування в машинному навчанні;
В машинном обучении основной задачей является определение наилучшей гипотезы в пространстве гипотез H, учитывая обучающую выборку D. Под наилучшей гипотезой подразумевается наиболее вероятная гипотеза при имеющихся данных D и исходных знаниях о вероятности гипотезы H. Теорема Байеса обеспечивает вычисление такой вероятности гипотезы. Теорема Байеса дает возможность расчета апостериорной вероятности P(h|D), исходя из априорной P(h). Теорема Байеса, где D – примеры из обучающей выборки; h – пространство гипотез; P(D|h) — апостериорная вероятность того, что такие данные будут в выборке при условии существования гипотезы h; P(h) — априорная вероятность гипотезы h; P(D) — априорная вероятность всех примеров. Наиболее вероятная гипотеза h H, с учетом обучающей выборки D, называется максимальной апостериорной гипотезой.
В случае, когда P(h) — априорная вероятность гипотезы h для всех гипотез одинакова, возможно упрощение формулы, и для нахождения наиболее вероятной гипотезы нам потребуется только P(D | h). P(D | h) часто называют maximum likelihood гипотезой.(hML):
Вообще, теорема Байеса значительно шире, чем мы указали выше, она может применяться к любым выборкам, значения которых суммируются в единицу. Она широко употребляется для медицинского диагностирования, обработки спама и др. задач.
К числу основных байесовских методов классификации относятся:
1) Bayes Optimal Classifier – классификатор, который определяет наиболее вероятную классификацию примера, объединяя предусмотрение всех гипотез, взвешивая их по их апостериорным вероятностям;
2) Naive Bayes Classifier - вероятностный классификатор, основанный на применении Теоремы Байеса со строгими предположениями о независимости атрибутов;
3) Gibbs Algorithm – алгоритм, которые предполагает выбор наиболее вероятной гипотезы h из пространства гипотез H случайным образом;
4) Bayesian Belief Network – метод классификации, описывающий распределение вероятностей по определенному множеству переменных путем определения множества условно независимых предположений вместе с множеством условных зависимостей.
27. Обчислення умовних та безумовних ймовірностей;
Априорная или безусловная вероятность, связанная с некоторым событием A, представляет собой степень уверенности в том, что данное событие произошло, в отсутствии любой другой информации, связанной с этим событием. Термин априорная указывает на то, что предположение о классе объекта делается без каких либо предварительно заданных условий. Например, предположение о том, что плод – яблоко, может быть сделано безотносительно его формы, цвета и других признаков. Это и будет априорной вероятностью данного события. Фактически, априорные вероятности – это вероятности классов в множестве данных, она вычисляется как отношение числа примеров данного класса к общ числу примеров мн-ва. E.g. if из 100 примеров 25 имеют метку класса C, то априорная В класса будет 25/100=0,4.
|
|
|
|
|
Дата добавления: 2015-04-24; Просмотров: 651; Нарушение авторских прав?; Мы поможем в написании вашей работы!