КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Модули ответов 2 страница
|
|
|
|
Апостериорная вероятность - условная вероятность случайной переменной, которая назначается после принятия во внимание новой информации, имеющей отношение к данной переменной, т.е. это вероятность некоторого события А при условии, что произошло другое событие B. Например, при условии, что плод красный и круглый, мы с большой вероятности можем предположить, что это яблоко, т.е. апостериорная вероятность данного события будет P(яблоко|красный, круглый).
Формула апостериорной вероятности:
где D – примеры из обучающей выборки; h – пространство гипотез; P(D | h) — апостериорная вероятность того, что такие данные будут в выборке при условии существования гипотезы h; P(h) — априорная вероятность гипотезы h; P(D) — априорная вероятность всех примеров.
Наиболее вероятная гипотеза h H, с учетом обучающей выборки D, называется максимальной апостериорной гипотезой. В случае, когда P(h) — априорная вероятность гипотезы h для всех гипотез одинакова, возможно упрощение формулы, и для нахождения наиболее вероятной гипотезы нам потребуется только P(D | h). P(D | h) часто называют maximum likelihood гипотезой.(hML):
28. Оптимальний Байєсівський класифікатор;
Любой алгоритм, решающий эту задачу называется оптимальным байесовским классификатором.
Свойства оптимального классификатора:
-он действительно оптимален: никакой др метод не может в среднем превзойти его;
-он может даже классифицировать данные по гипотезам не содержащимся в Н.
-его обычно не получается эффективно реализовать, т.к. нужно перебирать все гипотезы, а их очень много.
Оптимальный Байесовский классификатор (ОБК) дает максимально вероятную классификацию. ОБК комбинирует предсказания всех альтернативных гипотез взвешенные по их апостериорным вероятностям. Для вычисления вероятной классификации нового примера:
Vj – все возможные значения целевой функции
hi – все гипотезы
P(Vj/ hi) – вероятность такого класса при гипотезе hi
P(hi/D) – вероятность того что гипотеза hi верна при наборе данных D
Характеристики ОБК:
+ ОБК выдает лучшую точность, которая может быть получена исходя из обучающих данных.
- ОБК может быть вычислительно сложным для применения (т.к. высчитываются все апостериорные вероятности из множества Н).
29. Алгоритм Гіббса;
Оптимальный Байесовский классификатор (ОБК) дает максимально вероятную классификацию. ОБК комбинирует предсказания всех альтернативных гипотез взвешенные по их апостериорным вероятностям. Для вычисления вероятной классификации нового примера:
Vj – все возможные значения целевой функции
hi – все гипотезы
P(Vj/ hi) – вероятность такого класса при гипотезе hi
P(hi/D) – вероятность того что гипотеза hi верна при наборе данных D
Алгоритм Гиббса является упрощением ОБК для уменьшения вычислительной сложности.
1 Выбираем гипотезу из пространства гипотез случайным образом согласно апостериорному распределению вероятностей P(h/D)
2 Используем эту гипотезу для классификации нового примера.
Ожидаемая ошибка классификатора Гиббса не более чем в 2 раза превышает ошибку ОБК.
30. Алгоритм наївного Байєсу;
Является одним из наиболее широко используемых на практике методов классификации; обладает достаточно высокой точностью; используется в областях, где природа данных точностная; очень простой метод.
Алгоритм (стремительный вариант): При обучении на вход подаются обучающие примеры;
Для каждого значения целевой функции Vj вычисляем: P(Vj)=доле примеров с классами Vj из всех обучающих примеров: для каждого значения атрибута аi каждого атрибута а вычисляем вероятность P(аi /Vj) вычисляется как доля примеров со значением атрибута равным аi и значением класса bj из всех примеров со значением класса bj. Функция классификации:
Возможен и ленивый вариант алгоритма, когда мы заранее не вычисляем никакие вероятности, а считаем необходимые вероятности на стадии классификации. Например, при поступлении примера
<Outlook=Sunny; Temp=Cool; Humid=Hight; Wind=Strong> мы должны вычислить все выражение для класса yes и для класса no, затем сравнить их. То есть вычисляем:
P(yes)*P(Sunny/ yes)*P(Cool/ yes)*P(Hight/yes)*P(Strong/ yes) и
P(no)* P(Sunny/ no)* P(Cool/no)* P(Hight/no)* P(Strong/no). Сравниваем результат.
Если данный класс и значение свойства никогда не встречаются вместе в наборе обучения, тогда оценка, основанная на вероятностях, будет равна нулю. Возникает проблема, так как при перемножении нулевая оценка приведет к потере информации о других вероятностях. Решение: ввести вместо нуля формулу: n/k(?),где n- кол-во примеров, k-возможные значения атрибута.
31. Застосування наївного Баєсівського класифікатору для класифікації текст док-ів;
Мы рассматриваем выборку Х, которая состоит из учебных примеров (в данном случае - текстовых документов). Дана также целевая функция f(x), область значений которой, - конечная область V. Нам нужно по этим учебным примерам научиться предугадывать целевое значение некоторого множества текстовых документов. Значение, по которому классифицируем, - например, тематика текстового документа. В этом случае будем руководствоваться ключевыми словами (не обязательно ключевые), - это значения атрибутов.
Пример: We want to classify this text.
a1 a2 a3 a4 a5 a6
И нужно определить его к классу "нравится"/"не нравится". Нумеруем слова, определяя их положение (позицию) в документе. А значение атрибута - само слово. Необходимо определить классификатор наивного Байеса:
Априорные знания: вероятности безусловные классов like и dislike:
p(dislike)=0.7 p(like)=0.3
При прихождении нового примера, воспользуемся формулой:
argmax - значит, что нужно найти класс, для которого вероятность является максимальной:
Vj - конкретное значение целевого атрибута.
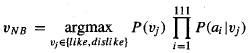 (вместо 111 – 6)
(вместо 111 – 6)
= argmax P(Vj) P(a1="We"|Vj) *... * P(a6="text"|Vj)
Классификация Наивного Байеса - это такая классификация, которая максимизирует вероятность обнаружения слов, которые встретились в документе.
Делаем допущение: каждое слово встречается в документе независимо от остальных! Это, конечно, неверно. Но, скажем, если у нас будет абзац со 111-ти слов и два значения целевого аттрибута и в английском языке 50000 слов, то нам придётся вычислять около 10 млн различных операций.
Также допущение, что каждое слово может встретиться в любом месте текста:
wk - какое-то слово из словаря.
P(ai=wk|Vj)=P(am=wk|Vj)
Также нам нужно решить, как мы будем вычислять вероятности для каждого слова в документе:
nk - сколько раз мы встретили классифицируемое слово.
n - общее кол-во слов в текстах всех документов. P=(nk + 1)/(n + |Vocabulary|)
|Vocabulary| - кол-во разных слов в документах.
Алгоритм ОБУЧЕНИЯ по Наивному Байесу:
1. Выбираем все слова, пунктуацию, другие эл-ты текстов-примеров.
Формируем словарь, в который пойдут РАЗНЫЕ слова и др. эл-ты, которые будут важны для классификации.
2. Вычисляем необходимые априорные вероятности принадлежности к определённому классу: P(Vj); а также вероятность встречи каждого слова, независимо от его положения для этого класса документов: P(wk|Vj).
Для каждого значения целевого атрибута, вычисляем подмножество документов из нашей учебной выборки, для примеров которой значение целевой ф-и является Vj.
Вычисляем априорную вероятность целевого значения:
docsj - подвыборка документов текущего класса
Examples - вся учебная выборка
P(Vj)=|docsj|/|Examples|
Берём один документ textj, который будет являться сцеплением всех документов из docsj.
n = общее число слов в этом объединённом документе (мощность textj).
Для каждого слова wk из нашего словаря Vocabulary, нужно вычислить nk - это кол-во раз, когда мы встретили это слово в textj.
Считаем условную вероятность слов:
P(wk|Vj)=(nk+1)/(n+|Vocabulary|)
Алгоритм КЛАССИФИКАЦИИ Наивного Байеса:
1. После того, как получили какой-то новый документ для классификации, вычисляем позиции слов в этом доке.
Необходимо возвратить наиболее вероятную классификацию по формуле с argmax (*), только теперь в произведении у нас i изменяется от 1 до кол-ва позиций классифицируемого документа.
32. Байєсівські ймовірнісні мережі;
Байесовская сеть — это ориентированный граф, в кот кажд вершина помечена кол-венной вероятностной информацией. Полная спецификация такой сети описана ниже.
Вершинами сети является множество случайных переменных. Переменные могут быть дискретными или непрерывными.
Вершины соединяются попарно ориентированными ребрами, или ребрами со стрелками; ребра образуют множество ребер. Если стрелка направлена от вершины X к вершине Y, то вершина X называется родительской вершиной вершины Y.
Каждая вершина Xi характеризуется распределением условных вероятностей
P (Xi| Parents (Xi)), кот кол-венно оценивает влияние родительских вершин на эту вершину.
Граф не имеет циклов, состоящих из ориентированных ребер (и поэтому является ориентированным ациклическим графом (Directed Acyclic Graph — DAG)).
Топология сети (множество вершин и ребер) показывает отношения, определяющие условную независимость, которые проявляются в данной проблемной области, в том смысле, который вскоре будет точно сформулирован. Интуитивный смысл стрелки в правильно составленной сети обычно состоит в том, что вершина X оказывает непосредственное влияние на вершину Y. Для специалиста в проблемной области задача определения того, какие непосредственные влияния существуют в этой проблемной области, обычно является довольно легкой; действительно, она намного легче по сравнению с фактическим определением самих вероятностей. После того как составлена топология байесовской сети, остается только указать распределение условных вероятностей для каждой переменной с учетом ее родительских переменных.
Байесовская вероятностная сеть - направленный ациклический граф, представляющий совместное распределение случайных переменных. Применение байесовских сетей позволяет ослабить требование к условной независимости признаков, которое ограничивает применение простого классификатора Байеса. Каждый узел графа представляет собой случайную переменную, т.е. признак или атрибут классифицируемого объекта, а дуги – зависимости между ними. Если дуга графа проходит из вершины A в вершину B, то A называют предком B, а B – потомком A. Иными словами, байесовская сеть работает по принципу: каждая переменная зависит только от непосредственных родителей.
Таким образом, граф описывает ограничения на зависимость переменных друг от друга. Его структура и условные распределения узлов однозначно описывают совместное распределение всех переменных, что позволяет решать задачу классификации как определения значения переменной класса, для которого ее условная вероятность при заданных значениях признаков будет максимальной.
33. Об’єднаний розподіл ймовірності в Байєсівських ймовірнісних мережах;
Если ребро выходит из вершины A в вершину B, то A называют родителем B, а B называют потомком A. Множество вершин-предков вершины Yi обозначим как parents(Yi).
Если у вершины Yi нет предков, то его локальное распределение вероятностей называют безусловным, иначе условным. Если значение в узле получено в результате опыта, то вершину называют свидетелем.
Любая байесовская сеть представляет собой полное описание рассматриваемой проблемной области. Каждый элемент в полном совместном распределении вероятностей (которое ниже будет сокращенно именоваться "совместным распределением") может быть рассчитан на основании информации, представленной в этой сети. Универсальным элементом в совместном распределении является вероятность конъюнкции конкретных присваиваний значений каждой переменной, такой как P(Yi=yi /\... Yn=yn). В качестве сокращенного обозначения для такой конъюнкции будет использоваться выражение P(Yi...Yn). Значение этого элемента задается следующей формулой:
где parents(Yi) обозначает конкретные значения переменных в множестве вершин Parents (Yi). Поэтому каждый элемент в совместном распределении представлен в виде произведения соответствующих элементов в таблицах условных вероятностей (Conditional Probability Table — СРТ) байесовской сети. Таким образом, таблицы СРТ обеспечивают декомпонованное представление совместного распределения.
34. Умовна незалежність в Баєсівських мережах;
Важное понятие байесовской сети доверия – это условная независимость случайных переменных, соответствующих вершинам графа. Две переменные A и B являются условно независимыми при данной третьей вершине C, если при известном значении C, значение B не увеличивает информативность о значениях A, то есть p (A | B, C) = p (A | C).
Граф кодирует зависимости между переменными. Условная независимость представлена графическим свойством d-разделенности.
Два узла направленного графа x и y называются d-разделенными, если для всякого пути из x в y (здесь не учитывается направление ребер) существует такой промежуточный узел z (не совпадающий ни с x, ни с y), что либо связь в пути в этом узле последовательная или расходящаяся, и узел z получил означивание, либо связь сходящаяся, и ни узел z, ни какой-либо из его потомков означивания не получил. В противном случае узлы называются d-связанными.
Свидетельства — утверждения вида «событие в узле x произошло». Например: «Компьютер не загружается».
Вершина является условно независимой от ее предшественников, если заданы ее родительские вершины. Как оказалось, можно также двигаться в другом направлении. Мы можем начать с "топологической" семантики, которая задает отношения условной независимости, закодированные в структуре графа, а из этой информации вывести "числовую" семантику. Топологическая семантика задается любой из приведенных ниже спецификаций, которые являются эквивалентными.
1. Вершина является условно независимой от вершин, не являющихся ее потомками, если даны ее родительские вершины.
2. Вершина является условно независимой от всех других вершин в сети, если даны ее родительские вершины, дочерние вершины и родительские вершины дочерних вершин, т.е. дано ее марковское покрытие (Markov blanket).
На основании приведенных утверждений об условной независимости и таблиц СРТ можно реконструировать полное совместное распределение; таким образом, "числовая" семантика и "топологическая" семантика являются эквивалентными.
35. Виведення за Баєсівською мережею;
Точный вероятностный вывод в байесовских сетях.
Основной задачей для любой системы вероятностного вывода является вычисление распределения апостериорных вероятностей для множества переменных запроса, если дано некоторое наблюдаемое событие, т.е. если выполнено некоторое присваивание значений множеству переменных свидетельства. Будем обозначать: X - переменная запроса; — множество переменных свидетельства,E1...Em; е — конкретное наблюдаемое событие; обозначает переменные, отличные от переменных свидетельства, Y1...Yn (иногда называемые скрытыми переменными). Таким образом, полное множество переменных определяется выражением 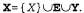 типичном запросе содержится просьба определить распределение апостериорных вероятностей P (X|e).
типичном запросе содержится просьба определить распределение апостериорных вероятностей P (X|e).
Приближенный вероятностный вывод в байесовских сетях
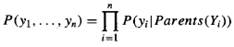 Исходя из того, что точный вероятностный вывод в больших многосвязных сетях является неосуществимым, важно предусмотреть методы приближенного вероятностного вывода. Рандомизированные алгоритмы выборки (называемые также алгоритмами Монте-Карло), обеспечивают получение приближенных ответов, точность которых зависит от количества сформированных выборок. В последние годы алгоритмы Монте-Карло нашли широкое распространение в компьютерных науках для получения оценочных значений величин, которые трудно вычислить точно.
Исходя из того, что точный вероятностный вывод в больших многосвязных сетях является неосуществимым, важно предусмотреть методы приближенного вероятностного вывода. Рандомизированные алгоритмы выборки (называемые также алгоритмами Монте-Карло), обеспечивают получение приближенных ответов, точность которых зависит от количества сформированных выборок. В последние годы алгоритмы Монте-Карло нашли широкое распространение в компьютерных науках для получения оценочных значений величин, которые трудно вычислить точно.
Методы вывода по Байесовской сети - это:
1. Построение формальной модели (графа) ПО и событий.
2. Получение вероятностей по опред. статистическим параметрам.
3.Узнать либо остальные (неданные) вероятности, либо пересчитать вероятности при условии изменения вероятности одного из узлов.
36. Ансамблі класифікаторів. Методи побудови;
Ансамбль классификаторов - это набор классификаторов, индивидуальные решения которых комбинируются некоторым образом (как правило, методами взвешенного или невзвешенного голосования) с целью расклассифицировать новые примеры.
Имеем обучающую выборку и определённый набор классификаторов (гипотез).
Чтобы при увеличении кол-ва классификаторов точность возрастала (ансамбль становился более эффективным, чем отдельные его классификаторов), нужно учитывать условия:
1. Каждый классификатор имеет вероятность правильно расклассифицировать больше, чем случайным образом (как правило, эта вероятность - 0.5).
2. Они должны быть разными (именно не одинакового типа, а по-разному классифицирующими).
Способы построения ансамблей:
1. Использование различных типов классификаторов, архитектуры их и параметров.
2. Манипулирование обучающими выборками.
3. Манипулирование входными атрибутами алгоритма (кол-во соседей, метрика расстояния; изменение кол-ва аттрибутов, влияющих на целевой класс и т.п.).
4. Манипулирование выходными классами.
5. Внесение некоторой случайности в метод обучения.
37. Алгоритм маніпулювання навчальною вибіркою AdaBoost для побудови ансамбля класифікаторів;
У нас есть одна обучающая выборка (первичная) - дублируем классифицируем по ней, определяем точность классификации, сопоставляем результаты с реальными значениями классов, и ставим коэф-ты для каждого примера (0 или 1 (для неправильных) на первой итерации) - для второй итерации берём неверно-классифицированные примеры.
Алгоритм AdaBoost.M1
Этап построения модели:
- Ставим одинаковый вес всем обучающим примерам.
- Для каждой итерации (t):
- Обучаемся на данной выборки.
- Вычисляем ошибку классификации e (часть верно расклассифицированных примеров).
- Останавливаем цикл только если ошибка равна 0 или больше, чем 0.5.
- Для каждого примера в датасете:
- Если пример расклассифицирован верно, то умножаем его вес на e/(1-e)
- Нормализуем веса всех примеров.
Классификация:
- Нулевой вес для всех классов.
- Для каждого из t классификаторов:
Прибавить -log(e/(1-e)) к весу классов, ПРЕДИКЕЙТЕД классификатором.
- Возвращаем класс с наибольшим весом.
(ЗДЕСЬ НЕ ТРЕБУЕТСЯ ГОЛОСОВАНИЯ КЛАССИФИКАТОРОВ)
Бустинг работает хорошо, если базовые классификаторы не имеют экспоненциальное возростание ошибки.
38. Алгоритм маніпулювання навчальною вибіркою Bagging для побудови ансамбля класифікаторів;
Генерируем обучающие выборки такой же размерности, как и обучающая, но рандомно и с возможностью повторений. Повторения влияет на различные классификаторы.
Этот алгоритм хорош, если мы хотим усреднить ошибку классификации различных классификаторов ансамбля.
Метод формирования ансамблей классификаторов с использованием случайной выборки с возвратом или бутстрепа. Название метода произошло от англ. bootstrap +aggregating – bagging. Он был предложен в 1994 году Лео Брейманом.
При формировании бутстрэп-выборок берется множество данных, из которого случайным образом отбирается несколько подмножеств, которые содержат такое же количество примеров, как и исходное. Но поскольку отбор производится случайно, набор примеров в этих выборках будет различным: некоторые из них могут быть отобраны по несколько раз, а другие – ни разу. Затем на основе каждой строится классификатор и их выходы комбинируются (агрегируются) путем голосования или простого усреднения. Ожидается, что результат будет намного точнее любой одиночной модели, построенной на исходном наборе данных.
Метод производит взвешенное голосование базовых алгоритмов, обученных на различных подвыборках данных, либо на различных частях признакового описания объектов.
Выделение подмножества объектов и/или признаков производится, как правило, сучайным образом.
Берётся обучающая выборка и рэндомом выбираем из неё кол-во примеров, равное мощности самой выборки, причем с повторениями. И так 10 раз получаем 10 разных обучающих выборок для обучения ансамбля, в каждой из которых могут отсутствовать некоторые примеры из исходного обучения ансамбля, а другие - повторяться.
39. Алгоритм маніпулювання навчальною вибіркою Cross-validation для побудови ансамбля класифікаторів;
Этим методом занимались Parmanto, Munro, Doyle
Заключается в построении обучающей выборки при помощи выбрасывания из различных непересекающихся подмножеств.
(Перекрестная проверка; кросс-валидация; метод случайных подпространств)
Метод формирования обучающего и тестового множеств для обучения аналитической модели в условиях недостаточности исходных данных или неравномерного представления классов. Для успешного обучения аналитической модели необходимо, чтобы классы были представлены в обучающем множестве примерно в одинаковой пропорции. Однако если данных недостаточно или процедура семплинга при формировании обучающего множества была произведена неудачно, один из классов может оказаться доминирующим. Это может вызвать «перекос» в процессе обучения и доминирующий класс будет рассматориваться как наиболее вероятный. Метод перекрестной проверки позволяет избежать этого.
В основе метода лежит разделение исходного множества данных на k примерно равных блоков, например k=5. Затем, на k-1, т.е. 4-х блоках производится обучение модели, а 5-й блок используется для тестирования. Процедура повторяется k раз, при этом на каждом проходе для проверки выбирается новый блок, а обучение производится на оставшихся.
Перекрестная проверка имеет два основных преимущества перед использованием одного множества для обучения и одного для тестирования модели. Во-первых, распределение классов оказывается более равномерным, что улучшает качество обучения. Во-вторых, если при каждом проходе оценить выходную ошибку модели и усреднить ее по всем проходам, то полученная оценка ошибки будет более достоверной. На практике, чаще всего выбирается k=10 (10-проходная перекрестная проверка), т.е. берем обучающую выборку, разбиваем на 10 частей. Поочередно выбрасываем по одной части - получаем 10 разных выборок (мощность каждой из которых равна 1/9 от мощности всей обучающей выборки) для обучения ансамбля классификаторов, когда модель обучается на 9/10 данных и тестируется на 1/10. Исследования показали, что в этом случае получается наиболее достоверная оценка выходной ошибки модели.
40. Маніпулювання цільовою функцією для побудови ансамблю класифікаторів;
МАНИПУЛИРОВАНИЕ ВЫХОДНЫМИ КЛАССАМИ
Есть опред. набор классов новостей, к примеру, 8. И разделим их на два как бы типа классов (4 из них - 0, а другие 4 - 1).
После обучения получим всего два класса: 0 и 1; расставим плюсы счётчикам каждого выходного класса классов.
Затем переформируем классы классов и опять прибавим счётчики (скажем, всем классам категории 1) - это для каждого нового обучаемого классификатора.
В результате получается один преобладающий целевой класс для конкретного примера, вместо голосования. Это аналогично перемешиванию обучающих выборок, но для целевых классов.
1.Философия как предмет: понятие, методы.
Слово «философия» в переводе с древнегреческого языка означает «любовь к мудрости». Впервые этот термин использовал древнегреческий ученый Пифагор (около 580-500 гг. до н.э.).
Основными методами философии (путями, средствами, с помощью которых осуществляется философское исследование) являются: Диалектика – метод философского исследования, при котором явления рассматриваются последовательно с учетом их внутренних противоречий, развития, причин и следствий; Метафизика – метод, противоположный диалектике, при котором объекты рассматриваются:обособлено, статично и однозначно; Догматизм – восприятие окружающего мира через призму догм – раз и навсегда принятых убеждений; Эклектика – метод, основанный на произвольном соединении разрозненных, не имеющих единого творческого начала фактов; Софистика – метод, основанный на выведении суждений из ложных, но некорректно поданных как истинные, посылок; герменевтика – метод правильного прочтения и истолкования смысла текстов, материализм действительность воспринимается как реально существующая, материя – как первичная субстанция, а сознание – ее модус – есть проявление матери, идеализм признание в качестве первоначала и определяющей силы идеи, а материи – как производной от идеи, ее воплощением, эмпиризм (в основе познавательного процесса, знания лежит опыт, получаемый преимущественно в результате чувственного познания), рационализм (истинное, абсолютно достоверное знание может быть достигнуто только с помощью разума без влияния опыта и ощущений).
|
|
|
|
|
Дата добавления: 2015-04-24; Просмотров: 1018; Нарушение авторских прав?; Мы поможем в написании вашей работы!