КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Ссылочная целостность
|
|
|
|
Целостность сущностей
Корпоративные ограничения целостности
Ограничения для доменов полей
Обязательные данные
Некоторые поля всегда должны содержать одно из допустимых значений, другими словами, эти поля не могут иметь пустого значения.
Каждое поле имеет свой домен, представляющий собой набор его допустимых значений.
Существует понятие "корпоративные ограничения целостности " как дополнительные правила поддержки целостности данных, определяемые пользователями, принятые на предприятии или администраторами баз данных. Ограничения предприятия называются бизнес-правилами.
Это ограничение целостности касается первичных ключей базовых таблиц. По определению, первичный ключ – минимальный идентификатор (одно или несколько полей), который используется для уникальной идентификации записей в таблице. Таким образом, никакое подмножество первичного ключа не может быть достаточным для уникальной идентификации записей.
Целостность сущностей определяет, что в базовой таблице ни одно поле первичного ключа не может содержать отсутствующих значений, обозначенных NULL.
Если допустить присутствие определителя NULL в любой части первичного ключа, это равносильно утверждению, что не все его поля необходимы для уникальной идентификации записей, и противоречит определению первичного ключа.
Указанное ограничение целостности касается внешних ключей. Внешний ключ – это поле (или множество полей) одной таблицы, являющееся ключом другой (или той же самой) таблицы. Внешние ключи используются для установления логических связей между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям ключа другой.
Между двумя или более таблицами базы данных могут существовать отношения подчиненности, которые определяют, что для каждой записи главной таблицы (называемой еще родительской) может существовать одна или несколько записей в подчиненной таблице (называемой также дочерней).
Существует три разновидности связи между таблицами базы данных:
· "один-ко-многим";
· "один-к-одному";
· "многие-ко-многим".
К недостаткам хранения ограничений целостности на сервере можно отнести:
· отсутствие у клиентского приложения возможности реагировать на некоторые ошибочные ситуации, возникающие на сервере при реализации тех или иных правил (например, ошибок при выполнении хранимых процедур на сервере);
· ограниченность возможностей языка SQL и языка хранимых процедур и триггеров для реализации всех возникающих потребностей определения целостности данных.
На практике в клиентских приложениях реализуют лишь такие правила, которые тяжело или невозможно реализовать с применением средств сервера. Все остальные ограничения целостности данных переносятся на сервер.
7) Вопрос: Унарные операции реляционной алгебры.
ОТВЕТ:
Операция проекции – это операция выбора столбцов из таблицы, представляющей отношение, по какому-либо признаку. А именно машина выбирает те атрибуты (т. е. буквально те столбцы) исходного отношения-операнда, которые были указаны в проекции.
Реляционная алгебра — замкнутая система операций над отношениями в реляционной модели данных. Операции реляционной алгебры также называют реляционными операциями.
Реляционная алгебра представляет собой набор таких операций над отношениями, что результат каждой из операций также является отношением. Это свойство алгебры называется замкнутостью.
Операции над одним отношением называются унарными, над двумя отношениями — бинарными, над тремя — тернарными (таковые практически неизвестны).
Пример унарной операции — проекция, пример бинарной операции — объединение.
N -арную реляционную операцию f можно представить функцией, возвращающей отношение и имеющей n отношений в качестве аргументов:
Поскольку реляционная алгебра является замкнутой, в качестве операндов в реляционные операции можно подставлять другие выражения реляционной алгебры (подходящие по типу):
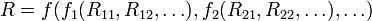
В реляционных выражениях можно использовать вложенные выражения сколь угодно сложной структуры.
Некоторые реляционные операции, в частности, операции объединения, пересечения и вычитания, требуют, чтобы отношения имели совпадающие (одинаковые) заголовки (схемы). Это означает, что совпадают количество атрибутов, названия атрибутов и тип (домен) одноимённых атрибутов.
Некоторые отношения формально не являются совместимыми из-за различия в названиях атрибутов, но становятся таковыми после применения операции переименования атрибутов.
8) ВОПРОС:Индексирование записей в реляционных таблицах.
ОТВЕТ:
Термин «индекс» тесно связан с понятием «ключ», хотя между ними есть и некоторое отличие.
Под индексом понимают средство ускорения операции поиска записей в таблице, а следовательно, и других операций, использующих поиск: извлечение, модификация, сортировка и т. д. Таблицу, для которой используется индекс, называют индексированной.
Индекс выполняет роль оглавления таблицы, просмотр которого предшествует обращению к записям таблицы. В некоторых системах, например Paradox, индексы хранятся в индексных файлах, хранимых отдельно от табличных файлов.
Варианты решения проблемы организации физического доступа к информации зависят в основном от следующих факторов:
• вида содержимого в поле ключа записей индексного файла;
• типа используемых ссылок (указателей) на запись основной таблицы;
• метода поиска нужных записей.
В поле ключа индексного файла можно хранить значения ключевых полей индексируемой таблицы либо свертку ключа (так называемый хеш-код). Преимущество хранения хеш-кода вместо значения состоит в том, что длина свертки независимо от длины исходного значения ключевого поля всегда имеет некоторую постоянную и достаточно малую величину (например, 4 байта), что существенно снижает время поисковых операций. Недостатком хеширования является необходимость выполнения операции свертки (требует определенного времени), а также борьба с возникновением коллизий (свертка различных значений может дать одинаковый хеш-код).
Для организации ссылки на запись таблицы могут использоваться три типа адресов: абсолютный (действительный), относительный и символический (идентификатор).
На практике для создания индекса для некоторой таблицы БД пользователь указывает поле таблицы, которое требует индексации. Ключевые поля таблицы во многих СУБД как правило индексируются автоматически. Индексные файлы, создаваемые по ключевым полям таблицы, часто называются файлами первичных индексов.
Индексы, создаваемые пользователем для не ключевых полей, иногда называют вторичными (пользовательскими) индексами. Введение таких индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. Индексные файлы, создаваемые для поддержания вторичных индексов таблицы, обычно называются файлами вторичных индексов.
9) ВОПРОС:Принципы концептуального проектирования баз данных.
ОТВЕТ:
Концептуальная модель ПО представляет собой описание структуры и динамики ПО, характера информационных потребностей пользователей в терминах, понятных пользователю и не зависимых от реализации БД. Это описание выражается в терминах не отдельных объектов ПО и связей между ними, а их типов, связанных с ними ограничений целостности и тех процессов, которые приводят к переходу предметной области из одного состояния в другое. Рассмотрим основные подходы к созданию концептуальной модели предметной области. Функциональный подход к проектированию БД Этот метод реализует принцип "от задач" и применяется тогда, когда известны функции некоторой группы лиц и/или комплекса задач, для обслуживания информационных потребностей которых создаётся рассматриваемая БД. Предметный подход к проектированию БД Предметный подход к проектированию БД применяется в тех случаях, когда у разработчиков есть чёткое представление о самой ПО и о том, какую именно информацию они хотели бы хранить в БД, а структура запросов не определена или определена не полностью. Тогда основное внимание уделяется исследованию ПО и наиболее адекватному её отображению в БД с учётом самого широкого спектра информационных запросов к ней. Проектирование с использованием метода "сущность-связь" Метод "сущность–связь" (entity–relation, ER–method) является комбинацией двух предыдущих и обладает достоинствами обоих. Этап инфологического проектирования начинается с моделирования ПО. Проектировщик разбивает её на ряд локальных областей, каждая из которых (в идеале) включает в себя информацию, достаточную для обеспечения запросов отдельной группы будущих пользователей или решения отдельной задачи (подзадачи). Каждое локальное представление моделируется отдельно, затем они объединяются. Выбор локального представления зависит от масштабов ПО. Обычно она разбивается на локальные области таким образом, чтобы каждая из них соответствовала отдельному внешнему приложению и содержала 6-7 сущностей. Сущность – это объект, о котором в системе будет накапливаться информация. Сущности бывают как физически существующие (например, СОТРУДНИК или АВТОМОБИЛЬ), так и абстрактные (например, ЭКЗАМЕН или ДИАГНОЗ). Для сущностей различают тип сущности и экземпляр. Тип характеризуется именем и списком свойств, а экземпляр – конкретными значениями свойств. Типы сущностей можно классифицировать как сильные и слабые. Сильные сущности существуют сами по себе, а существование слабых сущностей зависит от существования сильных. Например, читатель библиотеки – сильная сущность, а абонемент этого читателя – слабая, которая зависит от наличия соответствующего читателя. Слабые сущности называют подчинёнными (дочерними), а сильные – базовыми (основными, родительскими). Для каждой сущности выбираются свойства (атрибуты). Различают: Идентифицирующие и описательные атрибуты. Идентифицирующие атрибуты имеют уникальное значение для сущностей данного типа и являются потенциальными ключами. Они позволяют однозначно распознавать экземпляры сущности. Из потенциальных ключей выбирается один первичный ключ (ПК). В качестве ПК обычно выбирается потенциальный ключ, по которому чаще происходит обращение к экземплярам записи. Кроме того, ПК должен включать в свой состав минимально необходимое для идентификации количество атрибутов. Остальные атрибуты называются описательными и заключают в себе интересующие свойства сущности. Составные и простые атрибуты. Простой атрибут состоит из одного компонента, его значение неделимо. Составной атрибут является комбинацией нескольких компонентов, возможно, принадлежащих разным типам данных (например, ФИО или адрес). Решение о том, использовать составной атрибут или разбивать его на компоненты, зависит от характера его обработки и формата пользовательского представления этого атрибута. Однозначные и многозначные атрибуты (могут иметь соответственно одно или много значений для каждого экземпляра сущности). Основные и производные атрибуты. Значение основного атрибута не зависит от других атрибутов. Значение производного атрибута вычисляется на основе значений других атрибутов (например, возраст студента вычисляется на основе даты его рождения и текущей даты). Спецификация атрибута состоит из его названия, указания типа данных и описания ограничений целостности – множества значений (или домена), которые может принимать данный атрибут. Далее осуществляется спецификация связей внутри локального представления. Связи могут иметь различный содержательный смысл (семантику). Различают связи типа "сущность-сущность", "сущность-атрибут" и "атрибут-атрибут" для отношений между атрибутами, которые характеризуют одну и ту же сущность или одну и ту же связь типа "сущность-сущность". Каждая связь характеризуется именем, обязательностью, типом и степенью. Различают факультативные и обязательные связи. Если вновь порождённый объект одного типа оказывается по необходимости связанным с объектом другого типа, то между этими типами объектов существует обязательная связь (обозначается двойной линией). Иначе связь является факультативной.
10) ВОПРОС:Виды и особенности моделей данных
ОТВЕТ:
Общие положения. Ядром любой базы данных является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных -совокупность структур данных и операций их обработки.
СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или на некотором их подмножестве.
Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную.
Иерархическая модель данных. Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево).
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей.
К каждой записи базы данных существует только один (иерархический) путь от корневой записи.
Сетевая модель данных. В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
Реляционная модель данных. Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: каждый элемент таблицы - один элемент данных; все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину; каждый столбец имеет уникальное имя; одинаковые строки в столбце отсутствуют; порядок следования строк и столбцов может быть произвольным.
Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, а столбцы - атрибутам отношений, доменам, полям.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется простым ключом (ключевым полем). Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ.
Чтобы связать две реляционные таблицы, необходимо ключ первой таблицы ввести в состав ключа второй таблицы (возможно совпадение ключей); в противном случае нужно ввести в структуру первой таблицы внешний ключ - ключ второй таблицы.
11) Вопрос:Основные понятия иерархической модели данных.
ответ:
Иерархическая модель данных
Представляет сбой совокупность элементов, связанных между собой по определенным правилам. Иерархическая модель данных строится по принципу иерархии типов объектов, то есть один тип объекта является главным, а остальные, находящиеся на низших уровнях иерархии, – подчиненными. Между главным и подчиненными объектами устанавливается взаимосвязь «один ко многим». Иными словами, для данного главного типа объекта существует несколько подчиненных типов объектов. В то же время для каждого экземпляра главного объекта может быть несколько экземпляров подчиненных типов объектов.
Узлы и ветви образуют иерархическую древовидную структуру. Узел является совокупностью атрибутов, описывающих объект. Наивысший в иерархии узел называется корневым (это главный тип объекта). Корневой узел находится на первом уровне. Зависимые узлы (подчиненные типы объектов) находятся на втором, третьем и др. уровнях.
Объекты, связанные иерархическими отношениями, образуют ориентированный граф.
Основные понятия иерархической структуры:
§ Узел (элемент) – совокупность атрибутов данных, описывающих некоторый объект (на схеме это вершины графа). Каждый узел, находящийся на более низком уровне, связан только с одним узлом, находящимся на более высоком уровне. Узел может иметь только одного родителя. Иерархическое дерево имеет только оду вершину (корень), неподчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне.
§ Уровень.
§ Связь.
§ Достоинства: эффективное использование памяти и неплохие показатели временных затрат на выполнение операций; пригодны для формирования БД с теми данными, которые сами по себе имеют иерархическую структуру.
§ Недостатки: громоздкость; сложность физической реализации для больших древовидных структур.
§ Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
§
Атрибут (элемент данных) — наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
§ Запись — именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи — конкретная запись с конкретным значением элементов
§ Групповое отношение — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
§ Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой по иерархическому пути.
12) Вопрос:Операторы соединения в языке SQL (JOIN).
ОТВЕТ:
JOIN — оператор языка SQL, который является реализацией операции соединения реляционной алгебры. Входит в раздел FROM операторов SELECT, UPDATE илиDELETE.
Операция соединения, как и другие бинарные операции, предназначена для обеспечения выборки данных из двух таблиц и включения этих данных в один результирующий набор. Отличительной особенностью операции соединения является следующее:
· в схему таблицы-результата входят столбцы обеих исходных таблиц (таблиц-операндов), то есть схема результата является «сцеплением» схем операндов;
· каждая строка таблицы-результата является «сцеплением» строки из одной таблицы-операнда со строкой второй таблицы-операнда.
Определение того, какие именно исходные строки войдут в результат и в каких сочетаниях, зависит от типа операции соединения и от явно заданного условия соединения. Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
При необходимости соединения не двух, а нескольких таблиц, операция соединения применяется несколько раз (последовательно).
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 961; Нарушение авторских прав?; Мы поможем в написании вашей работы!