КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Пример,. Индексированные файлы
|
|
|
|
Индексированные файлы
Эффективность хешированных файлов
Основное положение эффективности хешированных файлов следующее. Все операции на хешированных файлах производятся в В раз быстрее (В – число бакетов), чем на файлах, организованных в виде кучи.
Пусть в файле храниться n записей, помещающихся в R блоков. Хеш-функция выбрана так, что число бакетов равняется B. Если при этом таблица бакетов находится в оперативной памяти, то потребуется следующее число доступов:
1) n/2BR при успешном поиске, а также удалении и модификации существующей записи;
2) n/BR при неудачном поиске, а также при проверке бакета перед вставкой, удалением и модификацией, если искомая запись отсутствует.
Основанием для таких расчетов служит тот факт, что в бакетах находится по n/R записей. Функция хеширования выбрана так, что записи в бакеты размещаются равномерно.
Если каталог бакетов находится на диске, то все количество доступов по всем операциям увеличивается на единицу, а в том случае, когда требуется внести изменения в каталог бакетов, на два.
Хорошо продуманная организация файлов с хешированным доступом требует лишь незначительного числа обращений к блокам при выполнении каждой операции с файлами. Если функция хеширования выбрана правильно и количество сегментов приблизительно равно количеству записей в файле, деленному на количество записей, которые могут уместиться в одном блоке, тогда средний сегмент состоит из одного блока. Если не учитывать обращения к блокам, которые требуются для просмотра таблицы бакетов, то типичная операция поиска данных по ключу потребует лишь одного обращения к блоку, а операции вставки, удаления или изменения потребуют двух обращений к блокам. Если среднее количество записей в бакете намного превосходит количество записей, которые могут уместиться в одном блоке, можно периодически реорганизовывать таблицу сегментов, удваивая количество бакетов и деля каждый из них на две части.
Еще одним распространенным способом организации файла записей является поддержание файла в отсортированном (по значениям ключей) порядке. Поля целого или десятичного типа сортируются обычным образом. Если поле имеет строковый тип, то используется лексикографическая сортировка.
пусть существуют две последовательности символов X1X2…Xk и Y1Y2…Ym. Где каждый X и Y – отдельный символ. Можно утверждать, что X1X2…Xk < Y1Y2…Ym в двух случаях:
1) k<m и X1X2…Xk = Y1Y2…Yk
2) для некоторого i£min(k,m) будет иметь место X1=Y1, X2=Y2,…,Xi-1=Yi-1 и код Xi меньше кода Yi. При этом в качестве кода может быть взят ASCII код символов.
Согласно этому принципу «свет» < «светлый» или «луг» < «лук».
Часто ключ состоит более чем из одного поля. В этом случае сортировка выполняется следующим образом. Производится упорядочивание по первому полю ключа. В результате получиться последовательность, состоящую из групп с одинаковыми значениями начала ключа. Затем внутри каждой группы производится упорядочивание по следующему полю ключа. При этом получаются большее количество более мелких групп. Процесс продолжается до тех пор, пока не образуются группы, включающие по одной записи.
В этом случае файл можно просматривать как обычный словарь или телефонный справочник, когда просматриваются лишь заглавные слова или фамилии на каждой странице. Чтобы облегчить процедуру поиска, можно создать второй файл, называемый разреженным индексом, который состоит из пар (x, b), где x - значение ключа, а b - физический адрес блока, в котором значение ключа первой записи равняется х. Разреженный индекс должен быть отсортирован по значениям ключей.
Пример,
на рисунке 7 показан основной файл, а так же соответствующий ему файл разреженного индекса.
Предполагается, что три записи основного файла (или три пары индексного файла) умещаются в один блок. Записи основного файла представлены только значениями ключей, которые в данном случае является целочисленными величинами.
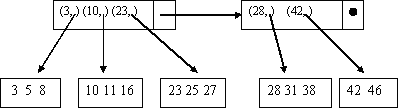
Рисунок 7 – Основной файл и его разреженный индекс
Чтобы отыскать запись с заданным ключом х, надо сначала просмотреть индексный файл, отыскивая в нем пару (x, b). В действительности отыскивается наибольшее z, такое, что z  x и далее находится пара (z, b). В этом случае ключ х оказывается в блоке b (если такой ключ вообще присутствует в данном файле).
x и далее находится пара (z, b). В этом случае ключ х оказывается в блоке b (если такой ключ вообще присутствует в данном файле).
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 578; Нарушение авторских прав?; Мы поможем в написании вашей работы!