КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
B-деревья
|
|
|
|
Плотное индексирование
Эффективность индексированных файлов
Пусть блок главного файла максимально вмещает E записей. Тогда в худшем случае блок будет вмещать e равное (E+1)/2 записей. Эта ситуация складывается при делении блока при вставке новой записи. Аналогично если блок индекса максимально вмещает D, тогда в худшем случае он будет содержать d равное (D+1)/2 записей. Если в файле содержится n записей, то можно сделать следующие выводы об эффективности индексированных файлов.
При двоичном поиске в индексированном файле потребуется 2+Log2(n/de) обращений к диску. Где n/de – максимальное количество блоков в индексе (логарифм из эффективности двоичного поиска). Еще два обращения для чтения и записи блока основного файла. При интерполирующем поиске потребуется 3+Log2Log2(n\de) обращений к диску.
Индексирование, рассмотренное выше, называется разреженным индексированием. Существует другой вид индексирования широко распространенный в реальных СУБД – плотное индексирование. В этом случае индексные файлы содержат пары вида (v,p), где первый элемент – значение ключа, а второй – адрес записи в основном файле с этим ключом. Такой подход не требует обязательного упорядочивания записей по индексируемому полю, а так же не обязательна уникальность ключа. Поэтому подход плотного индекса применим для ускорения поиска по любым полям, позволяя построить несколько независимых индексов.
При организации таких файлов скорость доступа будет 2+время поиска в файле индекса.
При увеличении числа блоков, занятых индексом в разреженных индексированных файлах, снижается эффективность работы. Структура, называемая В–деревом, позволяет избежать такого снижения путем построения индекса для индекса, и при необходимости далее, пока верхний индекс не будет помещаться в один блок. Таким образом, получается иерархическая структура индексов - рисунок 10.
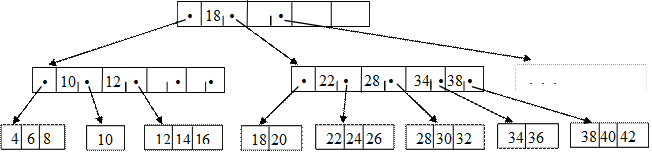
Рисунок 10 – В-дерево степени 5
В В-дереве узел может иметь много сыновей (на практике до тысячи). Количество сыновей (максимальное) определяет степень В-дерева.
Узел х, хранящий n[x] ключей, имеет n[x]+1 сыновей. Хранящиеся в х ключи служат границами, разделяющими всех потомков узла на n[x]+1 групп. За каждую группу отвечает один из сыновей х.
При организации В–деревьев не должно быть узлов, заполненных меньше, чем наполовину. Структура В–дерева отличается от простой иерархии индексов следующим соглашением: в индексных блоках В–деревьев значения ключей в первой записи пропускаются. При поиске полагают, что все значения, меньшие второго значения в индексе, покрываются отсутствующим первым значением ключа.
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 417; Нарушение авторских прав?; Мы поможем в написании вашей работы!
