КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
АЦП параллельного действия
|
|
|
|
В основе метода параллельного действия лежит принцип одновременного сравнения входного напряжения со всеми квантованными уровнями. Для реализации такого принципа преобразования АЦП в своей структуре должен содержать 2 n компараторов, где n – количество разрядов выходного двоичного кода (рис. 10.9). Каждый j -й компаратор DA 1. j срабатывает при j -ом квантованном уровне. Самый первый компаратор DA 1.1 имеет в качестве порогового напряжения квантованный уровень Q, второй компаратор DA 1.2 – квантованный уровень Q + Q =2 Q и т.д. Пороговые уровни задаются резистивным делителем, состоящим из 2 n +1 одинаковых резисторов R, делящим опорное напряжение UREF на m=2n равных значений. Если на входе j -ого компаратора амплитуда входного аналогового сигнала Uвх превышает текущий квантованный уровень, то на его выходе формируется логическая единица. В противном случае на выходе этого компаратора формируется логический ноль. Сигналы с выходов всех компараторов поступают на вход быстродействующего двоичного шифратора DD 1. На выходе этого шифратора формируется двоичный код, соответствующий максимальному номеру входа, на который поступает логическая единица с выхода соответствующего компаратора.
Так как все компараторы срабатывают одновременно, то преобразование осуществляется за один такт. Преимущество параллельного АЦП заключается в его максимальном быстродействии по сравнению с АЦП других типов. Максимальная частота fc.max преобразования таких АЦП может достигать сотен МГц, что делает их незаменимыми в радиотехнике. Между тем очевиден недостаток параллельных АЦП – слишком сложная аппаратная реализация, связанная с большим количеством компараторов и резисторов делителя, геометрически возрастающим с увеличением разрядности выходного кода. Поэтому, параллельные АЦП имеют обычно не высокую разрядность выходного кода.
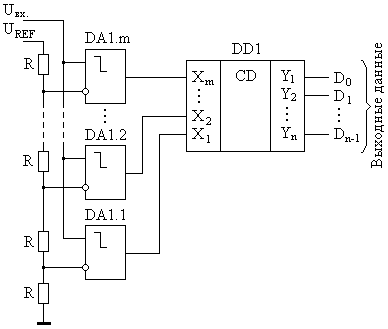
Рис. 10.9. Схема параллельного АЦП.
В заключение можно отметить, что функция АЦП в условных графических обозначениях задается комбинациями символов «D/A» или «L/#», а в маркировке микросхем – символами «ПВ». В последнее время широкое распространение получили АЦП и ЦАП с последовательной передачей выходного и входного кодов соответственно. Это означает, что передаваемый из преобразователя или в преобразователь двоичный код представляется не в параллельном, а в последовательном виде. Примерами подобных интерфейсов могут служить интерфейсы стандартов SPI и I2C. Протоколы этих интерефейсав будут рассмотрены в главе 12. Сейчас только отметим, что все разряды двоичного кода при последовательном протоколе обмена передаются поочередно путем их сдвига аналогично записи в последовательный регистр. Такая организация интерфейса обмена данными позволяет сократить число выводов микросхемы преобразователя. Например, существуют микросхемы 10-, 12-, и 16-разрядных АЦП и ЦАП всего с восемью выводами, включая выводы питания и управляющие. В структуре таких преобразователей присутствуют регистры сдвига, заполняемые или считываемые с помощью специальных синхронизирующих передачу импульсов «Clock». Разумеется, что такая организация обмена данными может снижать производительность с позиции скорости передачи и усложнять схему организации связи микросхемы АЦП/ЦАП с прочими устройствами. Но во многих случаях последовательная передача является преимущественной из-за малого количества внешних выводов микросхемы и, как следствие, малого размера микросхемы. Преобразователи с последовательной передачей кода широко используются при обработке сигналов в диапазоне звуковых частот, т.е. не превышающих десятки кГц.
Контрольные вопросы
1. Какие методы дискретизации аналоговых сигналов Вам известны?
2. Какие характеристика АЦП и ЦАП определяют их точность?
3. Какими недостатками обладает структура ЦАП со взвешенными резисторами?
4. Опишите принцип функционирования ЦАП с резисторной матрицей R -2 R.
5. Сформулируйте принцип аналого-цифрового преобразования методом последовательного счета.
6. Почему следящие АЦП обладают более высоким быстродействием по сравнению с АЦП развертывающего преобразования?
7. Опишите работу АЦП двухтактного интегрирования. Какие элементы необходимо заменить в схеме для реализации АЦП двухтактного интегрирования с большей разрядностью выходного кода?
8. АЦП каких типов следует выбрать при оцифровке аналоговых сигналов с частотами в диапазоне сотен МГц и в диапазоне единиц Гц?
9. Каким преимуществом и недостатком обладает последовательный канал передачи двоичного кода в ЦАП или из АЦП?
Глава 11. Программируемые логические интегральные схемы.
11.1. Принципы структурной организации программируемых логических интегральных схем.
Из рассмотренного в главе 8 принципа синтеза КЦУ, а в последствии и ПЦУ, следует, что любая система ФАЛ этих устройств может быть задана в виде ДНФ, т.е. в виде универсальной структурной записи с конкретизацией в каждом случае отдельных минтермов. Из сказанного правомерно допустить возможность создания универсальной элементной базы, реализующей произвольную систему ФАЛ цифрового устройства путем задания определенных внутренних связей между стандартными базовыми логическими элементами И и ИЛИ. Причем целесообразным является исполнение подобных универсальных элементов в виде отдельных интегральных схем.
Для задания внутренних связей между базовыми логическими элементами, позволяющих реализовывать необходимые ФАЛ, требуется осуществить предварительную настройку таких интегральных схем. Подобный процесс настройки носит название программирования. Поэтому, такие интегральные схемы получили название программируемых логических интегральных схем (ПЛИС). Обобщенная структурная схема ПЛИС приведена на рис. 11.1.
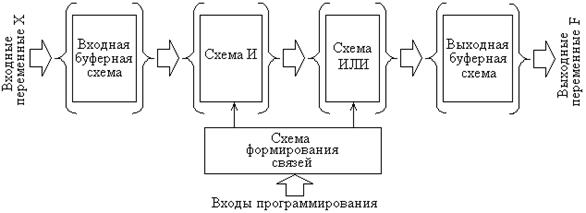
Рис. 11.1. Обобщенная структурная схема ПЛИС.
Отличие структуры ПЛИС от других цифровых микросхем заключается в наличии настраиваемых программным путем в общем случае множества элементов И и ИЛИ, называемых соответственно матрицами И и ИЛИ. Настройка этих матриц на выполнение конкретной ФАЛ осуществляется путем подачи на микросхему ПЛИС специальных сигналов программирования, подобных сигналам программирования микросхем постоянной памяти ПЗУ (об организации, схемотехнической реализации и особенностях программирования полупроводниковых запоминающих устройств будет изложено в следующей главе). В результате реализуются внутренние связи в матрицах, структурно задающие соединения отдельных элементов И и ИЛИ в соответствие с описывающей работу цифрового устройства системе ФАЛ. Входные и выходные переменные подаются на ПЛИС и снимаются с нее через буферные схемы, которые, как правило, кроме состояния логического нуля или логической единицы, могут принимать пассивное Z-состояние.
Первые ПЛИС в качестве программируемых содержали обычно обе матрицы - И и ИЛИ. Такие ПЛИС получили название программируемых логических матриц (ПЛМ), или в англоязычной аббревиатуре – PLA (Programmable Logic Array).
Фрагмент структуры ПЛМ, отражающий только программируемые матрицы И и ИЛИ, представлен на рис. 11.2. Косой линией принято обозначать программируемую электрическую связь. Изображенные на рис. 11.2 программируемые матрицы обладают электрическим контактом во всех пересечениях. Наличие контактов во всех пересечениях в матрицах характерно для новых, незапрограммированных ПЛИС. Также как и в случае с ПЗУ, программирование ПЛИС осуществляется разрушением электрического контакта в необходимых пересечениях, выполненного в виде плавкой перемычки или транзисторной МДП-структуры (см. следующую главу). В зависимости от технической реализации этого контакта ПЛИС бывают прожигаемые и перепрограммируемые.
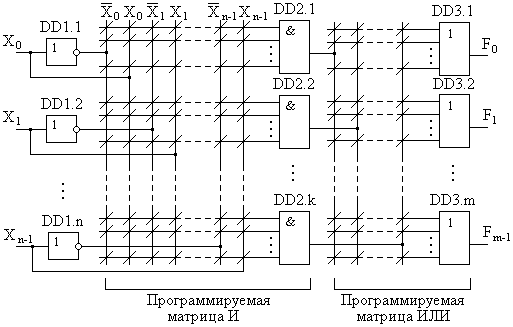
Рис. 11.2. Фрагмент структурной схемы ПЛМ.
Поскольку конституенты единицы ФАЛ в виде ДНФ образуются как прямыми значениями входных переменных, так и инверсными, то и в структуре ПЛИС предусмотрено наличие входных инверторов DD 1. Прямые и инверсные значения всех n входных переменных образуют столбцы программируемой матрицы И. Строки этой матрицы образуются n -входовыми элементами И DD 2. В общем случае, если предположить, что выходная функция F на всех наборах входных переменных принимает единичные значения, то таких элементов И по числу конституент единицы должно быть k =2 n. Синтез какой-либо схемы для такого случая является нецелесообразным, поскольку функция с единичными значениями на всех наборах является константой единицы и от входных переменных не зависит. В практических случаях выходная функция принимает единичные значения только на определенных наборах, а часто и вовсе является частично определенной. Поэтому ПЛИС содержат обычно количество k элементов И меньшее, чем 2 n. Выходы этих элементов образуют k столбцов программируемой матрицы ИЛИ, а их выходные значения соответствуют конституентам единицы функции F. Для возможности реализации системы ФАЛ из нескольких различных выходных функций, матрица ИЛИ содержит m k -входовых элементов ИЛИ DD 3. Каждый из этих элементов объединяет логическим сложением те конституенты единицы, которые входят в состав ДНФ реализуемой выходной функции F.
Недостатком структуры ПЛМ является слабое использование ресурсов программируемой матрицы ИЛИ. Поэтому была предложена более простая, но тем не менее, более эффективная архитектура программируемой матричной логики (ПМЛ). В английской терминологии ее обозначение записывается как Programmable Array Logic (PAL). Суть этой архитектуры заключается в использовании в качестве программируемой только матрицы И. Матрица ИЛИ является фиксированной. Пример упрощенной структуры ПМЛ представлен на рис. 11.3. На рисунке не раскрывается структура программируемой матрицы И по причине ее аналогии с рассмотренной матрицей И в структуре ПЛМ. Входные переменные, также как и в ПЛМ, в ПМЛ подаются в прямом и инверсном виде. Из рисунка видно, что входы элементов ИЛИ DD 3 являются не коммутируемыми. Таким образом, на каждый вход текущего элемента ИЛИ подается технологически определенный выход элемента И программируемой матрицы И.
Кроме элементов ИЛИ, в изображенной на рисунке структуре ПМЛ содержатся буферные элементы DD 4, позволяющие управляющим сигналом на входах E этих элементов, переводить соответствующие выходы F ПЛИС в высокоимедансное состояние. В этом случае эти выходы могут выполнять функции входов программируемой матрицы И. С этой целью выходы буферных элементов DD 4 соединены с матрицей И напрямую и через инверторы DD 5, т.е. организованы обратные связи. Если выход текущего элемента DD 4 находится в активном состоянии, то через цепи обратной связи значение выходной функции F подается обратно в матрицу И. Это позволяет реализовывать схемы не только КЦУ, но и ПЦУ. Элементы DD 3 и DD 4 ПМЛ образуют так называемую макроячейку.
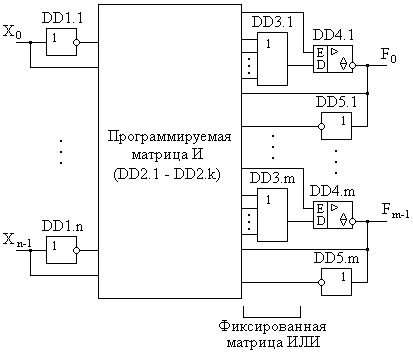
Рис. 11.3. Структурная схема ПМЛ.
Приведенная на рис. 11.3. структура характерна для классических ПМЛ. В настоящее время большее распространение получили интегральные схемы универсальной ПМЛ, принципиально отличающейся от классической только структурой макроячеек. Макроячейка универсальной ПМЛ содержит элемент Исключающее ИЛИ, один вход которого программно связан с нулевым потенциалом общего провода. Нарушение этой связи позволяет инвертировать значения выходных функций F, меняя, таким образом, логические уровни выходных сигналов. Кроме того, макроячейки универсальной ПМЛ содержат обычно D-триггеры-защелки, позволяющие синхронизировать выдачу информации на выходы и предоставляющие более широкие возможности при реализации ПЦУ.
Другим представителем ПЛИС, интенсивно развивающимся в настоящее время, особенно за рубежом, является комплексная ПЛИС. В английской терминологии она обозначается как CPLD (Complex Programmable Logic Devices). Такие ПЛИС содержат несколько логических блоков, каждый из которых представляет универсальную ПМЛ. Входы и выходы всех логических блоков объединяются в единую структуру программируемой коммутационной матрицей.
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 2716; Нарушение авторских прав?; Мы поможем в написании вашей работы!