КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Файловые структуры баз данных
|
|
|
|
Файлы и файловые структуры, широко применяемые практически во всех СУБД для хранения информации во внешней памяти, можно классифицировать следующим образом (рис. 30).
Так как файл — это линейная последовательность записей, то всегда в файл можно определить текущую запись, предшествующую ей и следующую за ней
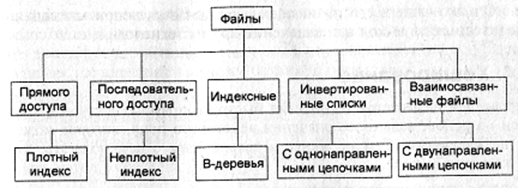
Рис. 30. Классификация файлов, используемых в системах баз данных
Для каждого файла в системе хранится следующая информация:
- имя файла;
- тип файла (например, расширение или другие характеристики);
- размер записи;
- количество занятых физических блоков;
- базовый начальный адрес;
- ссылка на сегмент расширения;
- способ доступа.
Известно, что в соответствии с методами управления доступом различают устройства внешней памяти произвольного и последовательного доступа.
На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа.
Вообще файлы могут иметь постоянную или переменную длину записи. Файлы с переменной длиной записи всегда являются файлами последовательного доступа. Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа, являются файлами прямого доступа.
Наиболее перспективным в системах баз данных считается использование файлов прямого доступа, поскольку посредством их обеспечивается наиболее быстрый доступ к произвольным записям. Для файлов с постоянной длиной записи физический адрес расположения нужной записи может быть вычислен по номеру записи. Но доступ по номеру записи в базах данных весьма неэффективен. Чаще всего в базах данных необходим поиск по ключу, для которого необходимо определить соответствующий ему номер записи, а следовательно, предпочтительнее связывать между собой не номер записи и физический адрес, а значение ключа записи и номер записи файла.
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение линейной обеспечивающей однозначное соответствие функции, которая по значению ключа однозначно вычисляет номер записи файла. Однако чаще всего такой подход оказывается неприемлемым и тогда приходится искать выход в привлечении других технологий.
- Хеширование
Хешированием называется технология быстрого прямого доступа к хранимой записи на основе заданного значения некоторого поля, которое может быть даже не ключевым.
Технология хеширования предполагает следующие моменты:
- Каждая запись БД размещается по адресу, вычисляемому путем применения к значению ключа некоторой функции свертки (хеш-функции), вырабатывающей значение меньшего размера. Свертка значения ключа применяется для того, чтобы избежать неэффективного использования дискового пространства. Достигается подобный эффект подбором специальной функции.
ПРИМЕЧАНИЕ ***Указанная неэффективность обязательно возникнет, если вместо свертки использовать значения непосредственно ключевого поля, которые разбросаны по домену, а если диапазон значений ключевого поля значительно шире диапазона имеющихся адресов, такой подход вообще оказывается неприемлемым. Например, ключевое поле содержит 7 значений в диапазоне 0-1000. В результате использования подходящей хеш-функции получим 7 ее значений в диапазоне 0-9**.
- Свертка значения ключа используется и для доступа к записи. Ее полученное значение берется в качестве адреса начала поиска, тем самым ограничивается время поиска (количество дополнительных шагов) для окончательного получения адреса. В самом простом, классическом случае, свертка ключа используется как адрес в таблице, содержащей ключи и записи.
Основным требованием к хеш-функции является равномерное распределение значения свертки, где одному значению хеш-функции может соответствовать одно значение ключа. Однако часто приходится допускать обратное. Если для нескольких значений ключа получается одна и та же свертка, то образуются цепочки переполнения. Подобные ситуации называются коллизиями. Значения ключей, которые имеют одно и то же значение хеш-функции, называются синонимами.
Главным ограничением этого метода является фиксированный размер таблицы. Если таблица заполнена слишком сильно или переполнена, то возникнет слишком много цепочек переполнения и утрачивается главное преимущество хеширования: доступ к записи почти всегда за одно обращение к таблице. Расширение таблицы требует ее полной переделки на основе новой (со значением свертки большего размера).
Следовательно, при использовании хеширования как метода доступа необходимо принять два независимых решения:
- выбрать хеш-функцию;
- выбрать метод разрешения коллизий.
Стратегии разрешения коллизий:
- Метод последовательного перебора
- Стратегия разрешения коллизий с областью переполнения
- Организация стратегии свободного замещения
5. Индексирование
Хотя технология хеширования и может дать высокую эффективность, но для ее реализации не всегда удается найти соответствующую функцию, поэтому при организации доступа к данным широко используются индексные файлы.
Основное назначение индексов состоит в обеспечении эффективного прямого доступа к записи таблицы по ключу. Различают индексированный файл и индексный файл (рис. 6). Индексированный файл — это основной файл, содержащий данные отношения, для которого создан индексный файл.

Рис. 31. Индексированный и индексный файлы
Индексный файл — это файл особого типа, в котором каждая запись состоит из двух значений: данных и указателя. Данные представляют поле, по которому производится индексирование, а указатель осуществляет связывание с соответствующим кортежем индексированного файла. Если индексирование осуществляется по ключевому полю, то индекс называется первичным. Такой индекс к тому же обладает свойством уникальности, т. е. не содержит дубликатов ключа.
Обычно индекс определяется для одного отношения, и ключом является значение простого или составного атрибута.
Основное преимущество использования индексов заключается в значительном ускорении процесса выборки данных, а основной недостаток — в замедлении процесса обновления данных. Действительно, при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс (а это дополнительное время) в индексный файл. Поэтому при выборе поля индексирования всегда важно уточнить, который из двух показателей важнее: скорость выборки или скорость обновления.
Индексы позволяют:
осуществлять последовательный доступ к индексированному файлу в соответствии со значениями индексного поля для составления запросов на поиск наборов записей;- осуществлять прямой доступ к отдельным записям индексированного файла на основе заданного значения индексного поля для составления запросов для заданных значений индекса;
- организовать запросы, не требующие обращения к индексированному файлу, а лишь приводящие к проверке наличия данного значения в индексном файле.
Поскольку при выполнении многих операций языкового уровня требуется сортировка отношений в соответствии со значениями некоторых атрибутов, полезным свойством индекса является обеспечение последовательного просмотра кортежей отношения в диапазоне значений ключа в порядке возрастания или убывания значений ключа.
Лекция 2.6. Защита баз данных;целостность и сохранность баз данных
1. Защита баз данных
2. Целостность и сохранность баз данных
3. Создание гиперссылки
|
|
|
|
|
Дата добавления: 2015-06-25; Просмотров: 3521; Нарушение авторских прав?; Мы поможем в написании вашей работы!