КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Теоретичні відомості. Мета роботи: одержати навички аналізу статистичних залежностей у вихідних даних
|
|
|
|
ДОСЛІДЖЕННЯ СТАТИСТИЧНОЇ ЗАЛЕЖНОСТІ ДАНИХ
Лабораторна робота № 3
Мета роботи: одержати навички аналізу статистичних залежностей у вихідних даних.
Завдання:
1. У модулі «Основні статистики й таблиці» відкрити вихідний файл даних.
2. Виконати статистичний аналіз залежності даних за такими методами:
– кореляційного аналізу;
– аналізу комбінаційної таблиці (крос-табуляції).
3. Оформити звіт про виконання роботи, який містить:
– основні числові результати (таблиці);
– графічні ілюстрації;
– висновки за результатами виконаного статистичного аналізу (характеристика всіх отриманих результатів).
Кореляційний аналіз. Кореляція являє собою міру залежності змінних. Найчастіше використовують коефіцієнт кореляції Пірсона r, який називають також лінійним коефіцієнтом, тому що за його допомогою вимірюють ступінь лінійних зв'язків між змінними. Додатне значення коефіцієнта означає, що між змінними є прямий зв’язок, від’ємне – зв’язок обернений, нульове значення – відсутність кореляції (зв’язку).
За допомогою пакета STATISTICA 6.0 можна обчислити й проаналізувати кореляційну матрицю вибраних змінних. Частіше будують квадратну матрицю. При цьому список змінних задають один раз. Кореляції обчислюють для всіх можливих сполучень змінних. Може бути задано прямокутну матрицю. При цьому варто задати список змінних для рядків і стовпців окремо. В отриманій кореляційній матриці кольором виділено значущі коефіцієнти при заданому рівні значущості (p < 0.05).
Після перегляду коефіцієнтів можна побудувати діаграми розсіювання вибраних змінних, на яких видно, як залежності двох змінних відповідають лінійній регресії. При цьому на екрані відображається лінійне рівняння залежності. Кореляцію вважають високою, якщо на графіку залежність можна зобразити прямою лінією, яку називають прямою регресії. Її звичайно будують методом найменших квадратів. Використання квадратів відстаней приводить до того, що оцінювання параметрів прямої залежить від випадкових викидів (які є нетиповими спостереженнями, що різко виділяються). Вони можуть істотно впливати на нахил прямої та значення коефіцієнта кореляції. Використовуючи графічні можливості, можна не враховувати ті точки, які найбільш віддалені від прямої.
Усі графіки розсіювання можна побачити на одному екрані, ви-бравши опцію «Матричний графік».
Якщо величину коефіцієнта кореляції піднести до квадрата, то отримане значення коефіцієнта детермінації r2 є часткою варіації, загальною для двох змінних.
Таблиці спряженості (комбінаційні або таблиці крос-табуляції). Таблиця спряженості відображає залежність між двома ознаками. Кожна таблиця містить частоти появи двох ознак, що набувають кількох значень: для однієї ознаки – це рядки, для іншої – стовпці. Останні стовпець і рядок таблиці – сумарні частоти.
Крос-табуляція – це такий процес об'єднання двох (або декількох) таблиць частот, де кожне поле у побудованій таблиці є комбінацією значень змінних. Дослідивши ці частоти, можна визначити зв'язок між табульованими змінними. Звичайно табулюються номінальні (дискретні) змінні або змінні з невеликим числом значень. Величини, розташовані на краях таблиці спряженості, – це звичайні значення частот розглянутих змінних, їх називають маргінальними.
Окремі рядки й стовпці таблиці зручно подавати у вигляді графіків. Таблиці з двома входами можна зобразити на тривимірній гістограмі. Інший спосіб візуалізації таблиць спряженості – побудова категоріальної гістограми, де кожну змінну відображено у вигляді індивідуальної гістограми на рівні іншої змінної.
У діалоговому вікні результатів можна спостерігати основні статистики для двовхідних таблиць:
1. Критерій хі-квадрат Пірсона 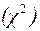 називають також лінійною кореляцією, тому що за його допомогою вимірюють ступінь лінійних зв'язків між змінними. Кореляція визначає ступінь, за якою значення двох змінних «пропорційні» одне одному. Додатне значення коефіцієнта означає, що між змінними є прямий зв’язок, від’ємне – обернений зв’язок, нульове значення – відсутність кореляції.
називають також лінійною кореляцією, тому що за його допомогою вимірюють ступінь лінійних зв'язків між змінними. Кореляція визначає ступінь, за якою значення двох змінних «пропорційні» одне одному. Додатне значення коефіцієнта означає, що між змінними є прямий зв’язок, від’ємне – обернений зв’язок, нульове значення – відсутність кореляції.
2. Критерій хі-квадрат, отриманий методом максимальної правдоподібності.
3. Виправлення Йєтса. Застосовують у тих випадках, коли таблиці містять тільки малі значення частот (менше десяти) й змінні є незалежними.
4. Точний критерій Фішера використовують тільки в таблицях 2x2. Критерій забезпечує обчислення точної ймовірності появи спостережуваних частот при відсутності зв'язку між змінними.
5. Критерій хі-квадрат Макнемара застосовують, коли частоти являють собою залежнівибірки, наприклад спостереження тих самих індивідуумів до початку експерименту й після нього. Обчислюють два значення хі-квадрат а: A/D і B/C, де А – значення верхнього лівого поля таблиці, B – верхнього правого, C – нижнього лівого; D – нижнього правого.
6. Коефіцієнт фі-квадрат.
7. Тетрахорична кореляція.
8. Коефіцієнт спряженості.
9. Коефіцієнт r-Спірмена відповідає кореляції Пірсона, але обчислюють його за рангами. Змінні вимірюють за порядковою шкалою.
10. Статистика тау-Кендала (τ) основана на ймовірності. Перевіряють, чи є розходження між імовірністю того, що спостережувані дані стосовно двох величин розташовано в заданому порядку, і ймовірністю, що їх розміщено в іншому порядку. Звичайно обчислюють два варіанти статистики тау- Кендала: 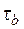 і
і 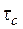 , які розрізняються тільки способом оброблення збіжних рангів. Якщо виникають розходження, то розглядають найменше з двох значень.
, які розрізняються тільки способом оброблення збіжних рангів. Якщо виникають розходження, то розглядають найменше з двох значень.
11. Коефіцієнт d-Сомера.
12. Гамма-статистика.
13. Коефіцієнти невизначеності.
|
|
|
|
|
Дата добавления: 2015-06-04; Просмотров: 629; Нарушение авторских прав?; Мы поможем в написании вашей работы!