КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Коды Шеннона - Фано
|
|
|
|
Одно и тоже сообщение можно закодировать различными способами. Наиболее выгодным является такой код, при использование которого на передачу сообщений затрачивается минимальное время. Если на передачу каждого элемента символа (например, 0 или 1) тратится одно и то же время, то оптимальным будет такой код, при использование которого на передачу сообщения заданной длины будет затрачено минимальное количество элементарных символов. Коды Шеннона – Фано являются префиксными, т.е. никакое кодовое слово не является префиксом любого другого. Данное свойство позволяет однозначно декодировать любую последовательность кодовых слов
Рассмотрим принцип построения одного из первых алгоритмов сжатия, который сформулировали американские ученые Шеннон и Фано на примере букв русского алфавита. Алгоритм использует коды переменной длины, т.е. часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся – кодом большей длины [4, 7].
Чтобы составить такой код, очевидно, нужно знать частоты появления букв в русском тексте. Эти частоты приведены в таблице 1 [4]. Буквы в таблице расположены в порядке убывания частот.
Таблица 1
Частота появления букв русского алфавита
| Буква | Частота | Буква | Частота | Буква | Частота | Буква | Частота |
| «−» о е а и т н с | 0,145 0,095 0,074 0,064 0,064 0,056 0,056 0,047 | р в л к м д п у | 0,041 0,039 0,036 0,029 0,026 0,026 0,024 0,021 | я ы з ъ, ь б г ч й | 0,019 0,016 0,015 0,015 0,015 0,014 0,013 0,010 | х ж ю ш ц щ э ф | 0,009 0,008 0,007 0,006 0,004 0,003 0,003 0,002 |
Пользуясь таблицей, можно составить наиболее экономичный код на основе соображений, связанных с количеством информации. Очевидно, код будет самым экономичным, когда каждый элементарный символ будет передавать максимальную информацию. Рассмотрим элементарный символ (т. е. изображающий его сигнал) как физическую систему с двумя возможными состояниями: 0 и 1. Информация, которую дает этот символ, равна энтропии этой системы и максимальна в случае, когда оба состояния равновероятны; в этом случае элементарный символ передает информацию 1 (двоичная единица). Поэтому основой оптимального кодирования будет требование, чтобы элементарные символы в закодированном тексте встречались в среднем одинаково часто.
Идея кодирования состоит в том, что кодируемые символы (буквы или комбинации букв) разделяются на две приблизительно равновероятные группы: для первой группы символов на первом месте комбинации ставится 0 (первый знак двоичного числа, изображающего символ); для второй группы − 1. Далее каждая группа снова делится на две приблизительно равновероятные подгруппы; для символов первой подгруппы на втором месте ставится 0; для второй подгруппы − единица и т. д.
Продемонстрируем принцип построения кода Шеннона − Фано на примере материала русского алфавита (см. табл. 1). Отсчитаем первые шесть букв (от «−» до «т»); суммируя их вероятности (частоты), получим 0,498; на все остальные буквы от «н» до «ф» придется приблизительно такая же вероятность 0,502. Первые шесть букв (от «−» до «т») будут иметь на первом месте двоичный знак 0. Остальные буквы (от «н» до «ф») будут иметь на первом месте единицу. Далее снова разделим первую группу на две приблизительно равновероятные подгруппы: от «−» до «о» и от «е» до «т»; для всех букв первой подгруппы на втором месте поставим нуль, а второй подгруппы − единицу. Процесс будем продолжать до тех пор, пока в каждом подразделении не останется ровно одна буква, которая будет закодирована определенном двоичным числом. Механизм построения показан на таблице 2, а сам код приведен в таблице 3.
Таблица 2
Механизм построения кода Шеннона – Фано на примере русского алфавита
| Двоичные знаки | |||||||||
| Буквы | 1й | 2й | 3й | 4й | 5й | 6й | 7й | 8й | 9й |
| - | |||||||||
| о | |||||||||
| е | |||||||||
| а | |||||||||
| и | |||||||||
| т | |||||||||
| н | |||||||||
| с | |||||||||
| р | |||||||||
| в | |||||||||
| л | |||||||||
| к | |||||||||
| м | |||||||||
| д | |||||||||
| п | |||||||||
| у | |||||||||
| я | |||||||||
| ы | |||||||||
| з | |||||||||
| ъ, ь | |||||||||
| б | |||||||||
| г | |||||||||
| ч | |||||||||
| й | |||||||||
| х | |||||||||
| ж | |||||||||
| ю | |||||||||
| ш | |||||||||
| ц | |||||||||
| щ | |||||||||
| э | |||||||||
| ф |
Таблица 3
Результат кодирования букв русского алфавита кодом Шеннона - Фано
| Буква | Двоичное число | Буква | Двоичное число | Буква | Двоичное число |
| «−» о е а и т н с р в л | к м д п у я ы з ъ, ь б г | ч й х ж ю ш ц щ э ф |
Пример 4. Запишем фразу «способ кодирования», используя код Шеннона - Фано.
Решение: Воспользуемся таблицей 3 и получим следующий результат:
(1001)с (110011)п (001)о (1001)с (001)о (111010)б (000)пробел
(10111)к (001)о (110010)д (0110)и (10100)р (001)о (10101)в
(0101)а (1000)н (0110)и (110110)я
Заметим, что здесь нет необходимости отделять друг от друга буквы специальным знаком, так как и без этого декодирование выполняется однозначно благодаря свойству префиксности: ни одна более короткая кодовая комбинация не является началом более длинной кодовой комбинации. Действительно, из таблицы 3 видно, что самыми короткими являются коды для символов «пробел» и «о». При этом не один другой более длинный код не имеет в начале последовательности 000 («пробел») и 001 («о»). То же самое можно наблюдать и для всех других двоичных последовательностей кода Шеннона – Фано, которые приведены в таблице 3.
Необходимо отметить, что любая ошибка при кодирование (случайное перепутывание знаков 0 или 1) при таком коде губительна, так как декодирование всего следующего за ошибкой текста становится невозможным.
Пример 5. Определим, является ли рассмотренный нами код оптимальным при отсутствие ошибок?
Решение: Найдем среднюю информацию, приходящуюся на один элементарный символ (0 или 1), и сравним ее с максимально возможной информацией, которая равна единице. Для этого найдем сначала среднюю информацию, содержащуюся в одной букве передаваемого текста, т. е. энтропию на одну букву (см. формулу 8):
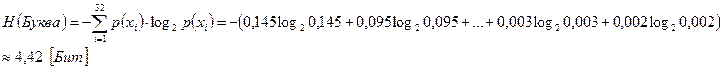
|
По таблице 1 определяем среднее число элементарных символов на букву:
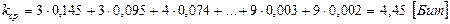
Далее рассчитаем информацию на один элементарный символ:
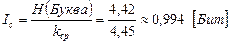
Таким образом, информация на один символ весьма близка к своему верхнему пределу единице, а данный код весьма близок к оптимальному.
В случае использования пятиразрядного двоичного кода информация на один символ:
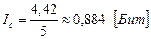
Пример 6. Пусть по каналу связи получено сообщение (слово на русском языке) закодированное кодом Шеннона – Фано: 10111001110010010010100.
Необходимо декодировать данную последовательность.
Решение: Процесс декодирования основывается на свойстве префиксности кода и выполняется слева на право. Из таблицы 3 видно, что минимальная длина кода составляет три бита. Отсчитает три бита от начала принятой кодовой комбинации, получим – 101. В таблице такой код отсутствует, поэтому добавляем еще один бит, получим – 1011. Данного кода также нет в таблице, следовательно, необходимо добавить еще один бит, получим комбинацию – 10111, которой соответствует буква «к». Кодовая комбинация 10111 исключается из принятой кодовой комбинации и заменяется исходным символом (буква «к»). Процесс декодирования остальных букв принятого сообщения выполняется аналогично.
Полный процесс декодирования приведен в таблице 4. Знак «-» в таблице означает, что в таблице 3 отсутствует выбранный код.
Таблица 4
Процесс декодирования сообщения
| Принятая кодовая последовательность | ||||||||||||||||||||||
| - | ||||||||||||||||||||||
| - | ||||||||||||||||||||||
| к | ||||||||||||||||||||||
| к | о | |||||||||||||||||||||
| к | о | - | ||||||||||||||||||||
| к | о | - | ||||||||||||||||||||
| к | о | - | ||||||||||||||||||||
| к | о | д | ||||||||||||||||||||
| к | о | д | - | |||||||||||||||||||
| к | о | д | е | |||||||||||||||||||
| к | о | д | е | - | ||||||||||||||||||
| к | о | д | е | - | ||||||||||||||||||
| к | о | д | е | р |
Итак, слово, полученное в результате декодирования принятой кодовой комбинации – «кодер».
|
|
|
|
|
Дата добавления: 2015-07-02; Просмотров: 5880; Нарушение авторских прав?; Мы поможем в написании вашей работы!