КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Неоднозначность КС-грамматик и языков
|
|
|
|
Выводы для практики
В результате операций над языками получается новое множество цепочек, то есть новый язык, который “собран из кусков”, состоит из частей исходных языков. С практической точки зрения очень важно, что язык можно разложить на более простые языки и формировать сложный язык на базе простых языков и операций над ними. Так если нам известен язык букв Lб ( любая латинская буква) и язык цифр Lц, то можно совершенно тривиально определить язык идентификаторов Lи конкатенацию языка букв и итерацию объединения языка букв и языка цифр:
Lи = Lб (LбÈ Lц ) *.
Отметим, что при реализации на ЭВМ программы синтаксического анализа различных языков лучше всего представлять в виде логических процедур-функций, дающих положительный ответ в случае принадлежности цепочки или ее фрагмента рассматриваемому языку и отрицательный при обнаружении ошибок. При таком построении итерация языка подменяется вызовом соответствующей процедуры внутри цикла; конкатенация - последовательным вызовом процедур анализа составляющих языков; объединение - альтернативным вызовом процедур; подстановка - заменой анализа терминала на процедуру анализа подставляемого языка.
Пример 5.4. Рассмотри простейший язык записи результатов шахматного матча для одного из его участников, цепочки которого имеют вид:
+ победы = ничьи - поражения;
где победы, ничьи и поражения представляются в виде целых констант без знака или имен переменных (идентификаторов). Данный язык
L = L+ Lблок L= Lблок L - Lблок L; ,
где L + = {+}, L = = {=}, L - = {-}, L блок = L и È L к, Lи = Lб (LбÈ Lц ) *, L к = Lц+, Lб = {a,b,...,y,z}, Lц = {0,1,...,9}, L;={;}.
Ниже представлена программа на языке Паскаль, реализующая синтаксический анализ цепочек предложенного языка. В ней выделены процедуры-функции анализа букв, цифр, идентификаторов, констант и блоков. Предусмотрен ввод серии строк для анализа и признаком конца тестирования данного анализатора служит ввод пустой строки. В процессе обработки строк языка осуществляется формирование массивов идентификаторов и констант, которые выводятся по завершении тестирования. Кроме фатальных ошибок, приводящих к завершению обработки текущей строки, предусмотрены сообщения об ошибках - предупреждениях о переполнении констант и идентификаторов. Позиции ошибок вместе с сообщениями о них формируют массив ошибок MEr, который выводится по завершению анализа строки.
program analppn;
uses TPCrt;
type Idn = string[8]; { тип для идентификатора }
CEr = 0..4; { код ошибки }
var
Str: string; { входная строка }
Lst: byte absolute Str; { количество символов в строке }
Ist: word; { индекс по входной строке }
Midn: array [0..100] of idn; { массив идентификаторов }
Mcon: array [0..100] of word; { массив констант }
Imi, Imc: word; { индексы массивов midn и mcon }
s: char; n: byte; { рабочие переменная }
MEr: array [0..4] of string; { строки сообщений об ошибках}
IEr: word; { индекс ошибок }
cod: CEr;
i: word;
const
{ сообщения в программе }
WroIdn = ' Количество символов в идентификаторе > 8-ми';
WroCon = ' Переполнение константы';
ErVic = ' Ошибка в победах';
ErDraw = ' Ошибка в ничьих';
ErDet = ' Ошибка в поражениях';
ErFin = ' Ожидается ";"';
OK = ' Строка синтаксически верна';
Inq = ' Введите строку >';
procedure Blank;
(* пропуск управляющих символов и пробелов *)
begin
while (Ist <= Lst) and (Str[Ist] <= #32) do inc(Ist)
end {Blank};
function Let (s:char): boolean;
(* контроль букв *)
begin
Let:=(UpCase(s) >= 'A') and (UpCase(s) <= 'Z')
end { Let };
function Dig (s: char; var n: byte): boolean;
(* контроль цифр *)
begin
if (s >= '0') and (s <= '9') then begin
n:=ord(s)-48 {-ord('0')}; Dig:=true end
else Dig:=false
end {Dig};
function Ident (var id: Idn): boolean;
(* анализ идентификатора *)
var
i: word;
begin
Blank; i:=Ist; id:=''; Ident:=false;
if Let(Str[Ist]) then begin
while Let(Str[Ist]) or Dig(Str[Ist],n) do begin
if (Ist-i) < 8 then id:=id+Str[Ist];
inc(Ist);
end;
if (Ist-i) > 7 then begin
inc(Ier); MEr[Ier]:=WroIdn; MEr[0,i+7]:='^'
end;
Ident:=true; Blank
end
end {Ident};
function Cons (var c: word): boolean;
(* анализ константы *)
var
ov: boolean; { признак переполнения }
begin Blank;
ov:=false; c:=0; Cons:=false;
while Dig(Str[Ist],n) do begin
Cons:=true;
if not(ov) then
if (c < 6553) or ((c=6553) and (n <= 5)) then c:=c*10+n
else begin
ov:=true; inc(Ier); MEr[Ier]:=WroCon; MEr[0,Ist]:='^'
end;
inc(Ist);
end; Blank;
end {Cons};
function Block (s: char): boolean;
(* анализ блока, начинающегося с символа-параметра s и
содержащего идентификатор или константу в качестве продолжения *)
begin
block:=true; Blank;
if Str[Ist] = s then begin inc(Ist);
if Ident(Midn[Imi]) then inc(Imi)
else
if Cons(Mcon[Imc]) then inc(Imc)
else begin MEr[0,Ist]:='^'; block:=false end
end
else begin MEr[0,Ist]:='^'; block:=false end
end {Block};
function Anal: CEr;
(* анализ строки c возвратом кода ошибки *)
begin
Anal:=0;
if not(Block('+')) then begin Anal:=1; exit end;
if not(Block('=')) then begin Anal:=2; exit end;
if not(Block('-')) then begin Anal:=3; exit end;
if Str[Ist] <> ';' then begin MEr[0,Ist]:='^'; Anal:=4 end
end {analizer};
procedure Parser;
(* анализ с выдачей сообщений об ошибках *)
begin
Ier:=0; Ist:=1;
FillChar(MEr[0,1],80,' '); MEr[0,0]:=#80;
cod:=Anal;
WriteLn(MEr[0]);
for i:=1 to Ier do
WriteLn(MEr[i]);
case cod of
0: WriteLn(OK);
1: WriteLn(ErVic);
2: WriteLn(ErDraw);
3: WriteLn(ErDet);
4: WriteLn(ErFin)
end
end {Parser};
begin
Imi:=0; Imc:=0;
while true do begin
WriteLn(Inq);
ReadLn(Str);
IF Lst = 0 then break;
Parser;
end;
if (Imi > 0) or (Imc > 0) then begin
WriteLn(' ИДЕНТИФИКАТОРЫ КОНСТАНТЫ');
i:=0;
repeat
if i < Imi then Write(Midn[i]:11)
else Write(' ':11);
if i < Imc then Write(Mcon[i]:15);
WriteLn; inc(i);
until (i >= Imi) and (i >= Imc)
end;
ReadKey;
end. ›
Напомним, что КС-грамматика G неоднозначна, если существует цепочка aÎL(G), имеющая два или более различных деревьев вывода. Если грамматика используется для определения языка программирования, желательно, чтобы она была однозначной. В противном случае программист и компилятор могут по разному понять смысл некоторых программ. Неоднозначность - нежелательное свойство КС-грамматик и языков.
Пример неоднозначной КС-грамматики арифметических выражений был рассмотрен в разделе 1.1. Но самый известный пример неоднозначности в языках программирования - это “кочующее else ”.
Пример 5.5. Рассмотрим грамматику с правилами вывода
S ® if b then S else S ½ if b then S ½ a
Эта грамматика неоднозначна, так как цепочка
if b then if b then a else a
имеет два дерева вывода, первое из которых (рис 5.6 (а)) предполагает интерпретацию
if b then (if b then a) else a,
а второе (рис 5.6 (б))-
if b then (if b then a else a)
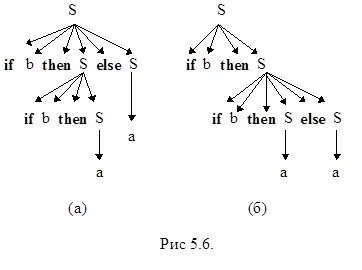 –
–
Хотелось бы иметь алгоритм, который по произвольной КС-грамматике выяснял, однозначна она или нет. Но, к сожалению, можно доказать, что проблема, однозначна ли КС-грамматика G, алгоритмически неразрешима. Хотя такого алгоритма нет, можно указать некоторые встречающиеся в правилах конструкции, приводящие к неоднозначности, которые можно распознать на практике и избегать при описании языков программирования.
Грамматика, содержащая правила A ® AA ½ a, неоднозначна, так как подцепочка AAA допускает два различных разбора (рис. 5.7).
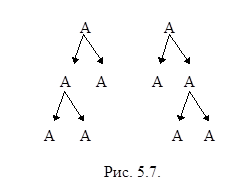
Здесь можно устранить неоднозначность, если вместо предложенных правил с двухсторонней рекурсией использовать одностороннюю, то есть использовать правила
A ® AB ½ B
B ® a
или правила
A ® BA ½ B
B ® a
Другой пример неоднозначности - правило A ® AaA, так как цепочку AaAaA можно получить по двум разным деревьям вывода. Пара правил A ® aA ½ Ab тоже создает неоднозначность, - цепочка aAb имеет два разных левых вывода A Þ aA Þ aAb и A Þ Ab Þ aAb.
Все перечисленные примеры, так или иначе связаны с двухсторонней рекурсией. Более тонкий пример - пара правил A ® aA ½ aAbA, по которым цепочка aaAbA имеет два вывода A Þ aAbA Þ aaAbA и A Þ aA Þ aaAbA. Если при двухсторонней рекурсии средством борьбы с неоднозначностью является устранение рекурсии с одной из сторон, то в последнем случае поможет левая факторизация.
Из приведенных примеров ясно, что определенная выше неоднозначность - это свойство грамматики, а не языка. Для некоторых неоднозначных грамматик можно построить эквивалентные им однозначные грамматики.
Пример 5.6. Рассмотрим грамматику из примера 5.5. Эта грамматика неоднозначна потому, что else можно ассоциировать с двумя различными then. Неоднозначность можно устранить, если связать else с последним из предшествующих ему then, как на рис. 5.6 (б). Для этого введем два нетерминала S1 и S2 с тем, чтобы S2 порождал только полные операторы вида if-then-else, а S1 - операторы обоих видов. Правила новой грамматики имеют вид
S1 ® if b then S1 ½ if b then S2 else S1 ½ a
S2 ® if b then S2 else S2 ½ a
Тот факт, что слову else предшествует только S2, гарантирует появление внутри конструкции then-else либо символа a, либо другого else. Таким образом, структура, изображенная на рис. 5.6 (а), здесь не возникает. –
КС-язык называется неоднозначным (или существенно неоднозначным), если он не пораждается никакой однозначной КС-грамматикой.
С первого взгляда не видно, существуют ли вообще неоднозначные КС-языки, но нашим следующим примером и будет такой язык.
Пример 5.7. Пусть L= {a i b j c k ½ i = j или j = k }. Этот язык неоднозначен, что можно строго доказать. Интуитивно же это объясняется тем, что цепочки с i = j должны порождаться группой правил, отличных от правил, порождающих цепочки с j = k. Тогда, по крайней мере некоторые из цепочек с i = j = k должны порождаться обеими механизмами. Одна из КС-грамматик, порождающих L, такова:
S ® AB ½ DC
A ® aA ½ e
B ® bBc ½ e
C ® cC ½ e
D ® aDb ½ e
Ясно, что она неоднозначна и на рис. 5.8 представлены два дерева вывода цепочки aabbcc. ›
Проблема, порождает ли данная КС-грамматика однозначный язык (т.е. существует ли эквивалентная ей однозначная грамматика), алгоритмически неразрешима. Но для некоторых больших подклассов КС-языков известно, что они однозначны. Именно к этим подклассам и относятся все созданные до сих пор языки программирования.

|
|
|
|
|
Дата добавления: 2015-06-27; Просмотров: 723; Нарушение авторских прав?; Мы поможем в написании вашей работы!