// PS - указатель текущего сравнения символа в подстроке
// PT - указатель текущего сравн. символа в тексте
// Start - указатель на начало сравнения в тексте
pS = 1; pt = 1; Start = 1
Start
While pT £ length (text) and pS £ length (substring) do
if text(pt) = substr(pS) then // есть очередное совпадение
pt = pt + 1; pS = pS + 1
else // начато сравнение заново с текущим символом
start = start +1; pt = start; pS = 1
end if
end while
if ps > length (substr)
then return (start) // совпадение найдено
else return (0) // совпадение не найдено
endif
Наилучший случай тот, где искомое слово встречается с самого первого символа строки и fАÚ (N) = NS сравнений, где NS - длина подстроки
Наихудший случай - при каждом проходе совпадают все символы, кроме последнего (например, в строке «хххх…х» искать «хххху»). В этом случае число сравнений fАÙ (N) = (NT- NS+1)× NS, где NT – длина строки текста.
Асимптотическая оценка сложности простого алгоритма – О(NT* NS).
Проблема стандартного алгоритма заключается в том, что он затрачивает много усилий впустую. Если сравнение начала подстроки уже произошло, то полученную информацию можно использовать для того, чтобы определить позицию следующего сравнения. Например, в вышеприведенном примере в искомой подстроке буква «Р» встречается 1 раз. Мы сделали 5 сравнений при первом проходе, получили отрицательный результат, следовательно, можно сразу сдвинуть точку Start на 5 (пять!) позиций вправо.
6.2. Алгоритм Кнута – Морриса – Пратта
Алгоритм Кнута – Морриса – Пратта основан на принципе конечного автомата. При построении конечного автомата для поиска подстроки легко построить переходы из начального состояния в конечное: эти переходы помечены символами подстроки.
Проблема возникает при попытке добавить другие символы, которые не переводят в конечное состояние.
В этом алгоритме состояния помечаются символами, совпадение с которыми в данный момент должно произойти. Из каждого состояния есть 2 перехода: один соответствует успешному сравнению, другой – несовпадению.
Успешное сравнение переводит нас в следующий узел автомата, а в случае несовпадения мы попадаем в предыдущий узел, отвечающий образцу.
При всяком переходе по успешному сравнению в конечном автомате происходит выборка нового символа из текста.
Переходы, отвечающие неудачному сравнению, не приводят к выборке нового символа; вместо этого они используют последний выбранный символ.
Более подробно алгоритм приведен в [2].
6.3. Алгоритм Бойера - Мура
Алгоритм Бойера – Мура осуществляет сравнение с образцом справа налево, а не слева направо. Таким образом можно осуществлять более эффективные прыжки.
Пример 6.3 Исходный текст «РЫБА У РЫБАКА», искомая подстрока «РЫБАК».
Р
ы
б
а
У
Р
Ы
Б
а
К
А
р
ы
б
а
к
1 проход, 1 сравнение
р
ы
б
а
к
2 проход, 1 сравнение
р
ы
б
а
к
3 проход, 5 сравнений
Итого:
7 сравнений, слово найдено
Мы сравниваем последние символы (Пробел и «К») и обнаруживаем несовпадение. Поскольку (Пробел) вообще не входит в образец, то можно сдвинуться в тексте на целых 5 букв (т.е. на длину подстроки).
На втором проходе последние символы текста «Б» и подстроки «К» вновь не совпадает, но буква «Б» – входит в образец. Следовательно, мы можем сдвинуться вправо только на 2 буквы, чтобы совпали буквы «Б» в тексте и в подстроке.
Затем начинаем сравнение справа и обнаруживаем полное совпадение. Таким образом, ответ получен всего за 7 сравнений.
Алгоритм Бойера -Мура обрабатывает образец двумя способами:
вычисляется величина возможного сдвига при несовпадении очередного символа (массив сдвигов);
вычисляется величина прыжка, выделяя в конце образца последовательности символов, уже появлявшихся ранее (массив прыжков).
При несовпадении очередного символа подстроки с очередным символом текста может осуществиться несколько возможностей. Сдвиг в массиве сдвигов может превышать сдвиг в массиве прыжков, а может быть и наоборот. (Совпадение этих величин – простейшая возможная ситуация). О чем говорят эти возможности? Если элемент массива сдвигов больше, то это означает, что несовпадающий символ оказывается ближе к началу, чем повторно появляющиеся завершающие символа строки. Если элемент массива прыжков больше, то повторное появление завершающих символов начинается ближе к началу подстроки, чем несовпадающий символ. В обоих случаях нам следует пользоваться большим из двух сдвигов, поскольку меньший сдвиг опять неизбежно приводит к несовпадению из-за того, что мы знаем о втором значении. (Более подробное описание алгоритма приведено в [2]).
6.4. Вопросы для самоконтроля
Определите число операций сравнения при поиске в строке «ТАРАКАН К РЫБАКУ» подстроки «РЫБАК» для простого алгоритма; для алгоритма Бойера-Мура.
7. Вычислительная геометрия
7.1. Основные понятия
Любая точка Р на плоскости описывается парой вещественных чисел (координат) Р(х, у) (рис. 7.1).
В то же время любую точку плоскости можно считать вектором, начало которого находится в точке (0,0), а конец – в точке Р (рис.7.2).
Для любых двух векторов определены следующие операции:
сумма: = + qx= vx+ wx; qy= vy+ wy;
разность: = - qx= vx- wx; qy= vy- wy;
скалярное произведение: * = vx* wx+ vy* wy .
Скалярное произведение обращается в 0, в том и только в том случае, когда, по крайней мере, один из векторов является нулевым или когда векторы и – ортогональны.
Для скалярного произведения справедливы соотношения:
v * w = vx* wx+ vy* wy= vcos (a)* w cos(b)+ v sin(a)* w sin(b)=| v |*| w |*cos(a-b)
При общей начальной точке у двух векторов скалярное произведение больше 0, если угол между векторами – острый, и меньше 0, если тупой.
7.2. Векторное произведение векторов
Векторным произведением векторов v и w называется вектор q, такой, что длина равна | v |*| w |sin j, а его направление перпендикулярно плоскости векторов и . Вектор = ´ направлен так, что из конца этого вектора кратчайший поворот от к виден происходящим против часовой стрелки.
Длина этого вектора равна площади параллелограмма, построенного на перемножаемых векторах (рис.7.3).
Учитывая, что векторы и лежат в координатной плоскости (х, у), то есть координата z =0, получаем: ´ = (vxwy-vywx) . Обратим внимание, что данное выражение является определителем матрицы
.
7.2.1. Ориентированная площадь треугольника
Найдем площадь треугольника DОАВ (рис.7.4 а).
Очевидно, что его площадь равна половине площади параллелограмма ОАСВ, а площадь последнего равна модулю векторного произведения векторов ОА и ОВ. То есть SOACB=AxBy-AyBx. Отсюда SOAB=(AxBy-AyBx). Площадь же треугольника ОВА SOBA=(BxAy-ByAx) – имеет другой знак! То есть в зависимости от порядка обхода точек (по часовой или против часовой стрелки) получается положительная или отрицательная величина, так называемая ориентированная площадь треугольника.
Пусть даны 3 точки р1(х1, у1), р2(х2, у2) и р3(х3, у3), определяющие вершины треугольника (рис. 7.4 б). Определим площадь этого треугольника, используя векторное произведение.
Совместим начало координат с первой точкой. Векторное произведение в этом случае равно определителю следующей матрицы:
Последнее выражение равносильно раскрытию определителя по первой строке матрицы:
= х1(у2- у3)+ у1(х3- х2)+ х2у3- х3у2 .
Если поменять порядок обхода точек (не р1р2р3, а р1р3р2), то мы получаем матрицы, определители которых противоположны по значению! При обходе против часовой стрелки получается положительная величина, а при обходе по часовой стрелке – отрицательная. Это свойство ориентированной площади треугольника очень часто используется при решении различных геометрических задач.
Пример 7.1 Дан многоугольник, состоящий из N вершин. Определить, является ли он выпуклым.
Одним из возможных решений данной задачи является следующее. Все треугольники выпуклого многоугольника, образованные тройками соседних вершин в порядке их обхода, имеют одну и ту же ориентацию (рис. 7.5 а). Как только ориентация меняется, меняется и знак ориентированной площади треугольника (рис. 7.5 б). (Следует учесть тот факт, что нахождение тройки вершин на одной прямой не нарушает факта выпуклости).
7.3. Задача о выпуклой оболочке
На плоскости задано множество S, состоящее из N точек. Требуется построить выпуклую оболочку, то есть определить точки, соединяя которые линиями, мы получаем охватывающий выпуклый контур.
7.3.1. Алгоритм Грэхема
Тройки последовательно идущих точек проверяются в порядке обхода против часовой стрелки. Если обход выполняется против часовой стрелки, то точки образуют левый поворот, если по часовой стрелке, то правый поворот. Так, например, для точек на рис.7.6 левый поворот образован точками (1,2,3), (2,3,4), (4,5,1), а правый – (3,4,5).
Основная идея алгоритма Грэхема:
найти внутреннюю точку t;
используя t как начало координат, отсортировать точки множества S по неубыванию в соответствии с полярным углом и расстоянием от t;
выполнить обход точек, исключая точки, образующие правый поворот.
Эту идею можно упростить – найти не внутреннюю точку, а самую левую верхнюю. Она заведомо принадлежит выпуклой оболочке. При этом значения углов вычисляются относительно этой точки.
Фрагменты алгоритма.
Grehеm (N, A, M)
// N – число точек
// A(N) array of Point – массив точек (координаты)
// M – количество точек в выпуклой оболочке
// Ls(N) – номера точек (при инициализации ls [ i ] =i)
// bb(N) – логический признак принадлежности точки выпуклой оболочке
// Rd(N) – оценки полярных углов
// 1 этап – поиск самой левой верхней точки
j1
for i=2 to N do
if (A[j].x>A[i].x) OR (A[i].x=A[j].x AND A[i].y>A[j].y)
then j=i
endif
endfor
// делаем крайнюю левую точкой первой
Swap (A[1], A[j])
Swap (Ls[1], Ls[j])
// на первом месте стоит левая верхняя точка
// далее определяем синусы углов. Углы принадлежат первой и четвер- // той четверти. Если углы задать в диапазоне [-90°, 90°] и отсортиро- // вать в порядке неубывания, то выпуклую оболочку можно построить // обходом против часовой стрелки
for i=2 to N do
dxA[i].x-A[1].x; dyA[i].y-A[1].y
Rd[i]dy/Sqrt(dx^2+dy^2)
еndfor
// далее некоторой сортировкой упорядочиваем углы. Только необходи- // мо не забывать одновременно с перестановкой ключа Rd [ i ] перестав- // лять и соответствующие элементы в массивах Ls и А
Sort(Rd, N)
// если число точек больше 3, то выполняем обход точек в поисках // выпуклой оболочки
If N>3 then Rounds
endif
end
// Процедура обхода точек
Procedure Rounds
MN // количество точек в выпуклой оболочке
LfA[1]; mdA[2]; rgA[3] // выбираем 3 точки обхода
Lfi1; mdi2; rgi3; // запоминаем индексы точек
While rgi<> 1 do
// определяем ориентированную площадь
RSorient(lf, md, rg)
If R<0 then // исключаем точку с номером mdi из выпуклой оболочки
Bb[mdi]false; M=M-1; mdirgi; mdrg; rgirgi mod N +1; rgA[rgi]
Else // переходим к следующей точке, если ориентация // нормальная
Lfimdi; lfmd; mdirgi; mdrg;
Rgirgi mod N+1; rgA[rgi]
еndif
еndwhile
еnd
7.3.2. Алгоритм Джарвиса
Данный алгоритм основан на следующем утверждении. Отрезок L, определяемый двумя точками, является ребром выпуклой оболочки тогда и только тогда, когда все другие элементы множества S лежат на L или с одной стороны от него.
Из этого «вытекает» следующая логика: N точек определяет порядка n2 отрезков. Для каждого из этих отрезков можно определить положение остальных (N -2) точек относительно него.
Таким образом, за время порядка O(N3) можно найти все пары точек, определяющих ребра выпуклой оболочки. Затем эти точки следует расположить в порядке последовательности вершин оболочки.
Джарвис заметил, что данную идею можно улучшить, если учесть следующий факт. Если установлено, что отрезок q1q2 является ребром оболочки, то должно существовать другое ребро с концом в точке q2, принадлежащее выпуклой оболочке. Уточнение этого факта приводит к алгоритму со временем работы O(N2).
7.3.3. Рекурсивный алгоритм
Множество S разделяется на 2 подмножества S1 и S2 примерно равной мощности, каждое из которых будет содержать одну из двух ломаных, соединение которых даст многоугольник выпуклой оболочки (рис. 7.7). Найдем точки w и r, имеющие наибольшую и наименьшую абсциссы соответственно. Проведем через них прямую L, тем самым разобьем множество точек на 2 подмножества – выше и ниже прямой L.
Определим точку h, для которой треугольник (hwr) имеет наибольшую площадь. Точка h гарантированно принадлежит выпуклой оболочке (так как если через h провести прямую, параллельную L, то выше точки h не окажется ни одной точки).
Через точки w и h проведем прямую L1, а через h и r – L2. Для каждой точки множества S1 определяется ее положение относительно этих прямых. Все точки, расположенные справа относительно этих прямых являются внутренними точками треугольника, и поэтому могут быть исключены для дальнейшей обработки.
Никакая из точек не лежит одновременно слева от L1 и слева от L2, следовательно, опять мы получаем 2 отдельных множества. Процесс продолжают до тех пор, пока слева от строящихся прямых типа L1 и L2 есть точки.
Разбиение множества на два подмножества выполняется с трудоёмкостью Θ(). Нет гарантии того, что после разбиения будут решаться две задачи с трудоёмкостью Θ() каждая. Это является следствием того, что 90% точек может оказаться в одном подмножестве, тогда как в другом подмножестве будет находиться лишь 10% всех точек. В среднем случае получим ` fa (n) = Θ(n× ln n).
До сих пор все рассмотренные нами алгоритмы решали поставленные задачи за разумное время. Порядок сложности всех этих алгоритмов был полиномиален. Иногда время их работы оказывалось линейным: при удвоении списка алгоритм работает вдвое дольше. Встречались и алгоритмы сложности N2 (сортировка): если длину входного списка удвоить, то время работы алгоритма возрастает в 4 раза. Сложность стандартного алгоритма умножения матриц равна O(N3), и при увеличении размеров матрицы вдвое такой алгоритм работает в 8 раз дольше. Хотя это и значительный рост, его все-таки можно контролировать.
В этом разделе будут рассмотрены задачи, сложность решения которых имеет порядок факториала (O(N!)), или экспоненты O(еlN). Другими словами, для этих задач неизвестен алгоритм их решения за разумное время.
Единственный способ найти разумное или оптимальное решение такой задачи состоит в том, чтобы догадаться до ответа и проверить его правильность.
Ранее рассмотренные алгоритмы относятся к так называемому Р -классу – классу задач полиномиальной сложности, или практически разрешимых.
Более точно задача относится к классу P, если существует алгоритм, правильно решающий эту задачу за время O (nk), где n – длина входа алгоритма, а k есть константа, не зависящая от n [1]. Реально степень k < 6, и мы можем получить решение задачи из класса P за приемлемое время даже для больших размерностей.
Новый рассматриваемый класс задач образует класс NP – недетерминированной полиномиальной сложности. Сложность всех известных алгоритмов, решающих эти задачи, либо экспоненциальна, либо факториальна. Например, для сложности 2 N при добавлении одного элемента время увеличивается вдвое. Это значительное возрастание времени при небольшом удлинении входа.
Класс NP был так же определен Эдмондсом, как класс задач, для которых возможна проверка полученного решения за время O (nk) (быстро проверяемые задачи). В 1971 году Кук ввел понятие NP – полных задач, как подкласса в NP – это задачи, к которым за время, полиномиальное относительно длины входа, могут быть сведены любые другие задачи из класса NP.
Словосочетание «недетерминированные полиномиальные», характеризующее задачи из NP класса, объясняется следующим двухшаговым подходом к их решению (рис. 8.1). На первом шаге имеется недетерминированный алгоритм, генерирующий возможные решения такой задачи (что-то вроде попытки угадать решение; иногда такая попытка оказывается успешной и мы получаем оптимальный или близкий к оптимальному ответ; иногда – безуспешной и ответ далек от оптимального). На втором шаге проверяется, действительно ли ответ, полученный на первом шаге, является решением исходной задачи.
Каждый из этих шагов по отдельности требует полиномиального времени. Проблема в том, что мы не знаем, сколько раз нам придется повторить оба этих шага, чтобы получить искомое решение.
Хотя оба шага – полиномиальны, число обращений к ним может оказаться экспоненциальным или факториальным.
Практически все задачи, представленные ниже, могут быть сформулированы как оптимизационные, либо как задачи о принятии решения. Целью оптимизационной задачи является конкретный результат, представляющий собой минимальное или максимальное значение. В задаче о принятии решения обычно задается некоторое пограничное значение, и нас интересует, существует ли решение большее или меньшее указанной границы.
Ответом в задачах оптимизации служит конкретный результат, а в задачах о принятии решения – «да» или «нет».
Ясно, что ответ в задаче о принятии решения зависит от выбранной границы – если эта граница очень велика (например, в задаче о коммивояжере она превышает суммарную стоимость всех дорог), то ответ («да») получить не сложно. Если эта граница чересчур мала (меньше стоимости любого пути между городами), то ответ («нет») также дается легко.
В остальных промежуточных случаях время поиска ответ велико и сравнимо со временем решения оптимизационной задачи.
8.1. Примеры NP -полных задач
8.1.1. Задача о коммивояжере
Задан набор городов и стоимость путешествия между любыми двумя из них. Нужно определить такой порядок, в котором следует посетить все города по одному разу и вернуться в исходный город, чтобы общая стоимость путешествия оказалась минимальной.
8 городов можно упорядочить 8!=40320 способами, а для 10 городов это число возрастает до 3 628 800. Поиск кратчайшего пути требует перебора всех этих возможностей. Предположим, у нас есть алгоритм, способный подсчитать стоимость путешествия через 15 городов в указанном порядке. Если за 1 секунду такой алгоритм способен пропустить через себя 100 вариантов, то ему потребуется больше 4-х веков, чтобы исследовать все возможности и найти кратчайший путь. Если в нашем распоряжении 400 таких компьютеров, то у них уйдет на это год, а ведь мы имеем дело всего лишь с 15 городами.
Ясно, что дешевле и быстрее путешествовать хоть как-нибудь, чем ждать, пока компьютер выдадут оптимальное решение. Можно ли найти кратчайший путь, не просматривая их все? До сих пор никому не удалось придумать алгоритм, который не занимается по существу просмотром всех путей.
Задача о коммивояжере может быть сформулирована как задача на графах. Каждый город можно представить вершиной графа, наличие пути между двумя городами – ребром, а стоимость путешествия – весом ребра.
Отсюда можно сделать вывод о том, что алгоритм поиска кратчайшего пути решает и задачу коммивояжера. Однако это не так. Какие два условия в задаче о коммивояжере отличают ее от задачи кратчайшего пути?
Во-первых, мы должны посетить все города, а алгоритм поиска кратчайшего пути дает лишь путь между двумя заданными городами. Если собрать путь из кратчайших кусков, то он будет проходить через некоторые города по несколько раз.
Во-вторых, требуется вернуться в начальную точку, что не надо в кратчайшем пути.
8.1.2. Задача о раскраске графа
Граф G =(V, E) представляет собой набор вершин V и набор ребер Е, соединяющих вершины попарно. Вершины можно раскрасить в разные цвета, которые обозначаются целыми числами. Необходимо раскрасить граф таким образом, чтобы концы каждого ребра были окрашены в разные цвета. Очевидно, что в графе с N вершинами можно покрасить все вершины в N различных цветов, но можно ли обойтись меньшим количеством? Каково минимальное количество цветов, необходимое для раскраски вершин? Можно ли раскрасить вершины в С или менее цветов?
У задачи раскраски графа есть практическое приложение – составление расписаний. Если каждая вершина графа обозначает читаемый в колледже курс, и вершины соединяются ребром, если есть студенты, слушающие оба курса, то получается весьма сложный граф.
Если предположить, что каждый студент слушает 5 курсов, то на студента приходится 10 ребер. Предположим, что на 3500 студентов приходится 500 курсов. Тогда у получившегося графа будет 500 вершин и 35000 ребер.
Если на экзамены отведено 20 дней, то это означает, что вершины графа должны быть раскрашены в 20 цветов, чтобы ни у одного из студентов не приходилось по 2 экзамена в день.
8.1.3. Раскладка по ящикам
Пусть у нас есть несколько ящиков единичной емкости и набор объектов различного размера S1,S2,..Sn. Найти наименьшее количество ящиков, необходимое для раскладки всех объектов, или (в другой постановке) можно ли упаковать все объекты в В или менее ящиков.
Эта задача возникает при записи информации на диски или во фрагментированной памяти компьютера; при эффективном распределении груза на кораблях; при вырезании кусков из стандартных порций материала по заказам клиентов.
Верхняя граница числа ящиков m равна n, т.е. mmax= n, если i, j Si+Sj>1. Нижняя граница m это mmin = 1, при условии ∑Si ≤1.
8.1.4 Упаковка рюкзака
Имеется набор объектов объемом S1,S2…Sn и стоимостью W1,W2,…Wn. Упаковать рюкзак объемом К так, чтобы его стоимость была максимальной, или – можно ли добиться того, чтобы суммарная стоимость упаковки была по-меньшей мере W.
Эта задача возникает, например, при выборе стратегии вложения денег: объемом здесь является объем различных вложений, стоимостью – предполагаемая величина дохода, а объем рюкзака – размер планируемых капитальных вложений.
8.1.5. Задача о суммах элементов подмножества
Пусть имеется множество объектов различных размеров S1,S2…Sn и некоторая положительная верхняя граница L. Найти набор объектов, сумма размеров которых наиболее близка к L и не превышает этой границы, или – существует ли набор объектов с суммой размеров L. Это – упрощенная версия задачи об упаковке рюкзака.
8.1.6. Задача о планировании работ
Есть набор работ, и известно время, необходимое для завершения каждой из них Т1, Т2…Tn., и сроки D1,D2…Dn, к которым эти работы должны быть обязательно завершены, а также штрафы Р1, Р2, Рn, которые будут наложены при незавершении работы установленные сроки.
Найти порядок работ, минимизирующий накладываемые штрафы, или в другой постановке – есть ли порядок работ, при котором величина штрафа будет не больше P.
8.2. Приближенные эвристические решения NР-полных задач.
Поскольку полиномиальные решения этих задач неизвестны, следует рассмотреть альтернативные возможности, дающие лишь достаточно хорошие ответы – приближенные решения.
8.2.1. Жадные приближенные алгоритмы
На каждой отдельной стадии «жадный» алгоритм выбирает тот вариант, который является локально оптимальным в том или ином смысле. Не каждый «жадный» алгоритм позволяет получить оптимальный результат в целом. Как нередко бывает в жизни, «жадная стратегия» обеспечивает лишь сиюминутную выгоду, в то время как результат в целом может оказаться неблагоприятным.
Существуют задачи, для которых ни один из известных «жадных» алгоритмов не позволяет получить оптимальное решение; тем не менее, имеются «жадные» алгоритмы, которые с большой вероятностью позволяют получать «хорошие» решения. Вообще говоря, если рассматриваемая задача такова, что единственным способом получить оптимальное решение является использование метода полного перебора, тогда «жадный» алгоритм или другой эвристический метод получения хорошего (но не обязательно оптимального) решения может оказаться единственным реальным средством достижения результата.
Как уже обсуждалось, найти точное решение задачи из класса NPС трудно, потому что число требующих проверки возможных комбинаций входных значений чрезвычайно велико. Жадные алгоритмы пытаются сделать наилучший выбор на основе доступной информации.
Для каждого набора входных значений I мы можем создать множество возможных решений PSI. Оптимальное решение это такое решение Sоптимал ÎPSI, что Value(Sоптимал)£Value(S’) для всех S’ÎPSI, если мы имеем дело с задачей минимизации, и Value(Sоптимал)³Value(S’) для всех S’ÎPSI, если мы имеем дело с задачей максимизации.
Решения, предлагаемые приближенными алгоритмами для задач класса NP, не будут оптимальными, поскольку алгоритмы просматривают только часть массива PSI, зачастую не очень большую.
Качество приближенных алгоритмов можно определить, сравнив полученные решения с оптимальным (если, конечно, известно оптимальное решение):
Q(A)=для задачи минимизации и
Q(A)=для задачи поиска максимума.
Рассмотрим приближенные алгоритмы решения рассмотренных ранее задач. Они не являются единственно возможными, скорее они призваны продемонстрировать многообразие различных подходов.
8.2.2. Приближения в задаче коммивояжера
«Жадный» алгоритм для задачи коммивояжера является вариантом алгоритма Крускала. Здесь, как и в основном алгоритме Крускала, сначала рассматриваются самые короткие ребра. В алгоритме Крускала очередное ребро принимается в том случае, если оно не образует цикла с уже принятыми ребрами; в противном случае ребро отвергается. В случае задачи коммивояжера «критерием принятия» ребра является то, что:
– при добавлении ребра не образуется цикл, если это – не завершающее ребро в пути;
– добавляемое ребро не является третьим, выходящим из какой-либо вершины.
Совокупность ребер, выбранных в соответствии с этими условиями, образуют совокупность несоединенных путей; такое положение сохраняется до выполнения последнего шага, когда единственный оставшийся путь замыкается, образуя маршрут.
Стоимость проезда между двумя городами можно задать матрицей примыканий (табл. 8.1)
Эта матрица – верхняя треугольная, поскольку стоимость проезда между городами i и j одинакова в обоих направлениях. Использование верхней матрицы позволяет упростить трассировку алгоритма.
В примере первым выбираем ребро (3,5) с минимальным весом 1. Следующим выбранным ребром будет (5,6). Затем алгоритм рассматривает ребро (3,6), однако оно будет отвергнуто, поскольку вместе с двумя уже выбранными ребрами образует цикл (3,5,6,3), не проходящий через все вершины.
Следующими будут добавлены два ребра (4,7) и (2,7). Затем рассматривается ребро (1,5), но оно будет отвергнуто, поскольку это третье ребро, выходящее из вершины 5 (уже выбраны ребра (3,5), (5,6)).
Добавляем ребро (1,6) (отбросив при этом ребра (2,5), (6,7), (4,6), (1,7) – как третьи ребра из вершин, и ребро (1,3), дающее цикл (3-5,5-6,6-1,1-3), не захватывающий все города).
По этому принципу на следующем шаге добавляется ребро (1,4). И, наконец, ребро (2,3).
В результате получается циклический путь (2,3,5,6,1,4,7,2), или, если стартовать из первой вершины, (1,4,7,2,3,5,6,1), стоимость которого равна 53.
Это не оптимальное решение: есть, по крайней мере, один более короткий путь (1,4,7,2,5,3,6,1), полная длина которого 41.
8.2.3. Приближения в задаче о раскладке по ящикам
Для данной задачи существует множество эвристических алгоритмов.
studopedia.su - Студопедия (2013 - 2025) год. Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав!Последнее добавление


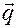 =
= 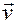 +
+ 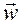 q x= v x+ w x; q y= v y+ w y;
q x= v x+ w x; q y= v y+ w y;
 = (vxwy-vywx)
= (vxwy-vywx) 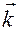 . Обратим внимание, что данное выражение является определителем матрицы
. Обратим внимание, что данное выражение является определителем матрицы .
.
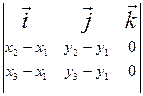 = (х 2- х 1)(у 3- у 1) – (у 2- у 1)(х 3- х 1)= х 1(у 2- у 3)+ у 1(х 3- х 2)+ х 2 у 3- х 3 у 2.
= (х 2- х 1)(у 3- у 1) – (у 2- у 1)(х 3- х 1)= х 1(у 2- у 3)+ у 1(х 3- х 2)+ х 2 у 3- х 3 у 2.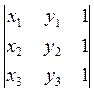 = х 1(у 2- у 3)+ у 1(х 3- х 2)+ х 2 у 3- х 3 у 2 .
= х 1(у 2- у 3)+ у 1(х 3- х 2)+ х 2 у 3- х 3 у 2 .


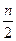 ). Нет гарантии того, что после разбиения будут решаться две задачи с трудоёмкостью Θ(
). Нет гарантии того, что после разбиения будут решаться две задачи с трудоёмкостью Θ(
 i, j Si+Sj>1. Нижняя граница m это m min = 1, при условии ∑Si ≤1.
i, j Si+Sj>1. Нижняя граница m это m min = 1, при условии ∑Si ≤1. Стоимость проезда между двумя городами можно задать матрицей примыканий (табл. 8.1)
Стоимость проезда между двумя городами можно задать матрицей примыканий (табл. 8.1)