КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Анализ первичных статистик
|
|
|
|
Делать выводы о результатах диагностики можно также на основе анализа первичных статистик (т.е. статистических показателей) или описательных статистик. К ним относят среднее арифметическое, медиану, моду, размах, стандартное отклонение и некоторые другие. Эти статистики можно сравнивать между собой (например, среднее арифметическое значение тревожности в разных группах).
1) Среднее арифметическое чаще всего используют для анализа. Для несгруппированных данных формулу вы уже знаете (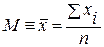 ). Для сгруппированных по классовым интервалам данным вычисление средней арифметической производят по следующей формуле.
). Для сгруппированных по классовым интервалам данным вычисление средней арифметической производят по следующей формуле.
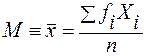 , где
, где
Xi - центр i -того класса,
fi – частота i -того класса,
n – количество испытуемых.
Среднее арифметическое – это статистический показатель, он чаще всего представлен дробным значением (например, тревожность 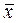 = 17,42).
= 17,42).
2) Медиана (Ме) – это не отдельное измерение, а точка в последовательном ряду данных на измерительной шкале, выше и ниже которой находятся по половине наблюдений[13].
· Вычисление медианы для несгруппированных данных, упорядоченных по степени их возрастания или убывания.
а) нечетное количество результатов:
1, 4, 5, 7, 13, 14, 15, 17, 18, 19, 21, 24 Ме = 14
б) четное количество результатов:
1, 4, 5, 7, 13, 14, 15, 17, 18, 19, 21, 24 Ме = (14 + 15)/2 = 14,5
·
|
|
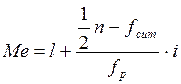 ,
,
Где где
Рассмотрим вычисление медианы на примере таблицы 8:
- Найдем половину наблюдений:
39 / 2 = 19,5
- Суммируем частоты (f), начиная с минимального класса группировки, до класса, содержащего половину представленных показателей (не менее 19,5), т.е. до медианы:
3+4+7+1+8 = 23
Медиана находится в 5 классе, точные границы которого 67,5 – 72,5;
- Определим fcum, т.е. сумму частот предыдущих классов, в которые медиана не входит:
f cum = 3+4+7+1 = 15
- Подставим данные в формулу:
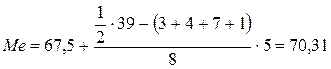
Это означает, что ровно половина детей читают больше 70 слов в минуту.
3) Мода (Мо) - это показатель, наиболее часто встречающийся в выборке («модный»). Чаще всего ее определяют тогда, когда результаты представлены в номинативной шкале. Определяют ее по частоте проявления какого-либо признака. Покажу на примерах:
а) 1; 2; 1; 3; 3; 1; 3; 2; 2. (1 – праворукие, 2 – амбиверты, 3 - леворукие).
| Диапазон | Частота (d) |
|
б) В тесте Люшера желтый цвет ставят в разные позиции: 24, 15, 13, 8, 15, 10, 9, 8
| Позиция желтого цвета | Частота (d) | ||
|
в) 10, 12, 13, 14, 11, 12, 11, 15, 16, 12, 10, 11.
| Диапазон | Частота (d) | ||
|
г) 2, 4, 3, 5, 5, 4, 4, 2, 2, 4, 2 - отметки за контрольную работу.
| Диапазон |
| ||
4) Размах (Wn) – это интервал между наибольшим и наименьшим значением. Определяется он как разность между максимальным и минимальным значениями (xmax – xmin). При малом количестве данных размах очень зависит от выступающих значений.
Например: 2, 5, 3, 1, 7, 5, 6, 4. 7 – 1 = 6
15, 17, 11, 10, 14, 13, 16, 100. 100 – 10 = 90
Однако во втором ряду значений 100, скорее всего, выпадающее значение (возможно описка). И если его исключить, размах будет гораздо уже: 17 – 10 = 7.
5) Стандартное отклонение (s) – также является первичной статистикой. Стандартное отклонение – это мера разнообразия показателей, входящих в группу. Оно показывает, на сколько в среднем отклоняется каждая варианта от средней арифметической. Чем больше отклонение, тем больше сигма.
Расчет стандартного отклонения для несгруппированных данных мы уже рассматривали (см. стр. 32, 39, 43). Для сгруппированных данных формула вычисления следующая:
|
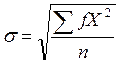 , где
, где
Смотрите вспомогательную таблицу для расчета (табл.10).
Таблица 10.
Расчет стандартного отклонения для сгруппированных данных.
| Классовые интервалы | Центр класса (xj) | Частота (f) | Отклонение (Х) | xј – M | | Х² | fХ² |
| 55-59 | 25,09 | 629,508 | 629,508 | ||
| 50-54 | 20,09 | 403,608 | 807,216 | ||
| 45-49 | 15,09 | 227,708 | 910,832 | ||
| 40-44 | 10,09 | 101,808 | 610,848 | ||
| 35-39 | 5,09 | 25,908 | 207,264 | ||
| 30-34 | 0,09 | 0,008 | 0,088 | ||
| 25-29 | 4,91 | 24,108 | 216,972 | ||
| 20-24 | 9,91 | 98,208 | 687,456 | ||
| 15-19 | 14,91 | 222,308 | 1111,540 | ||
| 10-14 | 19,91 | 396,408 | 792,816 | ||
| n = 55 | SfХ² = 5974,54 |
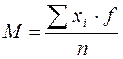
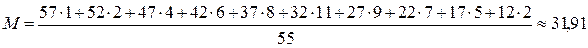
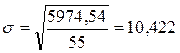
Давайте покажу Вам один фокус. Посмотрите на значение стандартного отклонения в последнем примере и примере со стр. 39.
s = 10,422; sинтел = 6,56; sнейрот = 3,31.
Что можно сказать о разбросе значений по данным показателям? Ни–че–го! Ничего нельзя сказать по абсолютным значениям стандартного отклонения, так как показатели измерены в разных единицах. Чтобы сравнить отклонения в распределении значений разных показателей, необходимо применить коэффициент вариации. С помощью него величина сигмы приводится к одному масштабу.
|
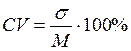 , где
, где
Сравним изменчивость массивов данных:
1) s = 10,42; М = 31,91; 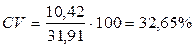
2) sинтел = 6,56; М = 101,2; 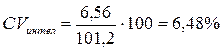
3) sнейрот = 3,31; М = 14,5; 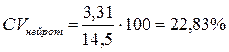
Посмотрите, если по абсолютному значению s разброс данных выше по шкале нейротизма, то, посмотрев на приведенные в один масштаб значения, видно, что он оказывается средним. Самый низкий разброс показателей – по шкале интеллекта.
Итак, проведя первичную обработку эмпирических данных (т.е. полученных в результате Вашего опыта), Вы сделали соответствующие выводы о распределении показателей, о средних значениях, о разбросе данных. Но это только первичная обработка данных. Методы математической статистики в психолого-педагогическом исследовании используют и для решения более сложных задач. И это будет вторичная обработка данных.
|
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 647; Нарушение авторских прав?; Мы поможем в написании вашей работы!