КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Нейросетевое сравнение на основе простых персептронов
|
|
|
|
Несмотря на большое разнообразие вариантов нейронных сетей, все они имеют общие черты. Так, все они, так же, как и мозг человека, состоят из большого числа связанных между собой однотипных элементов – нейронов, которые имитируют нейроны головного мозга. На рисунке показана схема нейрона.
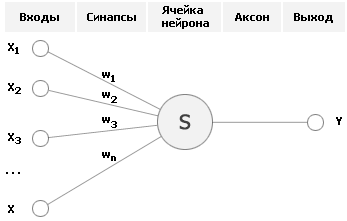
Из рисунка видно, что искусственный нейрон, так же, как и живой, состоит из синапсов, связывающих входы нейрона с ядром; ядра нейрона, которое осуществляет обработку входных сигналов и аксона, который связывает нейрон с нейронами следующего слоя. Каждый синапс имеет вес, который определяет, насколько соответствующий вход нейрона влияет на его состояние. Состояние нейрона определяется по формуле
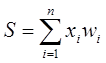
где n – число входов нейрона, xi – значение i-го входа нейрона, wi – вес i-го синапса
Затем определяется значение аксона нейрона по формуле: Y = f(S) где f – некоторая функция, которая называется активационной. Наиболее часто в качестве активационной функции используется так называемый сигмоид, который имеет следующий вид:
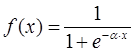
Основное достоинство этой функции в том, что она дифференцируема на всей оси абсцисс и имеет очень простую производную:
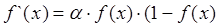
При уменьшении параметра α сигмоид становится более пологим, вырождаясь в горизонтальную линию на уровне 0,5 при α=0. При увеличении a сигмоид все больше приближается к функции единичного скачка.
Обучение сети
Для автоматического функционирования системы был выбран метод обучения сети без учителя. Обучение без учителя является намного более правдоподобной моделью обучения в биологической системе. Развитая Кохоненом и многими другими, она не нуждается в целевом векторе для выходов и, следовательно, не требует сравнения с предопределенными идеальными ответами. Обучающее множество состоит лишь из входных векторов. Обучающий алгоритм подстраивает веса сети так, чтобы получались согласованные выходные векторы, т. е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы.
Персептрон обучают, подавая множество образов по одному на его вход и подстраивая веса до тех пор, пока для всех образов не будет достигнут требуемый выход. Допустим, что входные образы нанесены на демонстрационные карты. Каждая карта разбита на квадраты и от каждого квадрата на персептрон подается вход. Если в квадрате имеется линия, то от него подается единица, в противном случае ноль. Множество квадратов на карте задает, таким образом, множество нулей и единиц, которое и подается на входы персептрона. Цель состоит в том, чтобы научить персептрон включать индикатор при подаче на него множества входов, задающих нечетное число, и не включать в случае четного.
Для обучения сети образ X подается на вход и вычисляется выход У. Если У правилен, то ничего не меняется. Однако если выход неправилен, то веса, присоединенные к входам, усиливающим ошибочный результат, модифицируются, чтобы уменьшить ошибку.
Информативность различных частей спектра неодинакова: в низкочастотной области содержится больше информации, чем в высокочастотной. Поэтому для предотвращения излишнего расходования входов нейросети необходимо уменьшить число элементов, получающих информацию с высокочастотной области, или, что тоже самое, сжать высокочастотную область спектра в пространстве частот.
Наиболее распространенный метод — логарифмическое сжатие
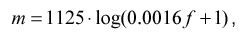
где f — частота в спектре Гц, m — частота в новом сжатом частотном пространстве
Такое преобразование имеет смысл только если число элементов на входе нейросети NI меньше числа элементов спектра NS.
После нормирования и сжатия спектр накладывается на вход нейросети. Вход нейросети — это линейно упорядоченный массив элементов, которым присваиваются уровни соответствующих частот в спектре. Эти элементы не выполняют никаких решающих функций, а только передают сигналы дальше в нейросеть. Выбор числа входов — сложная задача, потому что при малом размере входного вектора возможна потеря важной для распознавания информации, а при большом существенно повышается сложность вычислений (при моделировании на PC, в реальных нейросетях это неверно, т.к. все элементы работают параллельно).
При большой разрешающей способности (числе) входов возможно выделение гармонической структуры речи и как следствие определение высоты голоса. При малой разрешающей способности (числе) входов возможно только определение формантной структуры.
Как показало дальнейшее исследование этой проблемы, для распознавания уже достаточно только информации о формантной структуре. Фактически, человек одинаково распознает нормальную голосовую речь и шепот, хотя в последнем отсутствует голосовой источник. Голосовой источник дает дополнительную информацию в виде интонации (высоты тона на протяжении высказывания), и эта информация очень важна на высших уровнях обработки речи. Но в первом приближении можно ограничиться только получением формантной структуры, и для этого с учетом сжатия неинформативной части спектра достаточное число входов выбрано в пределах 50~100.
Наложение спектра на каждый входной элемент происходит путем усреднения данных из некоторой окрестности, центром которой является проекция положения этого элемента в векторе входов на вектор спектра. Радиус окрестности выбирается таким, чтобы окрестности соседних элементов перекрывались. Этот прием часто используется при растяжении векторов, предотвращая выпадение данных.
Тестирование алгоритма
Тестирование производилось с 8 пользователями. Каждый голос сначала сравнивался с эталонным, то есть голосом разработчика, а потом между собой, для того что бы выяснить как поведет себя система на однотипных голосах. При тестировании использовались 6 мужских голосов и 2 женских. Схожесть голосов определяется в процентах, поэтому требовалось выяснить максимально возможный порог совпадения. Эталонный голос использовался мужской, поэтому для тестирования использовалось большое количество именно мужских голосов. При тестирование произносилась одна и та же кодовая фраза, которую я за много прошедших лет уже и не помню…

Графики спектральных характеристик визуально различаются достаточно сильно, но положение пиков у них абсолютно одинаковое. Именно поэтому на одинаковых фразах даже пользователь с похожим голосом не сможет добиться такой схожести. На его характеристике положение этих пиков совпадать не будет. Так же на спектрограммах видно что произносились фразы по разному, первый образец был самых отчетливый, второй был сказан с некоторым отдалении от микрофона, третий произнесен шепотом. Это должно было сильно усложнить задачу. Но как видно из графиков их спектральные характеристики оказались схожими.
Тестирование проводилось на очень слабой звуковой карте интегрированной в материнскую плату. Карточка с высоким уровнем шума и игнорированием высоких и низких частот. А также со слабым микрофоном, не обеспечивающим необходимый уровень записи. С хорошей звуковой подсистемой, можно добиться значительно лучших результатов.
|
|
|
|
|
Дата добавления: 2015-08-31; Просмотров: 647; Нарушение авторских прав?; Мы поможем в написании вашей работы!