КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Аналитические методы в средствах разведки данных (Data Mining)
|
|
|
|
Аналитические системы многомерного анализа данных. Интеллектуальный анализ данных: технология Data Mining, системы автоматизированной подготовки отчетов, панели ключевых индикаторов эффективности бизнеса, сбалансированы системы показателей, экспертные системы
Классификация типовых задач анализа и статистических методов их решения.
В настоящем разделе будет приведена возможная классификация аналитических задач, возникающих в сфере бизнеса, финансов и управления и решаемых статистическими методами. Будет рассмотрена также классификация статистических методов, представленных в DSS-системах перечисленных выше компаний, и их применимость для решения различных классов аналитических задач.
Выделим следующие классы аналитических задач в области финансов, бизнеса и управления, требующих для своего решения использования различных статистических методов:
- горизонтального (временного) анализа;
- вертикального (структурного) анализа;
- трендового анализа и прогноза;
- анализа относительных показателей;
- сравнительного (пространственного) анализа;
- факторного анализа.
Далеко не все аналитические задачи из перечисленных выше являются в настоящий момент одинаково важными для каждой конкретной компании. В их повседневной деятельности еще велика доля рутинных бухгалтерских операций и много такого, что пока вовсе не требует никакого анализа. Однако необходимость повышения роли аналитического подхода начинают ощущать даже совсем малые фирмы.
Рассмотрим теперь классификацию методов статистического анализа. Все эти методы могут быть разделены на следующие классы:
- описательной статистики;
- проверки статистических гипотез;
- регрессионного анализа;
- дисперсионного анализа;
- анализа категориальных данных;
- многомерного анализа;
- дискриминантного анализа;
- кластерного анализа;
- анализа выживаемости; анализа и прогноза временных рядов;
- статистического планирования экспериментов и статистического контроля качества.
В настоящее время элементы искусственного интеллекта активно внедряются в практическую деятельность менеджера. В отличие от традиционных систем искусственного интеллекта, технология интеллектуального поиска и анализа данных или «добыча данных»(Data Mining - DM), не пытается моделировать естественный интеллект, а усиливает его возможности мощностью современных вычислительных серверов, поисковых систем и хранилищ данных. Нередко рядом со словами «Data Mining» встречаются слова «обнаружение знаний в базах данных» (Knowledge Discovery in Databases).
Data Mining - это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Data Mining представляют большую ценность для руководителей и аналитиков в их повседневной деятельности. Деловые люди осознали, что с помощью методов Data Mining они могут получить ощутимые преимущества в конкурентной борьбе.
В основу современной технологии Data Mining (Discovery-driven Data Mining) положена концепция шаблонов (Patterns), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные выборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборки и виде распределений значений анализируемых показателей. На рис. 7.1 показана схема преобразования данных с использованием технологии Data Mining.
Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем. На рис.7.2 показан полный цикл применения технологии Data Mining.
Важное положение Data Mining - нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (Unexpected) регулярности в данных, составляющие так называемые скрытые знания (Hidden Knowledge). К деловым людям пришло понимание, что «сырые» данные (Raw Data) содержат глубинный пласт знаний, и при грамотной его раскопке могут быть обнаружены настоящие самородки, которые можно использовать в конкурентной борьбе.
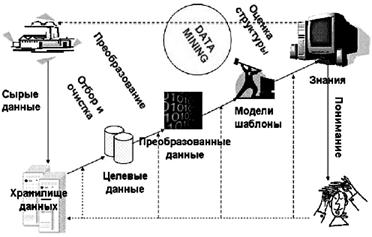
Рисунок 7.1 – Cхема преобразования данных с использованием технологии Data Mining
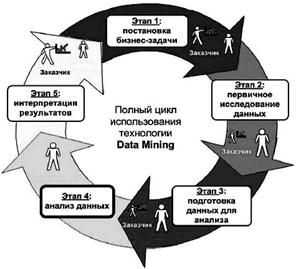
Рисунок 7.2 – Полный цикл применения технологии Data Mining
Сфера применения Data Mining ничем не ограничена -технологию можно применять всюду, где имеются огромные количества каких-либо «сырых» данных.
В первую очередь методы Data Mining заинтересовали коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных (Data Warehousing). Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000 %. Известны сообщения об экономическом эффекте, в 10-70 раз превысившем первоначальные затраты от 350 до 750 тыс. долларов. Есть сведения о проекте в 20 млн. долларов, который окупился всего за 4 месяца. Другой пример - годовая экономия 700 тыс. долларов за счет внедрения Data Mining в одной из сетей универсамов в Великобритании.
Компания Microsoft официально объявила об усилении своей активности в области Data Mining. Специальная исследовательская группа Microsoft, возглавляемая Усамой Файядом, и шесть приглашенных партнеров (компании Angoss, Datasage, Epiphany, SAS, Silicon Graphics, SPSS) готовят совместный проект по разработке стандарта обмена данными и средств для интеграции инструментов Data Mining с базами и хранилищами данных.
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. (рис. 7.3). Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining. Многие из таких систем интегрируют в себе сразу несколько подходов. Тем не менее, как правило, в каждой системе имеется какая-то ключевая компонента, на которую делается главная ставка.
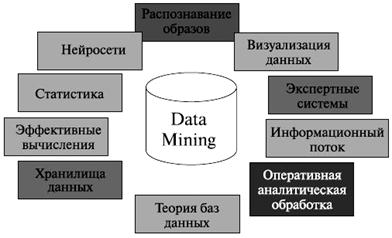
Рисунок 7.3 – Области применения технологии Data Mining
Можно назвать пять стандартных типов закономерностей, выявляемых с помощью методов Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование.
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в компьютерном супермаркете, может показать, что 55 % купивших компьютер берут также и принтер или сканер, а при наличии скидки за такой комплект принтер приобретают в 80 % случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45 % случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60 % новоселов обзаводятся холодильником.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
Статистические пакеты. Последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также элементы Data Mining. Но основное внимание в них уделяется все же классическим методикам - корреляционному, регрессионному, факторному анализу и другим.
Недостатком систем этого класса считают требование к специальной подготовке пользователя. Также отмечают, что мощные современные статистические пакеты являются слишком «тяжеловесными» для массового применения в финансах и бизнесе.
Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение в Data Mining. Большинство методов, входящих в состав пакетов, опираются на статистическую парадигму, в которой главными фигурантами служат усредненные характеристики выборки. А эти характеристики при исследовании реальных сложных жизненных феноменов часто являются фиктивными величинами. Это чрезвычайно важное обстоятельство следует обязательно учитывать при анализе многомерных данных.
В качестве примеров наиболее мощных и распространенных статистических пакетов можно назвать SAS (компания SAS Institute), SPSS (компания SPSS), STATGRAPHICS (компания Manugistics), STATISTICA для WINDOWS, STADIA и другие. Эти пакеты с успехом могут применять небольшие и средние предприятия, а большие многопрофильные компании могут интегрировать их в общую корпоративную сеть.
Аналитические методы дают конечному пользователю возможность осуществить весь цикл работы с исходными данными, имеющими большие объемы и невыясненную статистическую структуру. Этот цикл называется разведкой данных (Data Mining) и состоит из нескольких этапов: выборка, исследование, модификация, моделирование, оценка результатов (Sample, Explore, Modify, Model, Assess).
Средства Data Mining дают возможность ставить и решать как традиционные, так и нетрадиционные задачи анализа. Например, традиционной является постановка задачи: «Определить, имеется ли статистическая связь между такими показателями, как объем производства товара и объем его реализации (продажи)».
Нетрадиционной же была бы следующая постановка задачи: «Имеется несколько десятков (или даже сотен) показателей деятельности предприятия, и необходимо определить, между какими из них следует искать статистические связи вообще, какого рода связи следует искать (считать ли показатели равноправными, или считать одни показатели независимыми, а другие зависимыми переменными), на каких объектах эти связи проявляются».
При работе приложения на этапе выборки происходит формирование подмножества наблюдений из исходных данных (отбор по критериям или случайный отбор). На этапах исследования и модификации могут быть осуществлены: фильтрация данных, отбрасывание данных с большими выбросами, преобразование исходных переменных. На этапе моделирования осуществляется построение регрессий и оптимизация подмножества переменных, принятие решений на основе методик нейронных сетей, реализующих различные алгоритмы обучения классификации объектов, построение классификационных деревьев для отбора оптимального набора переменных и оптимального разбиения множества объектов, кластеризация и оптимальная группировка объектов. Наконец, на этапе обзора и оценки результатов пользователь имеет возможность сопоставить различные результаты моделирования, выбрать оптимальные класс и параметры моделей, представить результаты анализа в удобной форме.
На этапе подготовки данных обеспечивается доступ к любым реляционным базам данных, текстовым и SAS-файлам. Дополнительные средства преобразования и очистки данных позволяют изменять вид представления, проводить нормализацию значений, выявлять неопределенные или отсутствующие значения. На основе подготовленных данных специальные процедуры автоматически строят различные модели для дальнейшего прогнозирования, классификации новых ситуаций, выявления аналогий. Данные приложения поддерживают построение пяти различных типов моделей — нейронные сети, классификационные и регрессионные деревья решений, ближайшие k-окрестности, байесовское обучение и кластеризацию.
Анализ математического обеспечения существующих систем поддержки принятия решений. Рассмотрим более подробно средства интеллектуального анализа данных (ИАД, Data Mining), применяемые в системах поддержки принятия решений.
В качестве первого направления развития средств ИАД следует выделить методы статистической обработки данных, которые можно разделить на четыре взаимосвязанных раздела:
· предварительный анализ природы статистических данных (проверка гипотез стационарности, нормальности, независимости, однородности, оценка вида функции распределения и ее параметров);
· выявление связей и закономерностей (линейный и нелинейный регрессионный анализ, корреляционный анализ);
· многомерный статистический анализ (линейный и нелинейный дискриминантный анализ, кластер-анализ, компонентный анализ, факторный анализ);
· динамические модели и прогноз на основе временных рядов.
Среди наиболее известных и популярных средств статистического анализа следует назвать пакеты Statistica, SPSS, Systat, Statgraphics, SAS, BMDP, TimeLab, Data-Desk, S-Plus, Scenario (BI), «Мезозавр».
Особое направление в спектре аналитических средств ИАД составляют методы, основанные на нечетких множествах. Их применение позволяет ранжировать данные по степени близости к желаемым результатам, осуществлять так называемый нечеткий поиск в базах данных. Однако платой за повышенную универсальность является снижение уровня достоверности и точности получаемых результатов. Поэтому число специализированных приложений данного метода по-прежнему невелико, несмотря на то, что на протяжении последних 35 лет математики прикладники проявляли к нему повышенный интерес.
Второе крупное направление развития составляют кибернетические методы оптимизации, основанные на принципах саморазвивающихся систем — методы нейронных сетей, эволюционного и генетического программирования.
Однако новые достоинства порождают и новые проблемы. В частности, решения, полученные кибернетическими методами, часто не допускают наглядных интерпретаций, что в определенной степени усложняет жизнь предметным экспертам.
К программным продуктам, использующим кибернетические методы ИАД, относятся системы PolyAnalyst, NeuroShell, GeneHunter, BrainMaker, OWL, 4Thought (BI).
Непосредственно к кибернетическим методам ИАД примыкают синергетические методы. Их применение позволяет реально оценить горизонт долгосрочного прогноза. Особенный интерес вызывают исследования, связанные с попытками построения эффективных систем управления в неустойчивых режимах функционирования.
К третьему крупному разделу ИАД следует отнести совокупность традиционных методов решения оптимизационных задач — вариационные методы, методы исследования операций, включающие в себя различные виды математического программирования (линейное, нелинейное, дискретное, целочисленное), динамическое программирование, принцип максимума Понтрягина, методы теории систем массового обслуживания. Программные реализации большинства этих методов входят в стандартные пакеты прикладных программ, например Math CAD и MatLab.
В четвертый раздел средств ИАД входят средства, которые назовем условно экспертными, т. е. связанными с непосредственным использованием опыта эксперта. К их числу относят метод «ближайшего соседа», который лег в основу таких программных продуктов, как Pattern Recognition Workbench или KATE tools.
Другой подход к выбору решения связан с построением последовательного логического вывода — дерева решений, в каждом узле которого эксперт осуществляет простейший логический выбор («да» — «нет»). В зависимости от принятого выбора, поиск решения продвигается по правой или левой ветви дерева и, в конце концов, приходит к терминальной ветви, отвечающей конкретному окончательному решению. Здесь процесс статистического обучения выведен за пределы программы и сконцентрирован в виде некоторого априорного опыта, заключенного в наборе ветвей-решений.
Одной из разновидностей метода деревьев решений является алгоритм деревьев классификации и регрессии, предлагающий набор правил для дихотомической классификации совокупности исходных данных. Данный метод обычно применяется для предсказания того, какие последовательности событий будут иметь заданный исход. На основе деревьев решений разработаны такие программные продукты, как IDIS, С5.0 и SIPINA.
К экспертным методам следует отнести и предметно-ориентированные системы анализа ситуаций и прогноза, основанные на фиксированных математических моделях, отвечающих той или иной теоретической концепции. Роль эксперта состоит в выборе наиболее адекватной системы и интерпретации полученного алгоритма. Достоинства и недостатки таких систем очевидны — предельная простота и доступность применения и расплата достоверностью и точностью за эту простоту. Примерами программных продуктов, отвечающих предметно-ориентированным системам в области финансов, являются Wall Street Money, MetaStock, SuperCharts, Candlestick Forecaster.
В завершение обзора экспертных методов ИАД следует упомянуть методы визуализации данных и результатов их анализа, позволяющие наглядно отображать полученные выводы для создания у предметных экспертов и/или руководителей проектов единой картины ситуации. К программным продуктам, позволяющим формировать предварительные отчеты и визуализировать результаты, следует отнести системы Mineset и Impromptu (BI). В частности, система Mineset содержит в себе такие инструменты, как ландшафтный визуализатор, визуализаторы дисперсии, деревьев, правил и свидетельств.
Формировать сложные нелинейные отображения средствами цветной графики позволяет новое направление визуализации результатов, основанное на идеях фрактальной математики.
Если говорить о практике внедрения рассмотренных систем и информационных технологий в Украине, то она находится в самом зачаточном состоянии. Основной целью настоящей статьи и являлось привлечь внимание, прежде всего функциональных руководителей соответствующих служб, к имеющимся возможностям, мировой практике использования систем и основным тенденциям их развития.
Опыт автора по проведению подготовительной работы к внедрению рассматриваемых продуктов показал, что, с одной стороны, на украинских предприятиях исторические данные недооцениваются, а имеющиеся базы данных часто очень «бедны» для извлечения из них значимой информации, т.к. разрабатывались для решения учетных, а не управленческих задач. С другой стороны, в Украине очень ограничены возможности извлечения знаний из данных вследствие большой скорости изменений законодательной базы, что очень сильно искажает временную статистику. Это приводит к необходимости использования, например, нелинейных методов, в развитии которых вместе с украинскими учеными активное участие принимает компания, возглавляемая автором.
Научные направления, имеющие отношение к рассматриваемому вопросу, практически остались за пределами настоящей статьи, как по причине ограниченности формата, так и потому, что относятся в основном к другой сфере знания — самой что ни на есть фундаментальной математике.
Контрольные вопросы
1. Приведите возможную классификацию типовых задач анализа и статистических методов их решения.
2. Перечислите аналитические методы в средствах разведки данных (Data Mining).
3. Что положено в основу современной технологии Data Mining?
4. Каковы области применения технологии Data Mining?
5. Анализ математического обеспечения существующих систем поддержки принятия решений.
Рекомендуемая литература
1. Данилевский Ю. Г. Информационная технология в промышленности / Ю. Г. Данилевський, И. А. Петухов, B. C. Шибанов. - Л.: Машиностроение, 1988. – 452 с.
2. Устинова Г. М. Информационные системы менеджмента / Г. М. Устинова. – СПб: Изд-во «ДиаСофт ЮП», 2000. – 368 с.
3. Информационные системы в экономике / Под ред. В. В. Дика. - М.: Финансы и статистика, 1996. – 358 с.
4. Компьютерно-интегрированные производства и CALS технологии в машиностроении. - М.: Федеральный информационно-аналитический центр оборонной промышленности. 1999. – 510 с.
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 4172; Нарушение авторских прав?; Мы поможем в написании вашей работы!