КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Flow-форми
|
|
|
|
Псевдокоди
Псевдокод – формалізоване текстове описання алгоритму (текстова нотація). В літературі були запропоновані декілька варіантів псевдокодів. Один з них наведений в табл. 3.3.
Таблиця 3.3. Описання псевдокодів
| Структура | Псевдокод | Структура | Псевдокод |
| Слідування | <Дія 1> <Дія 2> | Вибір | Вибір <код> <код 1>:<Дія 1> <код 2>:<Дія 2> Кінець-вибір |
| Розгалуження | Якщо<Умова> тоді<Дія 1> інакше<Дія 1> Кінець-якщо | Цикл із заданою кількістю повторень | Для<індекс>=<n>,<k>,<h> <Дія> Кінець-цикл |
| Цикл-поки | Цикл-поки<Умова> <Дія> Кінець-цикл | Цикл-до | Виконувати <Дія> До <Умова> |
Flow-форми представляють собою графічну нотацію описання структурних алгоритмів, яка ілюструє вкладеність структур. Кожен символ Flow-форми має вигляд прямокутника і може бути вписаний в будь-який внутрішній прямокутник будь-кого іншого символа. Нотація Flow-форми приведена на рис. 3.17.
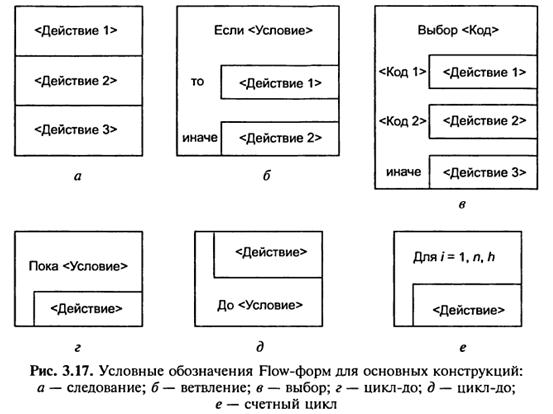
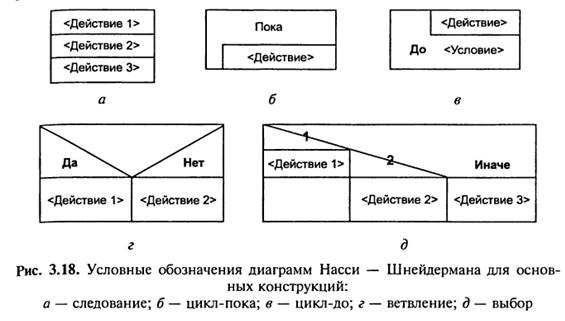
Діаграми Нассі–Шнейдермана
Діаграми Нассі–Шнейдермана є продовженням Flow-форм. Відмінність їх від Flow-формполягає в тому, що область позначення умов зображують у вигляді трикутників (рис. 3.18). Це позначення забезпечує більшу наглядність представлення алгоритму.
При використанні псевдокодів, Flow-форм і діаграм Нассі–Шнейдермана описати не структурний алгоритм неможливо (для неструктурних передач управління в цих нотаціях просто відсутні умовні позначення).
Порівняно з псевдокодами Flow-форми і діаграми Нассі–Шнейдермана, які є графічними, краще відображають вкладеність конструкцій.
Загальним недоліком Flow-форм і діаграм Нассі–Шнейдермана є складність побудови зображення символів, що затрудняє практичне використання цих нотацій для описання великих алгоритмів.
3.5.2. Словник термінів
Словник термінів представляє собою коротке описання основних понять, які використовуються при складанні специфікацій. Він призначений для підвищення степені розуміння предметної області та запобігання ризику виникнення розбіжностей при обговоренні моделей між замовниками і розробниками [1].
Зазвичай описання терміналу в словнику виконують за наступною схемою:
– термін;
– категорія (поняття предметної області, елемент даних, умовне позначення і т.д.);
– коротке описання.
Приклад:
Термін Web-сайт
Категорія Інтернет-програмування
Описання Сукупність Web-сторінок з повторюваним дизайном, об’єднаних по змісту, які навігаційно і фізично знаходяться на одному сервері.
3.5.3. Діаграми переходів станів (STD)
STD демонструє поведінку розроблюваної програмної системи при отриманні керуючих впливів (ззовні).
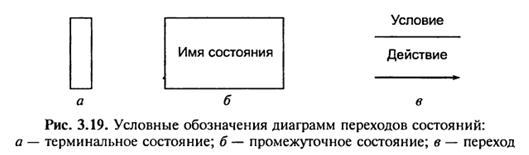
У діаграмах такого виду вузли відповідають станам динамічної системи, а дуги – переходам системи з одного стану в інший. Вузол, з якого виходить дуга, є початковим станом, вузол, в який дуга входить, – наступним. Дуга позначається іменем вхідного сигналу чи події, що викликають перехід, а також сигналом чи дією, яка супроводжує перехід. Умовні позначення, які використовуються при побудові діаграм переходів станів, показані на рис. 3.19.
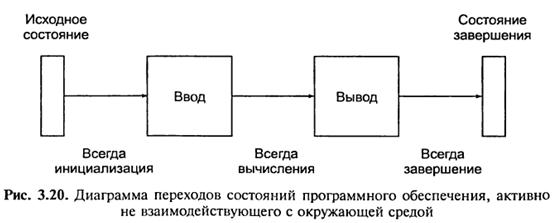
На рис. 3.20 представлена діаграма переходів станів програми, яка активно не взаємодіє з навколишнім середовищем, має примітивний інтерфейс, проводить деякі обчислення і виводить простий результат.
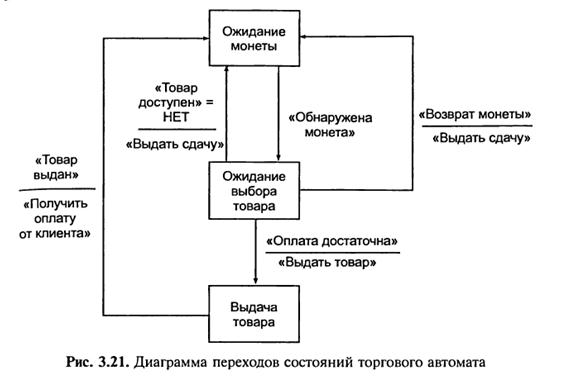
На рис. 3.21 представлена діаграма переходів торгового автомата, який активно взаємодіє з покупцем [55].
3.5.4. Функціональні діаграми
Функціональними називають діаграми, які в першу чергу відображають взаємозв’язок функцій взаємозв’язку функцій програмного забезпечення [53].
Вони створюються на ранніх етапах проектування систем, для того щоб допомогти проектувальнику виявити основні функції і складові частини системи і, по можливості, знайти і виправити суттєві помилки. Сучасні методи структурного аналізу і проектування надають розробнику визначені синтаксичні і графічні засоби проектування функціональних діаграм інформаційних систем.
В якості прикладу розглянемо методологію SADT, запропоновану Дугласом Россом. На основі неї розроблена, відома методологія IDEF() (Icam DEFinition). Методологія SADT представляє собою набір методів, правил і процедур, призначених для побудови функціональної моделі об’єкту деякої предметної області.
Функціональна модель SADT відображає функціональну структуру об’єкту, тобто виконувані ним дії і зв’язки між цими діями. Основні елементи цієї методології ґрунтуються на наступних концепціях:
– графічне представлення блочного моделювання. На SADT-діаграмі функції представляються у вигляді блоку, а інтерфейси входу-виходу – у вигляді дуг, які відповідно входять у блок і виходять з нього. Інтерфейсні дуги відображають взаємодію функцій одна з одною;
– строгість і точність відображення.
Правила SADT включають:
– унікальність міток і найменувань;
– обмеження кількості блоків на кожному рівні декомпозиції;
– синтаксичні правила для графіки;
– зв’язність діаграм;
– відділення організації від функції;
– розділення входів і керувань.
Методологія SADT може використовуватись для моделювання і розробки широкого кола систем, які задовольняють визначені вимоги і реалізують потрібні функції. У вже розроблених системах методологія SADT може бути використана для аналізу виконуваних ними функцій, а також для вказування механізмів, засобами яких вони здійснюються.
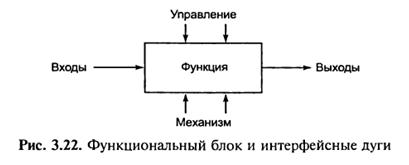
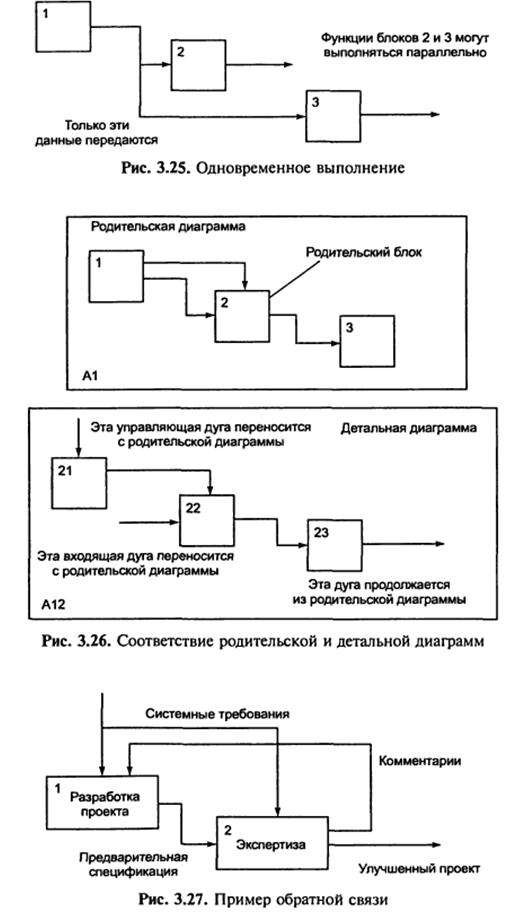
Діаграми – головні компоненти моделі, всі функції програмної системи та інтерфейси на них представлені як блоки і дуги. Місце з’єднання дуги з блоком визначає тип інтерфейсу. Дуга, яка означає керування, входить в блок зверху, в той час як інформація, яка підлягає обробці, представляється дугою з лівої сторони блоку, а результати обробки – дугами з правої сторони. Механізм (людина чи автоматизована система), який здійснює операцію, представляється у вигляді дуги, яка входить у блок знизу (рис. 3.22).
Блоки на діаграмі розміщуються по «сходинковій» схемі у відповідності з послідовністю їх роботи чи домінуванням, яке розуміється як вплив одного блоку на інші. У функціональних діаграмах SADT розрізняють п’ять типів впливів блоків один на одного [1]:
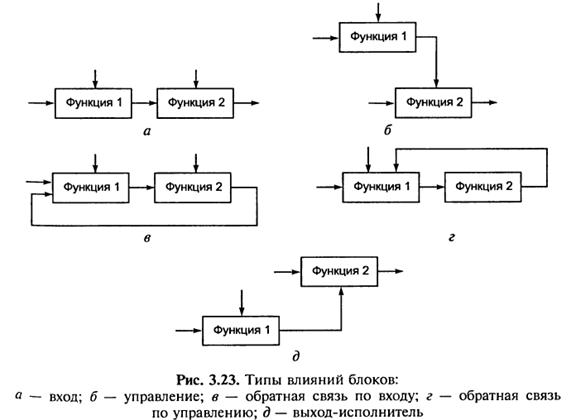
– вхід-вихід блоку подається на вхід з меншим домінуванням, тобто наступного (рис 3.23, а);
– управління. Вихід блоку використовується як управління для блоку з меншим домінуванням (рис 3.23, б);
– зворотній зв’язок по виходу. Вихід блоку подається на вхід блоку з більшим домінуванням (рис 3.23, в);
– зворотній зв’язок по керуванню. Вихід блоку використовується як керуюча інформація для блоку з більшим домінуванням (рис 3.23, г);
– вихід-виконавець. Вихід блоку використовується як механізм для другого блоку (рис 3.23, д).
Однією з найбільш важливих особливостей методології SADT є поступове введення все більших рівнів деталізації по мірі створення діаграм, які відображають модель.
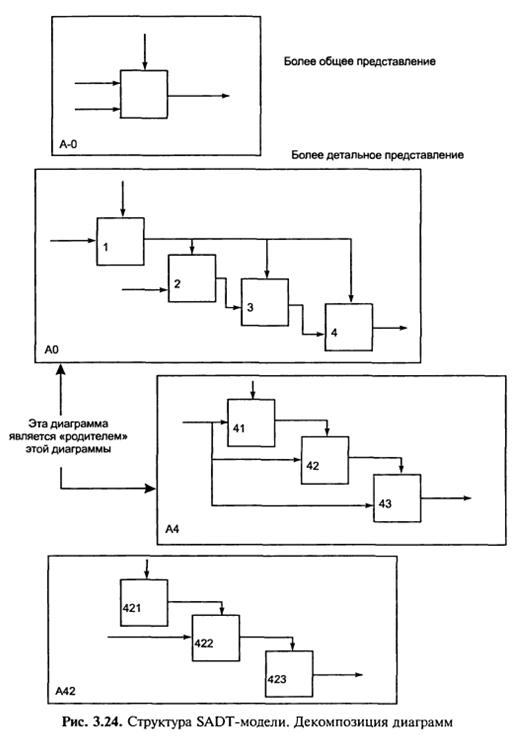
На рис. 3.24 приведено чотири діаграми та їх взаємозв’язки, які рлказують структуру SADT-моделі. Кожен компонент моделі може бути декомпозований на іншій діаграмі. Детальна діаграма ілюструє внутрішню будову «батьківської» діаграми.
Ієрархія діаграм
Перш за все, вся система представляється у вигляді простої компоненти – одного блоку і дуг, які представляють собою інтерфейси із зовнішніми по відношенню до даної системи функціями. Ім’я блоку є загальним для всієї системи [53].
Потім блок, який представляє систему в цілому, деталізується на наступній діаграмі. Він представляється у вигляді декількох блоків, з’єднаних інтерфейс ними дугами. Кожен блок детальної діаграми представляє собою підфункцію, межі якої визначені інтерфейсними дугами. Кожен із блоків детальної діаграми може бути також деталізована на наступній в ієрархії діаграмі. На кожному кроці декомпозиції більш загальна діаграма називається батьківською для більш детальної діаграми.
Всі діаграми зв’язують одна з одною ієрархічною нумерацією блоків: перший рівень – А0, другий А1, А2 і т.д., третій А11, А12, А13 і т.д., де перші цифри – номер батьківського блоку, а остання – номер конкретного блоку детальної діаграми.
У всіх випадках кожна підфункція може містити тільки ті елементи, які входять у початкову функцію, причому ніякі із них не можуть бути пропущені. Тобто батьківський блок і його інтерфейси забезпечують контекст. До нього неможливо нічого добавити, та з нього не може бути нічого видалено.
Дуги, які входять в блок і виходять з нього на діаграмі верхнього рівня, є точно тими ж, що і дуги, які входять в діаграму нижнього рівня і виходять з неї, тому що блок і діаграма представляють одну і ту ж частину системи.
На рис. 3.25–3.27 наведено різні варіанти виконання функцій і з’єднання дуг з блоками.
Послідовність операцій, час їх виконання не вказуються на SADT-діаграмах. Зворотні зв’язки, ітерації, процеси і функції які перекриваються (по часу) можуть бути зображені з допомогою дуг. Зворотні зв’язки можуть виступати у вигляді коментаріїв, зауважень, виправлень і т.д. (рис. 3.27).
Приклад 3.1. Розробку функціональних діаграм продемонструємо на прикладі уточнення специфікацій програми сортування одновимірного масиву з використанням декількох методів.
Діаграма, представлена на рис. 3.28, а, є діаграмою верхнього рівня. Вона ілюструє початкові дані програми та очікувані результати.
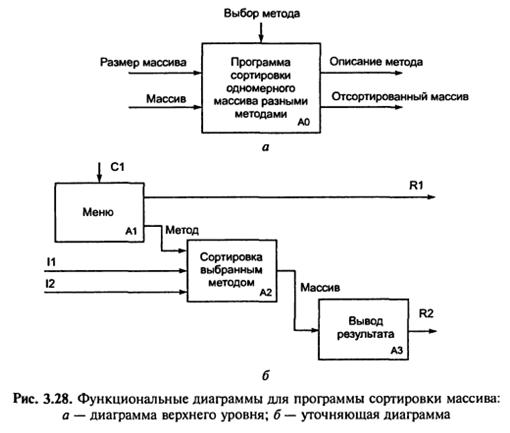
Діаграма, представлена на рис. 3.28, б, деталізує функції програми. На ній показано три блоки: Меню, Сортування, Вивід результату. Для кожного блоку визначені початкову дані, керуючі впливи і результати. На деталізуючій діаграмі використовуються наступні позначення:
І1 – розмір масиву;
І2 – масив;
C1 – вибір методу;
R1 – вивід описання методу;
R2 – відсортований масив.
3.5.5. Діаграми потоків даних (DFD)
Така діаграма складається з трьох типів вузлів: вузлів обробки даних, вузлів збереження даних і зовнішніх вузлів, які представляють зовнішні по відношенню до використовуваної діаграми джерела чи користувачі даних. Дуги в діаграмі відповідають потокам даних, які передаються від вузла до вузла. Вони помічені іменами відповідних даних. Описання процесу, функції чи системи обробки даних, які відповідають вузлу діаграми, може бути представлено діаграмою наступного рівня деталізації, якщо процес достатньо складний [1, 53].
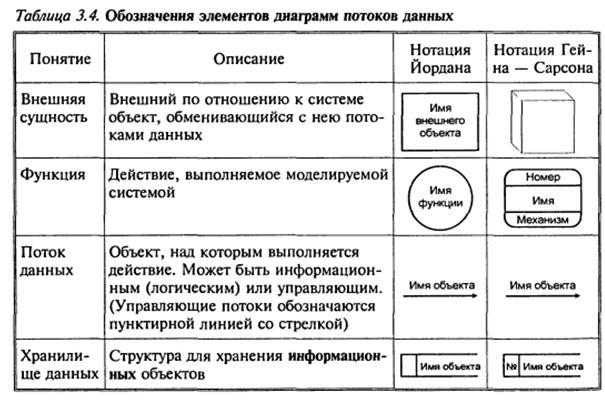
Для зображення діаграм потоків даних традиційно використовують два види нотацій: нотації Йордана і Гейна-Сарсона (табл. 3.4).
Першим кроком при побудові ієрархії діаграм потоків даних є побудова контекстних діаграм, які показують, як система буде взаємодіяти з користувачами та іншими зовнішніми системами. При проектуванні простих систем достатньо однієї контекстної діаграми, яка має зіркову топологію, в центрі якої розміщується основний процес, з’єднаний з джерелами і приймачами інформації.
Для складних систем будується ієрархія контекстних діаграм, яка визначає взаємодію основних функціональних підсистем проектованої системи як між собою, так і з зовнішніми вхідними і вихідними потоками даних і зовнішніми об’єктами. При цьому контекстна діаграма верхнього рівня містить набір підсистем, з’єднаних потоками даних. Контекстну діаграми наступного рівня деталізують вмістиме і структуру підсистем.
Після побудови контекстних діаграм отриману модель слід перевірити на повноту початкових даних і відсутність інформаційних зв’язків з іншими об’єктами.
Для кожної підсистеми, присутньої на контекстних діаграмах, виконується її деталізація з допомогою діаграм потоків даних, при цьому необхідно дотримуватись наступних правил:
– правило балансування. Означає, що при деталізації підсистеми можна використовувати тільки ті компоненти (підсистеми, процеси, зовнішні сутності, накопичувачі даних), з якими вона має інформаційний зв’язок на батьківській діаграми;
– правило нумерації. Означає, що при деталізації підсистем повинна підтримуватись їх ієрархічна нумерація. Наприклад, підсистеми, які деталізують підсистему з номером 2, отримують номери 2.1, 2.2, 2.3 і т.д.
При побудові ієрархії діаграм потоків даних переходити до деталізації процесів слід тільки після визначення структур даних, які описують вміст всіх потоків і накопичувачів даних. Структури даних можуть містити альтернативи, умовні входження та ітерації. Умовне входження означає, що відповідні компоненти можуть бути відсутніми в структурі. Альтернатива означає, що в структуру може входити один з перерахованих елементів. Ітерація означає, що компонент може повторюватись у структурі деяку кількість разів. Для кожного елемента даних може вказуватись його тип (неперервний чи дискретний). Для неперервних даних може вказуватись одиниця виміру (кг, см і т.д.), діапазон значень, точність представлення і форма фізичного кодування. Для дискретних даних може вказуватись таблиця допустимих значень.
Побудовану модель системи необхідно перевірити на повноту і узгодженість. У повній моделі всі її об’єкти (підсистеми, процеси, потоки даних) повинні бути детально описані і деталізовані. Виявлені недеталізовані об’єкти слід деталізувати, повернувшись на попередні етапи розробки. В узгодженій моделі для всіх потоків даних і накопичувачів даних повинно виконуватись правило збереження інформації: всі дані, які поступають куди-небудь повинні бути зчитані, а всі зчитувані дані повинні бути записані.
У відповідності з вищесказаним процес побудови моделі розбивається на наступні етапи [39]:
1. Виділення множини вимог в основні функціональні групи – процеси.
2. Виявлення зовнішніх об’єктів, зв’язаних з розроблюваною системою.
3. Ідентифікація основних потоків інформації, яка циркулює між системою і зовнішніми об’єктами.
4. Попередня розробка контекстної діаграми.
5. Перевірка попередньої контекстної діаграми і внесення в неї змін.
6. Побудова контекстної діаграми шляхом об’єднання всіх процесів попередньої діаграми в один процес, а також групування потоків.
7. Перевірка основних вимог контекстної діаграми.
8. Декомпозиція кожного процесу поточної DFD з допомогою деталізуючої діаграми чи специфікації процесу.
9. Перевірка основних вимог по DFD відповідного рівня.
10. Додавання визначень нових потоків у словник даних при кожній появі їх на діаграмі.
11. Перевірка повноти і наочності моделі після побудови кожних двох-трьох рівнів.
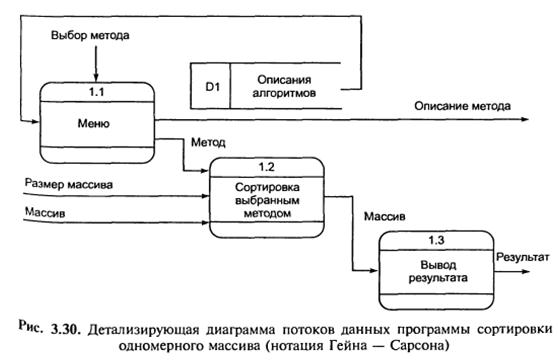
Приклад 3.2. Розробимо ієрархію діаграм потоків даних програми сортування одновимірних масивів.
Для початку побудуємо контекстну діаграму, для чого визначимо зовнішні сутності і потоки даних між програмою і зовнішніми сутностями. Зовнішньою сутністю по відношенню до програми є Користувач. Він вибирає метод сортування і вводить початкові дані, а потім отримує від програми описання вибраного методу і відсортований масив. На рис. 3.29 наведена контекстна діаграма даної програми.
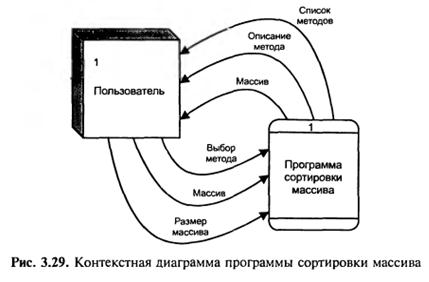
Після деталізації отримались три процеси: Меню, Сортування, Вивід результату. Для збереження описання алгоритмів служить Сховище алгоритмів. Тепер визначимо потоки даних.
Деталізуюча діаграма потоків даних зображена на рис 3.30. Як бачимо, вона дещо відрізняється від функціональної діаграми (див. 3.28), наприклад, на ній показане сховище даних для зберігання описання алгоритмів. Ця відмінність є важливою при проектуванні баз даних.
3.5.6. Діаграма сутність-зв’язок
Базовим поняттям ER-моделі даних (ER – Entity-Relationship) є сутність, атрибут і зв’язок [55].
Перший варіант моделі «сутність-зв’язок» був запропонований в 1976 р. Пітером Пін-Шен Ченом. У подальшому багатьма авторами були розроблені свої варіанти подібних моделей (нотація Мартіна, нотація IDEF1X, нотація Баркера та ін.). Крім того, різні програмні засоби, які реалізують одну і ту ж нотацію, можуть відрізнятись своїми можливостями. Всі варіанти діаграм «сутність-зв’язок» виходять з одної ідеї – рисунок завжди більш наочний ніж текстове описання. Всі такі діаграми використовують графічне зображення сутностей предметної області, їх властивостей (атрибутів) і зв’язків між сутностями.
Оскільки нотація Баркера є найбільш поширеною, в подальшому будемо дотримуватись саме її.
Основні поняття ER-діаграм
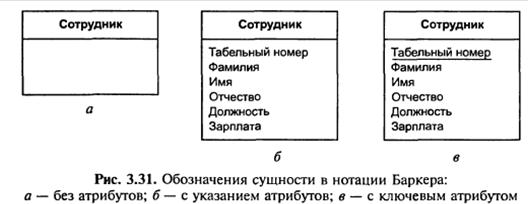
Сутність – це клас однотипних об’єктів, інформація про які повинна бути врахована в моделі [55]. Сутність має назву, виражену іменником в єдиному числі, і позначається прямокутником з найменуванням (рис. 3.31, а). Прикладами сутностей можуть бути такі класи об’єктів, як «Студент», «Співробітник», «Товар».
Екземпляр сутності – це конкретний представник даної сутності. Наприклад, конкретний представник сутності «Студент» – «Мексимов». Причому сутності повинні мати деякі властивості, унікальні для кожного екземпляра цієї сутності, для того щоб розрізняти екземпляри.
Атрибут сутності – це іменована характеристика, яка є деякою властивістю сутності. Найменування атрибута повинно бути виражено іменником в єдиному числі (можливо, з описовими оборотами чи прийменниками). Прикладами атрибутів сутності «Студент» можуть бути такі атрибути, як «Номер залікової книжки», «Прізвище», «Ім’я», «Стать», «Вік», «Середній бал» і т.д. Атрибути зображуються в прямокутнику, який означає сутність (рис. 3.31, б).
Ключ сутності – це набір атрибутів, значення яких у сукупності є унікальними для кожного екземпляра сутності. При видаленні любого атрибута з ключа порушується його унікальність. Ключів у сутності може бути декілька. На діаграмі ключові атрибути підкреслені (рис. 3.31, в).
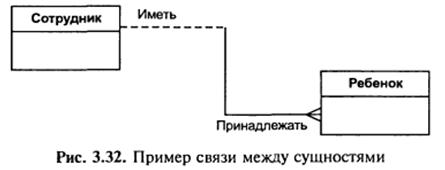
Зв’язок – це відношення однієї сутності до іншої чи до самої себе. Можливо по одній сутності знаходити інші, зв’язані з нею. Наприклад, зв’язки між сутностями можуть виражатись наступними фразами – «СПІВРОБІТНИК може мати декілька дітей», «СПІВРОБІТНИК повинен числитись тільки в одному відділі». Графічно зв’язок зображується лінією, яка з’єднує дві сутності (рис. 3.32).
Кожний зв’язок має одне чи декілька найменувань. Найменування зазвичай виражається невизначеною формою дієслова: «Продавати», «Бути проданим» і т.д. Кожне з найменувань відноситься до свого кінця зв’язку. Іноді найменування не пишуться у зв’язку їх очевидності.
Зв’язок може мати один з наступних типів – рис 3.33.

Зв’язок типу один-до-одного означає, що один екземпляр першої сутності зв’язаний тільки з одним екземпляром другої сутності. Такий зв’язок частіше всього свідчить про те, що ми неправильно розділили одну сутність на дві.
Зв’язок типу один-до-багатьох означає, що один екземпляр першої сутності зв’язаний з декількома екземплярами другої сутності. Це найбільш часто використовуваний тип зв’язків. Приклад такого зв’язку наведено на рис. 3.32.
Зв’язок типу багато-до-багатьох означає, що кожен екземпляр першої сутності може бути зв’язаний з декількома екземплярами другої сутності, і навпаки. Тип зв’язку багато-до-багатьох є тимчасовим типом зв’язку, допустимим на ранніх етапах розробки моделі. В подальшому такий зв’язок необхідно замінити двома зв’язками типу один-до-багатьох шляхом створення проміжкової сутності.
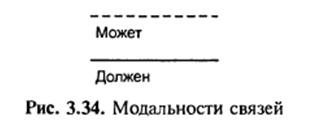
Кожен зв’язок може мати один з двох модальностей зв’язку (рис. 3.34).
Зв’язок може мати різну модальність з різних кінців, як на рис. 3.32. Кожен зв’язок може бути прочитаний як зліва направо, так і справа наліво. Зв’язок на рис. 3.32 читається так:
зліва направо: «Співробітник може мати декілька дітей»;
справа наліво: «Дитина повинна належати точно одному співробітнику».
Приклад розробки простої ER-діаграми
Необхідно розробити інформаційну систему по замовленню деякої оптової торгової фірми, яка повинна виконувати наступні дії:
– зберігати інформацію про покупців;
– друкувати накладні на продані товари;
– слідкувати за наявністю товарів на складі.
Виділимо всі іменники в цих реченнях – це будуть потенційні кандидати на сутності та атрибути, і проаналізуємо їх (незрозумілі терміни будемо виділяти знаком питання):
– Покупець – явний кандидат на сутність.
– Накладна – явний кандидат на сутність.
– Товар – явний кандидат на сутність.
– (?)Склад – а взагалі, скільки складів має фірма? Якщо декілька, то це буде кандидатом на сутність.
– (?)наявність товару – це, скоріше за все, атрибут, але атрибут якої сутності?
Одразу виникає очевидний зв’язок між сутностями – «покупці можуть купляти багато товарів» і «товари можуть продаватись багатьом покупцям». Перший варіант діаграми виглядає, як показано на рис. 3.35.
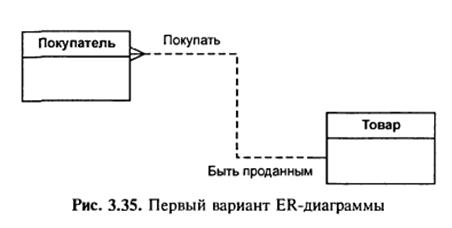
Задавши додаткові запитання менеджеру, ми вияснили, що фірма має декілька складів. Причому кожен товар може зберігатись на декількох складах і бути проданий з будь-якого складу.
Куди помістити сутності «Накладна» і «Склад» і з чим їх зв’язати? Як зв’язані ці сутності між собою і з сутностями «Покупець» і «Товар»? Покупці купують товари, отримуючи при цьому накладні, в які внесені дані про кількість і ціну купленого товару. Кожен покупець може отримати декілька накладних. Кожна накладна повинна містити декілька товарів (не буває порожніх накладних). Кожен товар, в свою чергу, може бути проданий декільком покупцям по декільком накладним. Крім того, кожна накладна повинна бути виписана з певного складу, і з будь-якого складу може бути виписано багато накладних. Таким чином, після уточнення діаграма буде виглядати наступним чином (рис. 3.36).
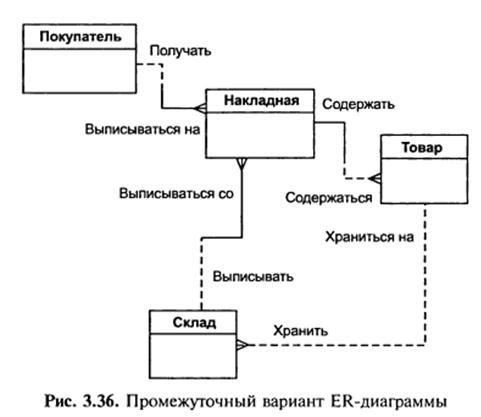
Пора подумати про атрибути сутностей. Спілкуючись зі співробітниками фірми, ми вияснили наступне:
– кожен покупець є юридичною особою і має найменування, адресу, банківські реквізити;
– кожен товар має найменування, ціну, а також характеризується одиницями виміру;
– кожна накладна має унікальний номер, дату виписки, список товарів з кількостями і цінами, а також загальну суму накладної. Накладна виписується з певного складу і на визначеного покупця;
– кожний склад має свою назву.
Знову випишемо всі іменники, які будуть потенційними атрибутами, і проаналізуємо їх:
– Юридична особа – термін риторичний, ми не працюємо з фізичними особами. Не звертаємо уваги;
– Найменування покупця – явна характеристика покупця;
– Адреса – явна характеристика покупця;
– Банківські реквізити – явна характеристика покупця;
– Найменування товару – явна характеристика товару;
– (?) Ціна товару – схоже, що це характеристика товару. Чи відрізняється ця характеристика від ціни в накладній?
– Одиниця виміру – явна характеристика товару;
– Номер накладної – явна унікальна характеристика накладної;
– Дата накладної – явна характеристика накладної;
– (?)Список товарів накладної – список не може бути атрибутом. Імовірно, потрібно виділити цей список в окрему сутність;
– (?)Кількість товару в накладній – це явна характеристика, але характеристика чого? Це характеристика не просто «товару», а «товару в накладній»;
– (?)Ціна товару в накладній – знову ж це повинна бути не просто характеристика товару, а характеристика товару в накладній. Але ціна товару вже зустрічалась вище – це одне і теж?
– Сума накладної – явна характеристика накладної. Ця характеристика не є незалежною. Сума накладної рівна сумі вартості всіх товарів, які входять в накладну;
– Найменування складу – явна характеристика складу.
Під час додаткової розмови з менеджером вдалось вияснити різні поняття цін. Виявилось, що кожний товар має деяку поточну ціну. Це ціна, по якій товар продається в даний момент. Істотно, що ця ціна може змінюватись з часом. Ціна одного і того ж товару, в різних накладних, виписаних в різний час, може бути різною. Таким чином, є дві ціни – це ціна товару в накладній і поточна ціна товару.
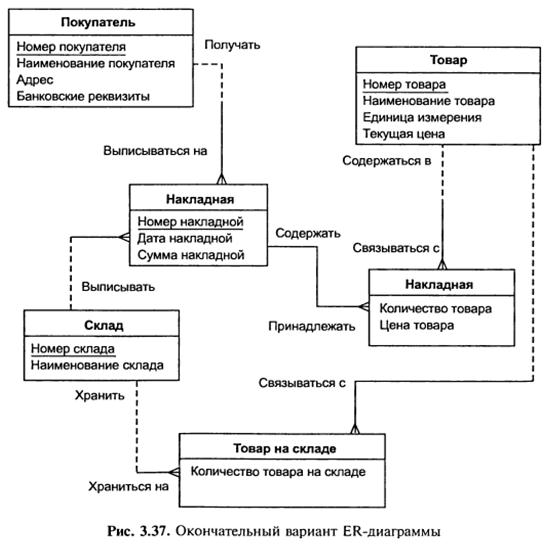
З виникаючим поняттям «Список товарів в накладній» все досить ясно. Сутності «Накладна» і «Товар» зв’язані одна з одною відношенням типу багато до багатьох. Такий зв’язок, як ми відмічали раніше, повинен бути розщеплений на два зв’язки типу один-до-багатьох. Для цього потрібна додаткова сутність. Цією сутністю і буде сутність «Список товарів в накладній». Зв’язок її з сутностями «Накладна» і «Товар» характеризується наступними фразами – «кожна накладна повинна мати декілька записів із списку товарів в накладній», «кожний запис із списку товарів в накладній повинна включатись тільки в одну накладну», «кожен товар може включатись в декілька записів із списку товарів в накладній», «кожен запис із списку товарів в накладній повинна бути зв’язана тільки з одним товаром». Атрибути «Кількість товару в накладній» і «Ціна товару в накладній» є атрибутами сутності «Список товару в накладній».
Так саме вчинимо зі зв’язком, який з’єднує сутності «Склад» і «Товар». Введемо додаткову сутність «Товар на складі». Атрибутом цієї сутності буде «Кількість товару на складі». Таким чином, товар буде числитись на будь-якому складі і його кількість на кожному складі буде своя.
Тепер можна внести все це в діаграму (рис. 3.37).
3.6. Аналіз вимог і визначення специфікацій при об’єктному підході
При об’єктному підході до програмування моделі розроблюваної системи ґрунтуються на предметах і явищах навколишнього світу.
Модель – спрощене представлення реальності. З точки зору програмування модель – це креслення системи. Моделювання необхідне для наступних задач [4]:
1) візуалізація системи;
2) визначення її структури і поведінки;
3) отримання шаблону, який потім дозволить сконструювати систему;
4) документування прийнятих рішень, використовуючи отримані моделі.
Для розв’язання цих задач при описанні поведінки програмного забезпечення в наш час використовується UML (Unified Modeling Language) – уніфікована мова моделювання.
3.6.1. Деякі теоретичні відомості про UML
В основі об’єктного підходу до розробки програмного забезпечення лежить об’єктно декомпозиція, тобто представлення розроблюваного програмного забезпечення у вигляді сукупності об’єктів, в процесі взаємодії яких через передачу повідомлень відбувається виконання необхідних функцій.
Для створення моделей аналізу і проектування об’єктно-орієнтованих програмних систем використовують мови візуального моделювання, самою поширеною з яких у наш час є UML.
Специфікація розроблюваного програмного забезпечення при використанні UML об’єднує декілька моделей: логічну, використання, реалізації, процесів, розгортання [1].
Модель використання містить описання функцій програмного забезпечення з точки зору користувача.
Логічна модель описує ключові поняття програмного забезпечення (класи, інтерфейси і т.д.), тобто засоби, які забезпечують його функціональність.
Модель реалізації визначає реальну організацію програмних модулів у середовищі розробки.
Модель процесів визначає організацію обчислень і дозволяє оцінити робото здатність, масштабованість і надійність програмного забезпечення.
Модель розгортання показує, яким чином програмні компоненти розміщуються на конкретному обладнанні.
Всі разом вказані моделі, кожна з яких характеризує визначену сторону проектованого продукту, складають повну модель розроблюваного програмного забезпечення.
Всього UML пропонує дев’ять діаграм, які доповнюють одна одну і входять в різні моделі:
– діаграми варіантів використання;
– діаграми класів;
– діаграми пакетів;
– діаграми послідовності дій;
– діаграми кооперації;
– діаграми діяльності;
– діаграми станів об’єктів;
– діаграми компонентів;
– діаграми розміщення.
На етапі аналізу постановки задачі і вимог до системи використовують діаграми прецедентів, діаграми діяльностей для розшифровки вмісту прецедентів, діаграми станів для моделювання поведінки об’єктів зі складним станом, діаграми класів для виділення концептуальних сутностей предметної області задачі і діаграми послідовності дій.
3.6.2. Визначення прецедентів (варіантів використання)
Розробку специфікацій програмного забезпечення починають з аналізу вимог до функціональності, вказаних в технічному завданні. У процесі аналізу виявляють зовнішніх користувачів розроблюваного програмного забезпечення і перелік основних аспектів його поведінки в процесі взаємодії з конкретними користувачами.
Прецеденти (варіанти використання – Use Cases) – це детальні процедурні описання варіантів використання системи всіма зацікавленими особами, а також зовнішніми системами, тобто всі, хто (або що) може розглядатись як актори (actors) – дійові особи. Це свого роду алгоритми роботи з системою з точки зору зовнішнього світу. Прецеденти є основою функціональних вимог до системи, дозволяє описувати межі проектованої системи, її інтерфейс, а потім стають основою для тестування системи замовником.
У системі від цілі виконання конкретної задачі розрізняють наступні варіанти використання [1]:
– основні, забезпечують виконання функцій системи;
– допоміжні, забезпечують виконання налаштувань системи та її обслуговування;
– додаткові, служать для зручності користувача (реалізуються тільки в тому випадку, якщо не вимагають серйозних затрат будь-яких ресурсів ні при розробці, ні при експлуатації).
Приклад 3.3. Аналіз функціональних вимог і користувачів системи тестування (модуль навчальної системи).
Система тестування перш за все потрібна наступним зацікавленим особам:
– студенту;
– хто складає тести (викладачу);
– викладачу, який приймає іспит;
– співробітнику деканату, який здійснює контроль за успішністю;
– адміністратору мережі і баз даних навчального закладу.
На початковому етапі створення системи ми можемо обмежитись двома важливими для нас ролями діючих осіб:
– студент (той хто тестується);
– адміністратор (викладач, укладач тестів);
Відповідно основні прецеденти (варіанти використання) для нашої системи наступні:
Прецедент для студента:
– П1 – пройти тестування.
Прецеденти для адміністратора:
– П2 – створити/змінити тест;
– П3 – подивитись результати тестування;
– П4 – добавити/змінити користувачів та ін.
Варіант використання можна описати коротко чи детально. Коротка форма описання містить назву варіанта використання, його ціль, дійових осіб, тип варіанту використання (основний, другорядний чи додатковий) і його коротке описання [1].
Коротке описання варіанту використання для даного прикладу:
| Назва варіанту | Проходження тесту |
| Ціль | Отримання оцінки |
| Дійові особи (актори) | Студент |
| Коротке описання | Реєстрація студента, запуск тесту, вибір відповіді з декількох запропонованих чи введення відповіді, завершення тесту, отримання оцінки |
| Тип варіанту | Основний |
Детальне описання варіанту використання Проходження тесту
| Дії користувача | Реакція системи |
| 1. Студент вводить свої дані (ФІО, Група), тобто реєструється в системі | 2. система створює на диску файл з результатом тестування і пропонує вибрати тест |
| 3. Студент вибирає тест | 4. Система запускає тест |
| 5. Студент послідовно відповідає на запитання | 6. Система реєструє правильні і неправильні відповіді |
| 7. Студент завершує тестування | 8. Система підраховує процент правильних відповідей |
| 9. Студент очікує результат | 10. Система демонструє результат і пропонує зберегти його |
| 11. Студент вирішує, зберегти результат чи ні | 12. Якщо вибрано збереження, система записує результат у файл |
| 13. Студент завершує роботу | 14. Система завершує роботу |
Для більшої наочності використовують діаграми варіантів використання
Діаграми варіантів використання
На рис. 3.38 показано умовні позначення, які використовують при зображенні діаграм прецедентів [48].
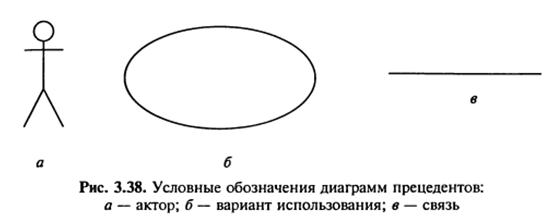
Діаграма прецедентів для вищеописаного прикладу буде мати вигляд (рис. 3.39).
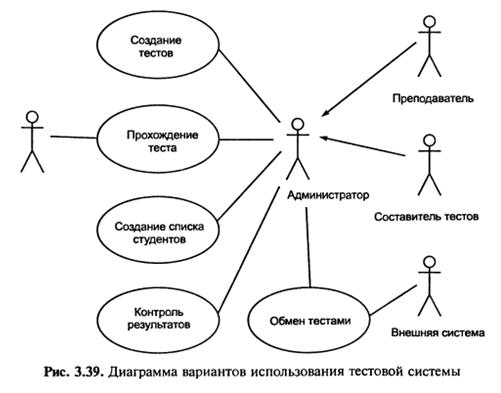
Відповідно, всі варіанти використання визначити, як правило, не вдається: нові варіанти фіксують постійно, навіть в процесі експлуатації. Але чим більше варіантів виявлено в процесі уточнення специфікацій, тим краще, так як при цьому отримують більш точну модель предметної області, що зменшує ймовірність її перегляду при додаванні функцій.
3.6.3. Побудова концептуальної моделі предметної області
Діаграми класів
Провідне місце в об’єкто-орієнтованоу підході до проектування програмного забезпечення займає розробка логічної моделі системи у вигляді діаграми класів (class diagram) [1, 48].
UML пропонує використовувати три рівня діаграм класів у залежності від ступені їх деталізації:
– концептуальний рівень, на якому діаграми класів відображають зв’язки між основними поняттями предметної області;
– рівень специфікацій, на якому діаграми класів відображають зв’язки об’єктів цих класів;
– рівень деталізації, на якому діаграми класів безпосередньо показують поля і операції конкретних класів.
Кожну з перерахованих моделей використовують на конкретному етапі розробки програмного забезпечення:
– концептуальну модель – на етапі аналізу;
– діаграми класів рівня специфікації – на етапі проектування;
– діаграми класів рівня реалізації – на етапі реалізації.
Діаграма класів може показувати різні взаємозв’язки між окремими сутностями предметної області, такими як об’єкти і підсистеми, а також описує їх внутрішню структуру і типи відношень. Діаграми класів зазвичай містять наступні сутності:
– класи;
– інтерфейси;
– кооперації;
– відношення залежності, узагальнення і асоціації.
Коли говорять про дану діаграму, мають на увазі статичну структурну модель проектованої системи, тому діаграму класів прийнято вважати графічним представленням таких взаємозв’язків логічної моделі системи, які не залежать від часу [48].
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 5688; Нарушение авторских прав?; Мы поможем в написании вашей работы!