КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Эффективность параллельных компьютеров и программ
|
|
|
|
Эффективность процессорной основы суперкомпьютеров низка, но хуже то, что КПД суперкомпьютера в целом относительно данного значения увеличиться никак не может, а может стать только еще меньше. На скорость исполнения параллельной программы оказывает влияние сразу целое множество факторов, поэтому анализ эффективности необходимо проводить комплексно, последовательно рассматривая все основные уровни: алгоритмы прикладной программы, системы разработки ПО, системное ПО, структура компьютера.
Эффективность ядер процессоров мы уже оценили, а далее, на основе какого-то числа процессоров (а это сотни, тысячи и десятки тысяч) формируется суперкомпьютер в целом, что добавляет множество новых поводов опять задуматься об эффективности. В суперкомпьютерах с общей памятью, которые сегодня имеют структуру ccNUMA, появляется неоднородность времени доступа к оперативной памяти, а также проблемы обеспечения корректности данных в кэш-памяти (cache coherence). Заметим, что раньше это было свойственно только классическим суперкомпьютерам типа HP Superdome, IBM Regatta или SGI Altix, но сегодня это становится характерной чертой всех многоядерных систем. В суперкомпьютерах с распределенной памятью (Cray XT, IBM BlueGene, кластеры) необходимо учитывать влияние латентности и скорости передачи данных в коммуникационной среде. На КПД работы любого суперкомпьютера скажется неравномерность распределения работы между отдельными вычислительными узлами и процессорами. Эффективность суперкомпьютера может свести к нулю и бич параллельных вычислений – закон Амдала, согласно которому, если в программе 1% всех операций является последовательным (что, вроде бы и не много), то вне зависимости от числа используемых процессоров ускорения больше 100 получить нельзя. С каким КПД будет работать суперкомпьютер из 1000 процессоров на данной программе? Страшно даже подумать, а одновременно с законом Амдала наложатся и все другие упомянутые проблемы.
Много хлопот доставляет неэффективность взаимодействия программы пользователя с программно-аппаратной средой суперкомпьютера. И беда в том, что во многих случаях пользователю необходимые данные о работе его программы просто недоступны. Посмотрим на данные мониторинга динамики выполнения параллельной программы, показанные на рис. 3. Классическая ситуация. Сначала задача на всех узлах считается с максимальной эффективностью: левые области всех картинок верхнего ряда закрашены полностью, что говорит об использовании двухпроцессорных узлов суперкомпьютера на 100%. Затем в некоторый момент эффективность резко падает. Начинаем исследовать причины: одновременно с падением эффективности видим усиление свопинга (третий ряд) на фоне отсутствия каких-либо иных процессов, которые могли бы мешать работе программы (второй ряд, значение параметра loadaverage равно 2, т.е. числу процессоров на узле), и отсутствия обменов в сети (нижний ряд). Теперь становится понятным источник проблем: недостаток оперативной памяти. Увы, несмотря на их очевидную полезность, с такими данными, как правило, работает только системный администратор, а к пользователю они попадают редко.
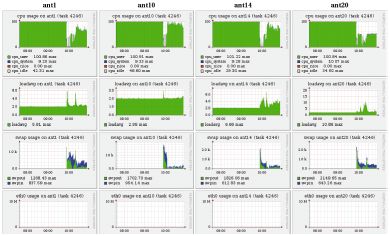
Рис. 3.
Весьма поучительный пример показан на рис. 4а. Из него ясно следует, что КПД работы суперкомпьютера определяется не только квалификацией пользователей, но и аккуратной настройкой системного окружения администраторами. Более того, пользователям разобраться самостоятельно в таких ситуациях почти невозможно. По серому цвету верхней половины верхней диаграммы видно, что двухпроцессорный узел используется лишь наполовину, один процессор все время простаивает – на узле выполняется однопроцессорная задача. Работа другого процессора (нижняя часть верхней диаграммы) регулярно прерывается, причем с той же периодичностью резко возрастает как значение параметра loadaverage (вторая диаграмма сверху), так и активность обмена страницами оперативной памяти (нижняя диаграмма) при отсутствии сколько-нибудь заметного использования области свопинга (вторая диаграмма снизу). В системе явно порождаются новые более приоритетные процессы, захватывающие процессор на значительное время. Детальный разбор показывает, что причиной такой ситуации стала ошибка в одной строке таблицы программы cron, в результате которой трудоемкая системная операция, обычно запускаемая раз в неделю, выполнялась намного чаще.
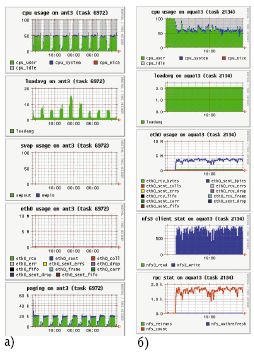
Рис. 4.
Падение эффективности работы программы (рис. 4б) вызвано другими причинами. С параметром loadaverage никаких проблем нет, его значение всегда около 2. Зато резко возрастает активность работы с сетевым диском (вторая диаграмма снизу, nfs_client), и пользовательский процесс ждет завершения операций записи на диск. Кстати, плохо организованная работа с сетевыми дисками часто является причиной низкой эффективности работы суперкомпьютеров в целом. Причем слова «плохо организованная работа» могут относиться и к конструкторам суперкомпьютерного проекта, и к администраторам, и к пользователям. Конструкторы могли бы учесть специфику будущих задач и предусмотреть для передачи файлов, скажем, не Gigabit Ethernet, а подумать об использовании намного более эффективных решений, например, на основе Panasas. Администраторы могли бы проверить эффективность установки NFS на своей системе и изменить значения ключевых параметров, выставляемых автоматически по умолчанию, в некоторые средние значения. Пользователь, в свою очередь, вполне мог бы задуматься о том, что на кластере есть как сетевые, так и локальные диски.
Исключительно серьезный срез, существенно определяющий эффективность работы суперкомпьютера, но который сегодня почти всегда игнорируется – анализ эффективности алгоритма, заложенного в программу. Причины, по которым выбирается тот или иной алгоритм, могут быть самыми разными, например, исторические предпочтения разработчиков, которые на протяжении многих лет использовали только определенные методы и не хотят подстраиваться под современные реалии. Это могут быть и соображения другого рода, например, необходимость быстрого получения конкретного результата, когда вопросы эффективности сознательно отодвигаются на второй план.
В этой связи отличной иллюстрацией является школьная задачка определения количества всех счастливых билетов, имеющих шестизначный номер. Билет считается счастливым, если сумма первых трех цифр равна сумме последних. После непродолжительных раздумий, можно предложить примерно следующий вариант программы:
count = 0;
for (I1 = 0; I1 < 10; ++I1)
for (I2 = 0; I2 < 10; ++I2)
for (I3 = 0; I3 < 10; ++I3)
for (I4 = 0; I4 < 10; ++I4)
for (I5 = 0; I5 < 10; ++I5)
for (I6 = 0; I6 < 10; ++I6) {
if(I1 + I2 + I3 == I1 + I5 + I6) ++count;
}
Число счастливых билетов будет выдано почти любым современным компьютером мгновенно, а что если количество цифр в номере будет увеличиваться? Для 8 цифр ответ будет выдан быстро, для 10 компьютер немного задумается, для 12 цифр ему потребуется больше часа, а для 14 цифр у вас не хватит терпенья дождаться ответа. Почему?
Сложность нахождения ответа, если действовать по данному алгоритму, равна 10N, где N – количество цифр в номере билета. Можно пытаться это время сократить, выполняя оптимизацию данного алгоритма, например, принимая в расчет соображения симметрии. Однако эффект от этого будет небольшой, вероятно сможет продвинуться на шаг и найти ответ для следующего значения, не для 14, а для 16 цифр. Альтернативный вариант, который кажется весьма разумным – предложить эту задачку суперкомпьютеру. Потенциал параллелизма в алгоритме огромен – если в суперкомпьютере будет 10 тыс. процессоров, значит можно эффективно использовать их все. Однако ускорение в 10000 раз в плане решения задачи позволит сделать лишь еще пару шагов – найти решение для числа цифр 20 или 22, но дальше все равно с этим алгоритмом не продвинуться.
Данный алгоритм мы реализовали быстро, он простой, но чудовищно неэффективный. Поразмышляв минут 20-30 можно найти другой алгоритм со сложность уже не 10N, а всего лишь N2. Для такого алгоритма решить задачу для 100 или 1000 цифр вообще не проблема даже на обычном ПК. Это заставляет задуматься, а часто ли авторы программ для суперкомпьютеров утруждают себя оценкой эффективности своих алгоритмов или же, как в случае первого алгоритма, суперкомпьютеры работают вхолостую?
Говоря о КПД суперкомпьютеров, нельзя не сказать и об организации работы самих суперкомпьютерных центров. В самом деле, если в некоторых центрах суперкомпьютер на выходные выключают, то показатели его эффективности можно смело умножать на 5/7. Если вычислительные узлы, содержащие по два четырехъядерных процессора, часто блокируются под монопольное выполнение последовательных задач, то КПД умножается еще на 1/8. Для запуска программы на 1000 процессорах, стоящей в очереди пользовательских заданий, требуется дождаться освобождения всех 1000 процессоров. Однако это происходит постепенно, освобождающиеся от других заданий процессоры приходится блокировать, пока не будет набрано необходимое число, а заблокированные процессоры простаивают, но общее КПД суперкомпьютера от всего этого не увеличивается.
Если эффективность работы суперкомпьютера на отдельной параллельной программе еще можно оценить некоторой заметной величиной, то многие суперкомпьютерные комплексы явно не дотягивают даже до КПД паровоза. Необходима целенаправленная работа по сертификации эффективности параллельных программ и вычислительных систем.
Контрольные вопросы
1. Почему необходима оценка производительности параллельных вычислительных систем?
2. Какие используются способы оценки производительности параллельных вычислительных систем?
3. Какие основные особенности теста LINPACK?
4. Что такое пиковая производительность параллельных вычислительных систем?
5. Что такое реальная производительность параллельных вычислительных систем?
6. Насколько могут отличаться пиковая и реальная производительность вычислительных систем?
7. Какие «узкие места» процесса решения задач существенно влияют на реальную производительность параллельных вычислительных систем?
8. Как влияет на реальную производительность параллельных вычислительных систем иерархическая структура оперативной памяти?
9. Как влияют на реальную производительность параллельных вычислительных систем языки программирования?
10. Как влияет на реальную производительность параллельных вычислительных систем структура параллельных вычислительных систем?
11. Закон Амдала
12. Как необходимо использовать закон Амдала?
13. Как влияет на реальную производительность параллельных вычислительных систем соответствия их структуры и структуры программ?
14. Какие факторы определяют реальную производительность МВС с общей оперативной памятью?
15. Какие факторы определяют реальную производительность кластерных систем с распределённой оперативной памятью?
|
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 444; Нарушение авторских прав?; Мы поможем в написании вашей работы!