КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Выполнение программы darpa HPCS
|
|
|
|
Производительность и программное обеспечение
Перспективные суперкомпьютеры тера- и экзафлопного масштаба
В соответствии с программы США DARPA HPCS планировалось достичь к 2010 г. следующих показателей суперкомпьютеров:
1. Реальная производительность – более 2 PFLOPS (на тесте Linpack).
2. Объем глобально адресуемой оперативной памяти – несколько петабайт (1015) байт
3. Пропускная способность памяти при регулярных обращениях - 6.5 * 1015 байт (на тесте STREAM).
4. Пропускная способность памяти при нерегулярных обращениях - 64000 GUPS (на тесте Random Access).
5. Бисекционная пропускная способность системной коммуникационной сети - 3.2 * 1015 байт (тест BISECT).
6. Высокая реконфигурируемость и адаптируемость к задачам.
7. Распределенная общая память.
8. В 10 раз увеличенная производительность программирования по отношению к уровню 2005 г.
Производительность вычислительных систем в соответствии с программой DARPA HPCS, планировалось повысить на порядок. Производительность — сложное понятие, связанное как с используемыми аппаратными средствами, так и со средствами и технологиями программирования. Предполагалось, что создаваемые системы будут программироваться на языках более высокого уровня (класс языков PGAS), чем применяемые сегодня Фортран и Си. Фундаментальным свойством этих языков, которое приведет к более простому и эффективному программированию задач, будет работа с глобально адресуемой памятью, в которой возможно выделение эффективно доступных подобластей.
Программная модель PGAS (Partitioned Global Address Space— «разделенное глобальное адресное пространство») предусматривает поддержку на уровне синтаксических конструкций языка программирования глобального адресного пространства и выделения в нем подобластей, отображаемых на локальную физическую память. Другими словами, в модели PGAS обеспечивается прозрачный доступ к оперативной памяти всех вычислительных узлов с учетом неравномерной задержки выполнения команд обращений к памяти. Обязательной составляющей являются средства управления локализацией данных и вычислений за счет распределения данных и удаленного вызова процедур.
Выполнение второй фазы программы DARPA HPCS было начато в 2003 году силами компаний IBM, Cray и Sun (проекты PERCS, Cascade и HERO соответственно). Третья — заключительная — фаза завершилась в 2010 году созданием опытных образцов. К ее выполнению 21 ноября 2006 года были допущены фирмы IBM и Cray.
Фирма Cray выполняла проект для Окриджской лаборатории, применяя в качестве базовых элементов процессор Opteron, коммуникационный сопроцессор Gemini и маршрутизатор YARC, реализующие 14-мерный гиперкуб.
Фирма IBM осуществляла проект Roadrunner для Лос-Аламосской лаборатории на процессорах Cell и Opteron и коммуникационной сети Infiniband.
На рис. 4 приведена концептуальная структура системы Cascade (разаработчик фирма Cray) — гетерогенного стратегического суперкомпьютера, содержащего вычислительные узлы, непосредственно разрабатываемые по проекту, а также вычислительные узлы на коммерческих процессорах и сервисные узлы на коммерческих процессорах.
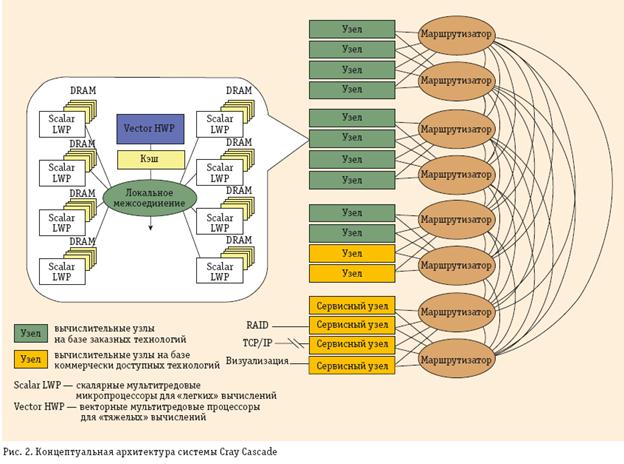
Рис. 4
Основные принципы структуры суперкомпьютера Cascade:
· глобально адресуемая память с унифицированной для всех типов узлов структурой;
· конфигурируемые сеть, память, процессоры и ввод/вывод;
– гетерогенная обработка на множестве узлов разного типа и внутри потоково-векторных (MVP) узлов;
· возможность адаптации при конфигурировании, компиляции, а также в процессе выполнения.
Необходимая вычислительная мощность достигается благодаря заказным узлам, использующим структурные принципы мультитредовости (многопотоковости), разделения вычислений, доступа к памяти по разным процессам, принцип размещения обработки вблизи модулей памяти.
Vector HWP— это векторный мультитредовый мультипроцессор, способный эффективно выполнять вычисления с подготовленными ему данными в быстродействующей памяти. Предварительную «накачку» данных для этого процессора и простые вычисления (например, адресные) осуществляют скалярные мультитредовые (многопоточные) процессоры Scalar LWP, которые находятся вблизи микросхем памяти DRAM и хорошо справляются с задачами, отличающимися плохой пространственно-временной локализацией.
Вычислительная сеть (Router) связывает вычислительные узлы всех типов с модулями распределенной памяти, доступной через единое глобальное адресное пространство. Основное требование к этой сети— высокая пропускная способность на коротких пакетах, что и отражено в требованиях по развиваемой бисекционной пропускной способности сети (см. табл. 1). В этом случае толерантные (за счет мультитредовости) к задержкам обращений к памяти процессоры могут использовать ее высокую пропускную способность и работать на темпе выполнения обращений, а не на их задержках.
Оперативная память с высокой пропускной способностью— еще одна проблема, особенно при обращениях с непредсказуемой нерегулярностью (RandomAccess). Именно поэтому в табл. 1 указаны такие высокие требования к ней.
В качестве языка программирования использовался Chapel, который должен еще быть принят программистским сообществом.
Работа по проекту Cascade задумывалась грандиозная, но жизнь, как это бывает, внесла свои коррективы, сделав первые реализации менее амбициозными.
Разработчики фирмы Cray выбрали прагматичный путь выполнения проекта (рис. 3), добавив новые вычислительные средства, основанные на перспективных структурных концепциях, к уже хорошо зарекомендовавшим себя процессорам Opteron. При этом задачи разработки процессорных СБИС мультитредового типа не снимаются с повестки дня, просто они разрабатываются пока в упрощенном виде, что снижает технические риски: наличие процессоров Opteron в узле позволяет подстраховаться в случае неудачных аппаратных решений при разработке компонентов с новой структурой.
Заключительная фаза разработки системы Cray Cascade в рамках DARPA HPCS состоит из трех этапов: Baker, Granite и Marble (рис. 5).
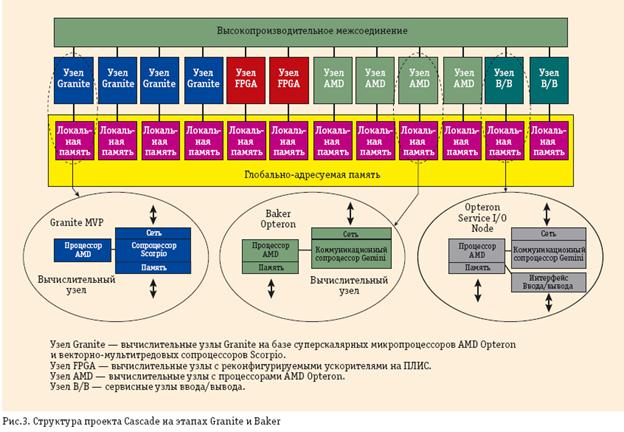
Рис. 5.
На первом этапе создается коммуникационный сопроцессор Gemini, имеющий интерфейс с разными системами фирмы Cray, включая новый векторный процессор BlackWidow. Для построения сети используется кристалл YARC сети Клоса, созданный совместно со специалистами Стэнфордского университета. Коммуникационный сопроцессор Gemini оптимизирован под особенности MPI и эффективно выполняет обращения к удаленным узлам. В нем реализована трансляция виртуальных адресов глобально адресуемой памяти и выполнение легких тредов (потоков) для фрагментов задач с плохой пространственно-временной локализацией. Предусмотрены две версии этого коммуникационного сопроцессора.
На втором этапе создается мощный векторно-потоковый сопроцессор Scorpio, который должен резко повысить возможности вычислительного узла, усилив его толерантность к задержкам обращений к оперативной памяти за счет векторной и потоковой организации.
На данный момент Vector HWP воплотился в конкретном сопроцессоре Scorpio, а Scalar LWP— в коммуникационном процессоре Gemini. В системе появились и узлы с реконфигурируемой структурой на базе программируемых логических матриц (FPGA Compute Nodes, рис. 5).
Что будет реализовано на этапе Marble — пока неизвестно; возможно, произойдет возвращение к первоначальному проекту. По поводу подготавливаемых в фирме Сray технологий программирования можно сказать, что на этапе Baker явно лидируют технология MPI в сочетании с языками Фортран и Cи, средством мультитредового программирования OpenMP и прошедшими практическую проверку языками класса PGAS— UPC и Co-Array Fortran (CAF). Активные попытки внедрить UPC и CAF заметны в уже упоминавшемся семействе Cray XT5.
О работе IBM по программе DARPA HPCS информации мало. Известно лишь, что в создаваемом стратегическом суперкомпьюетере будет применен процессор Power 7 и разрабатывается язык нового поколения X10. Некоторые специалисты утверждают, что создается 128-потоковая версия процессора Power 7. Какая из множества имеющихся разработок будет выбрана (Cyclops64, TRIPS, HPC Cell), пока неясно. Однако в создании системы Roadrunner также заметен прагматичный подход— мощный, но капризный при работе с данными процессор Cell объединяется с Opteron, который может взять на себя подкачку части данных для реализации задач с плохой пространственно-временной локализацией.
Программа DARPA HPCS закрыла для США технологическую брешь лишь на ближайшие до 2015 года. Дальнейшее развитие требует более радикальных мер, что и предусмотрено в программе США DARPA UHPC.
|
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 508; Нарушение авторских прав?; Мы поможем в написании вашей работы!