КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Кодирование речи в гибридных кодерах
|
|
|
|
Гибридные кодеры речевой информации основаны на комбинации линейного предсказания с элементами кодирования формы сигнала, т.е. звуковой волны. Так, в алгоритме линейного предсказания с возбуждением от остатка предсказания (RELP) (см. табл. 6.1) наряду с передачей вокодерных параметров (коэффициентов линейного предсказания и усиления) осуществляется передача сигнала остатка (ошибки) предсказания в полосе частот 0...800 Гц. Сигнал остатка предсказания приблизительно равен сигналу возбуждения голосового тракта модели речеобразования, поэтому в алгоритме RELP он используется в синтезаторе декодера для возбуждения синтезирующего фильтра. Формируемый в результате речевой сигнал звучит более естественно.
Большинство гибридных кодеров используют замкнутое кодирование на основе линейного предсказания, называемое также методом «анализ через синтез» (AbS).
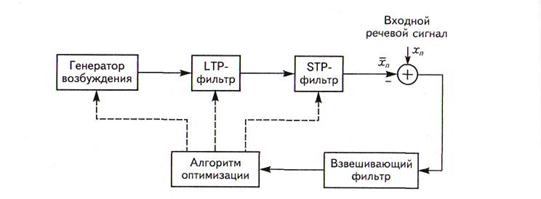
Рисунок 7.13 Схема речевого кодера, использующего метод «анализ через синтез»
Кодер «анализ через синтез» это речевой синтезатор, который генерирует сигнал, подобный объекту кодирования - речевому сигналу. Взвешенная разность между обоими сигналами представляет собой функцию стоимости, используемую для корректировки параметров речевого синтезатора. Синтезатор состоит из генератора возбуждения, фильтра долговременного предсказания (англ. Long-Term Prediction - LTP) и фильтра кратковременного предсказания (англ. Short-Term Prediction - STP). STP-фильтр моделирует краткосрочную корреляциюречевого сигнала, т.е. восстанавливает огибающую спектра. LTP-фильтр отражаетдолгосрочную корреляцию, т.е. формирует точную спектральную структуру речевого сигнала. Как и в предыдущем примере, объектами передачи являются параметры LTP- и STP-фильтров, а также параметры сигнала возбуждения.
Одной из первых реализаций метода анализа через синтез (1982 г.) является алгоритм линейного предсказания с многоимпульсным возбуждением (MPE), используемый в системах спутниковой связи.
В многоимпульсном возбуждении сигнал остатка линейного предсказания представляется в виде последовательности импульсов с неравномерно распределенными интервалами и с разными амплитудами. Число импульсов в каждом кадре речевого сигнала зависит от требуемого качества речи, чем больше импульсов, тем выше качество речи. На каждом кадре в 10 мс речевого сигнала считается достаточным 6...8 импульсов (или 8 импульсов на период основного тона) для получения высокого качества синтезированной речи.
Установлено, что для вокализованного РС многоимпульсное возбуждение можно упростить, представив его в виде последовательности равномерно расположенных импульсов (обычно 10 импульсов на интервале 5 мс). В методе возбуждения регулярной импульсной последовательностью (RPE) взаимное положение импульсов предопределено заранее - используют решетку равноотстоящих импульсов, а оптимизируют расположение решетки и амплитуды импульсов.
В 1984 году, как естественное развитие многоимпульсного метода возбуждения, было предложено так называемое векторное кодирование (VQ), когда кодируется одновременно группа параметров, характеризующих позиции импульсов и их амплитуды. В этом случае в качестве сигнала возбуждения используется последовательность отсчетов (т.е. “ вектор ”), взятая из заданного набора этих последовательностей (т.е. из “ кодовой книги векторов ”). Входной вектор, представляющий собой образец входного РС, сравнивается с векторами, находящимися в кодовой книге, и находится вектор, наиболее близкий к входному. Критерием выбора вектора часто становится минимизация среднеквадратичной ошибки между образцом входного сигнала и вектором. Каждому “вектору” из этой “книги” соответствует свой адрес - индекс (номер), который и передается по каналу связи на приемную сторону. На рисунке 7.14 изображен процесс кодирования.
На приемной стороне в декодере используется точно такая же кодовая книга, из которой по индексу извлекается требуемый вектор. Таким образом, снижение скорости в результате использования VQ достигается путем передачи на прием только номера (индекса) вектора с масштабным коэффициентом.
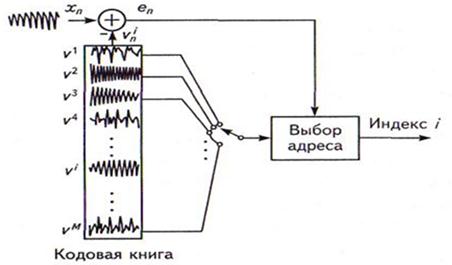
Рисунок 7.15 – Принцип векторного квантования
Векторное кодирование лежит в основе метода стохастического кодирования, или метода линейного предсказания с кодовым возбуждением (англ. Code-Excited Linear Prediction - CELP). Частными случаями CELP являются методы VSELP и ACELP.
Кодер CELP реализует процедуру анализа через синтез (рис.12.3). Сигнал возбуждения u(h) формируется путем сложения масштабированного сигнала из адаптивной кодовой книги (добавляются долговременные частотные составляющие речевого сигнала) и масштабированного сигнала из большой фиксированной кодовой книги. Полученный сигнал возбуждения управляет синтезирующим фильтром, который моделирует эффекты голосового тракта. В декодере сигнал возбуждения проходит через синтезирующий фильтр, формируя восстановленный речевой сигнал Ŝ(n).
Очевидно, что сначала определяются параметры фильтра, а затем уже находятся индексы кодовых книг а и k и соответствующие коэффициенты усиления G1 и G2. Параметры кодовых книг выбираются так, чтобы минимизировать взвешенную ошибку между исходным речевым сигналом S(n) и восстановленным Ŝ(n), что достигается подачей содержимого каждой «ячейки» кодовой книги на синтезирующий фильтр с целью выявления максимально похожего (по восприятию) образца.
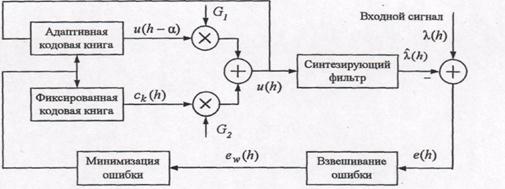
Рисунок 7.16 Блок-схема кодера CELP
В алгоритме VSELP используется не одна большая стохастическая кодовая книга, а две, меньшего размера (128 векторов в каждой). Для эффективности кодирования эти две книги также образуются с помощью нескольких базовых векторов (базиса книги). Базовые вектора взаимно ортогональны друг другу, что обеспечивает и ортогональность самих книг кодовых книг между собой. Структура кодовой книги алгоритма ACELP (с речевой скоростью 7,4 кбит/c) следующая: существует 4 базовых вектора. Различной линейной комбинацией этих векторов и образуются все вектора кодовой книги. Такая жесткая структуризация книги позволяет резко снизить требуемые вычислительные затраты на поиск в ней оптимального вектора.
Кодовые книги бывают детерминированными и стохастическими. Детерминированные книги образуется посредством процесса “обучения”, т.е. заполнения книги векторами, полученными из реальных речевых сигналов. Обучение проводится на достаточно большой длительности (30..40 мин) для нескольких дикторов, на мужских и женских голосах. В отличие от детерминированных, стохастические книги не требуют обучения. Они заполняются случайными гауссовскими последовательностями (отрезками белого шума с нулевым средним и единичной дисперсией). Основанием для использования такой книги в качестве возбуждающей является то, что в системах с линейным предсказанием с двумя предсказателями (кратковременным и долговременным) в сигнале остатка на выходе этих предсказателей практически устранены все корреляционные связи, он имеет случайный характер.
|
|
|
|
Дата добавления: 2013-12-13; Просмотров: 613; Нарушение авторских прав?; Мы поможем в написании вашей работы!