КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Кодирование речи с полной скоростью
|
|
|
|
РЕЧЕВЫЕ КОДЕКИ ДЛЯ АБОНЕНТСКОГО ТЕРМИНАЛА СТАНДАРТА GSM
Основная задача кодера - предельно возможное сжатие сигнала речи, представленного в цифровой форме, - при сохранении приемлемого качества передачи речи. Компромисс между степенью сжатия и сохранением качества отыскивается экспериментально, а проблема получения высокой степени сжатия без чрезмерного снижения качества составляет основную трудность при разработке кодера.
В системе GSM определены три стандарта кодирования речи:
• кодирование речи с полной скоростью(GSM FR);
• кодирование речи с половинной скоростью(GSM HR);
• улучшенноекодирование речи с полной скоростью(GSM EFR).
Этот тип кодирования использует модифицированный метод RPE-LTP - линейное предсказание с возбуждением регулярной последовательностью импульсов и долговременным предсказателем.
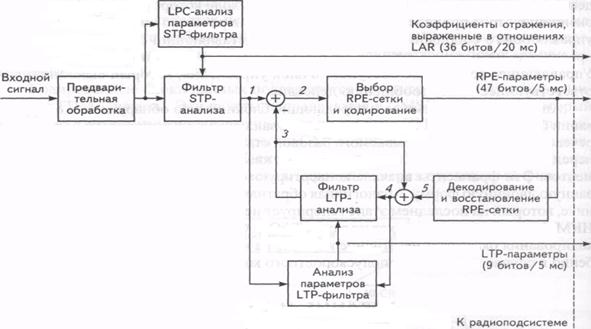
Рисунок 7.17 Блок-схема полноскоростного кодера речи в системе GSM(FR)
Основные требования к кодеру состоят в сокращении избыточности речевого сигнала и обеспечении в перерывах во время пауз передачи речи. Поэтому при передаче речи в системе GSM используется техника прерывистой передачи DTX, означающая, что каждый речевой канал активен не непрерывно.
Блок предварительной обработки кодера осуществляет предыскажение входного сигнала при помощи цифрового фильтра восприятия, подчеркивающего верхние частоты, нарезание сигнала на сегменты по 160 выборок (20 миллисекунд) и взвешивание каждого из сегментов окном Хэмминга. Сигнал с выхода фильтра предыскажений подвергается анализу в соответствии с методом линейного предсказания, в результате чего определяются коэффициенты кратковременного линейного предсказания(STP). Полученные параметры, представляющие собой восемь коэффициентов отражения STP -фильтра, преобразуются в логарифмические отношения площадей (LAR), которые могут быть представлены более компактно, нежели сами коэффициенты отражения. Значения LAR в цифровой форме представляются 36 битами.
Затем найденные коэффициенты кратковременного линейного предсказания используются в фильтре-анализаторе STP для обработки того же самого сегмента входных отсчетов. В результате получаются 160 отсчетов остатка кратковременного предсказания сигнала.
Для дальнейшей обработки 20-мс сегмент остатка кратковременного предсказания z(n) делится на четыре подсегмента длительностью 5 мс, по 40 выборок в каждом. Каждый подсегмент последовательно обрабатывается в блоках кодера по отдельности.
Перед обработкой каждого подсегмента речевой кодер определяет параметры фильтра долгосрочного предсказания(LTP) – (весовой) коэффициент предсказания g и задержку d. Операция выполняется на основе текущего подсегмента остатка STP -предсказания (см. сигнал 1 на рис.7.17) и сохраненной последовательности из трех восстановленных предшествующих подсегментов остатка кратковременного предсказания (см. сигнал 4 на рис.7.7). Подсегмент остатка сигнала (2), прошедшего LTP -фильтр, представляет собой разность между подсегментом приближенных значений прошедшего STP -фильтр остатка сигнала (3) и подсегментом точных STP -фильтрованных значений остатка этого сигнала (1). В результате получается субсегмент остатка долговременного предсказания. После отбрасывания последнего отсчета этот подсегмент направляется в блок-анализатор с возбуждением последовательностью регулярных импульсов(RPE). RPE -анализатор разделяет обрабатываемый подсегмент на три последовательности возбуждения, каждая из которых состоит из 13 импульсов. Для этого производится децимация отсчетов и выбор сигнальной сетки (интервал следования импульсов возбуждения обычно втрое превышает период дискретизации исходного сигнала). Затем вычисляется энергия трех прореженных последовательностей. Последовательность с самой большой энергией выбирается как представляющая весь блок прошедших LTP -фильтр остатков.
Выбранные импульсы возбуждения нормируются по отношению к наибольшей амплитуде и кодируется. Сдвиг сетки также кодируется и вместе со значениями импульсов возбуждения передается на приемник. В результате представление каждого 5-мс подсегмента производится 47-битовым блоком.
Эти же RPE параметры подаются на блок декодирования и восстановления сетки RPE, который выдает подсегмент LTP -остатка (5). После прибавления отсчетов этого сегмента к приближенным значениям STP -остатка получаются реконструированные отсчеты STP -остатка, которые и направляются на вход фильтра долговременного анализа. В результате фильтрации получается новый подсегмент приближенных значений отсчетов остатка кратковременного предсказания, которые используются при обработке следующего подсегмента. В результате применения алгоритма кодирования 20-мс сегмент речи передается 260 битами информации, т.е. кодер речи осуществляет сжатие информации почти в 5 раз (1280: 260 = 4,92), что обеспечивает цифровую скорость передачи Rц = 64/5 @ 13 кбит/с. На рис.13.2 изображена упрощенная схема RPE-LTP -декодера. Он содержит такой же контур обратной связи, как и кодер.
В случае отсутствия ошибок передачи, выходной сигнал этой части декодера восстанавливает последовательность отсчетов остатка кратковременного предсказания. Затем эти отсчеты направляются на вход STP фильтра-синтезатора, после чего обрабатываются блоком постфильтрации для компенсации предыскажений, внесенных фильтром на входе кодера. Сигнал на выходе блока постфильтрации представляет собой восстановленные фрагменты речевого сигнала.
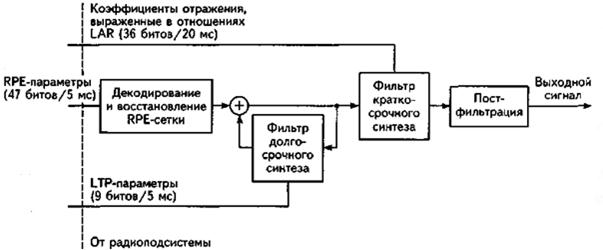
Рисунок 7.18 Блок-схема RPE-LTP -декодера речи
|
|
|
|
Дата добавления: 2013-12-13; Просмотров: 597; Нарушение авторских прав?; Мы поможем в написании вашей работы!