КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
C) оценка эффективности поиска в различных поисковых системах
|
|
|
|
В настоящее время фактографические ИПС (как специальный класс поисковых систем) практически не разрабатываются, выполняемые ими действия реализуются с помощью штатных СУБД. Далее, говоря ИПС, будем иметь в виду документальную информационно-поисковую систему.
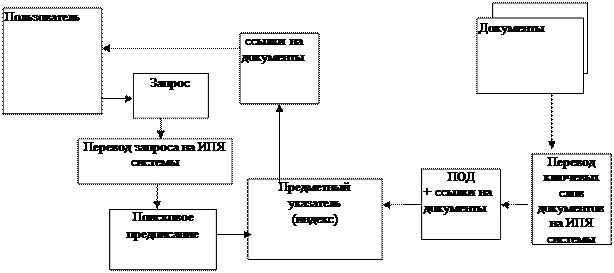
Информационно-поисковая система (ИПС) - программная система для хранения, поиска и выдачи интересующей пользователя (абонента) информации. Абонент обращается к ИПС с информационным запросом. Поиск информации ведется в поисковом массиве. который формируется (и по мере необходимости обновляется) разработчиками или администраторами системы.
Для составления индекса анализируется содержание документа и определяются ключевые слова, отражающие «предмет» или «предметы», о которых идет речь в документе. Затем данные ключевые слова переводятся на информационно-поисковый язык (ИПЯ). ИПЯ составляют тезаурус и грамматика.
Тезаурус - специально организованный нормативный словарь, состоящий из дескрипторов. Дескриптор ставится в однозначное соответствие группе ключевых слов естественного языка, отобранных из текста определенной предметной области. Грамматика содержит правила образования производных единиц языка (семантических кодов, предложений) и регламентирует использование средств обозначения синтаксических отношений (например, указателей связи).). В результате получается поисковый образ документа (ПОД). Поисковый образ документа - текст на информационно-поисковом языке, поставленный в однозначное соответствие документу и отражающий его признаки, необходимые для поиска его по запросу. Проиндексировав все информационные ресурсы, получают индекс ( index database) — основной массив данных ИПС, содержащий ПОД и соответствующие им ссылки на документы.
Так как процесс поиска заключается в сопоставлении запроса пользователя с имеющимися в индексе данными, то запрос также должен быть переведен на ИПЯ.Переведенный на ИПЯ запрос пользователя называется поисковым предписанием.
После сопоставления поискового предписания с поисковыми образами документов пользователь получает список ссылок на документы, которые соответствуют, по мнению системы, его запросу.
Увеличению эффективности ИПС в большой степени помогает более детальная обработка текста документа. Так, существуют системы, которые для простоты в качестве поискового образа документа принимают его название, однако оно в силу разных обстоятельств не всегда формально отражает содержание текста. Например, при подготовке данного материала была использована статья "А глаз как у орла", не имеющая никакого отношения ни к орнитологии, ни к окулистам. Также большое значение имеет применение программ, производящих лингвистически содержательную обработку текстов на естественном языке (учитывающую морфологию, синтаксис). Только с их помощью можно установить, являются ли похожие слова (почти все буквы одинаковые) формами одного слова или же это совершенно разные слова, в соответствие которым поставлены разные семантические единицы.
Более примитивные, лежащие на поверхности приемы могут подвести разработчика ИПС. Так, если система не учитывает никакие правила русского языка и работает с шаблонами (типа var*, text*.exe), то при поиске для Золушки кавалера, интересующегося бальными танцами, в качестве ключевого слова-шаблона придется выбрать бал * (чтобы не было потери информации, иначе можно пропустить эту характеристику, высказанную словами люблю танцевать на балах). Тогда в результате поиска ей может быть предложено познакомиться со всеми любителями балета, балыка, Бальмонта, Бальзака, со всеми, живущими около Балтийского моря, в домах с балконом, а также со всевозможными баловниками и баловнями судьбы.
Все эти претенденты будут отсеяны, если в качестве ключевого слова будет задано прилагательное бальный и система сможет распознавать его во всех его формах (применение морфологического анализа слов также дает возможность уменьшить объем тезауруса, избавив его от избыточной информации - иначе все формы одного слова приходится определять как синонимы). Еще один способ уменьшения шума и повышения точности - введение в информационно-поисковый язык аппарата работы с однокоренными словами. В нашем примере при задании ключа-корня бал выданными оказались бы только документы, содержащие разные формы слов бал и бальный. Однако и в этом случае письмо желанного принца затеряется между сообщениями о салонах бального платья, владельцах бальных залов, музыкантах и официантах, обслуживающих балы. С помощью синтаксического анализа можно более точно определять словосочетания (например, распознавать их не только когда слова стоят друг за другом, но и когда они разделены рядом других слов). В приведенном примере в системе с синтаксическим компонентом можно было бы вести поиск документов со словосочетаниями бальный танец и танцевать на балу. Конечно, и это не обеспечивает 100% точности (например, ничто не запрещает выдачу сообщений об учителях бальных танцев), однако понятно, что количество выданных документов значительно сократится, и Золушка уже не превратится в старую деву, просматривая предложенную ей системой информацию.
Развитые информационно-поисковые языки допускают использование логических связок: дурак =NOT(умный), добрый молодец =(мужчина) AND (молодой). В перспективе - возможность описания на информационно-поисковом языке смысла целой фразы (который не всегда складывается из смыслов входящих в нее слов) и возможность формулировки соответствующих семантически сложных запросов.
Для улучшения результатов поиска необходимо определить степень специфичности терминов, используемых при индексации. Принято использовать два принципа — использование наиболее специфического термина, соответствующего объему и содержанию отражаемого понятия, и избыточное индексирование. Под избыточным индексированием понимается дополнение поискового образа терминами, связанными с основным. При этом могут использоваться термины, связанные как с основным отношением обобщения или спецификации, так и ассоциативной связью. Дополнение поискового образа терминами с ассоциативной связью может увеличить полноту поиска, но неизбежно понижает его точность. Недостатком избыточного индексирования является также увеличение объема поисковых образов. Для решения этой проблемы во многих ИПС используется избыточное индексирование не документов, а запросов. Использование предметного индексирования не исключает использования при создании поискового образа атрибутов документа. Это могут быть такие атрибуты, как данные об авторе, дата публикации, язык публикации и т. д.
ИПС глобальной сети имеет отличия, обусловленные как характером сети, так и особенностями работы пользователей такой системы. Рассмотрим основные особенности использования ИПС в глобальной сети на примере сети Интернет.
Поиск необходимых сведений в Интернет осуществляется двумя типами поисковых систем: либо при помощи поисковых машин (searct engine), либо каталогов (directory). Часто на практике оба типа ИПС могут быть представлены на одном веб-сервере, который принято называть порталом.
Схема ИПС сети Интернет
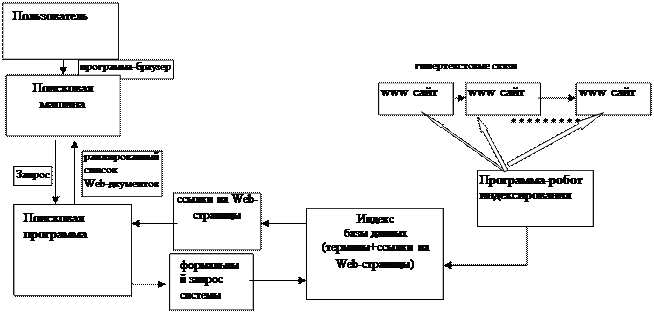
Программа-браузер на этой схеме - это программа просмотра конкретного информационного ресурса. Такая программа обеспечивает просмотр документов WWW, FTP-архивов, почтовых списков рассылки. В качестве примера такой программы можно привести программы Internet Explorer, FireFox, Opera.
Поисковые системы сети Интернет состоят из трех основных частей.
1. Робот/Паук — программа, которая систематически посещает веб-страницы, считывает и индексирует полностью или частично их содержимое и далее следует по найденным ссылкам. Полученная информация заносится в базу данных – индекс поисковой машины.
Современные ИПС в Интернете используют порядка 100 терминов для индексации документа. Выбор терминов, используемых для индексации, зависит от реализации данной системы. Чаще всего первым критерием является отношение частоты употребления термина в документе к частоте употребления этого термина во всех ранее проиндексированных документах. То есть наибольший вес присваивается тем терминам, которые наиболее часто встречаются в данном документе и наиболее редко — во всех остальных проиндексированных документах. Термины, которые используются в очень большом количестве документов, при индексировании не используются совсем.
Для определения терминов индексирования, используемых для создания поискового образа, робот может также использовать разметку индексируемой страницы и в индексе присваивать наибольший вес термину, используемому, например, в заголовке. Автор информационного ресурса также может повлиять на индексацию собственной страницы, указав роботу, какие термины надо использовать для индексирования. Но многие поисковые системы отказались от использования описаний ресурсов, представленных авторами. Это было сделано по причине недобросовестности некоторых авторов, которые использовали для описания своих страниц термины, наиболее часто встречающиеся в запросах.
2. Поисковая база данных (Индекс) представляет собой гигантское хранилище, которое содержит определенным образом организованные данные: термины индексирования, ссылки на веб-страницы и другую дополнительную информацию.
3. Поисковая программа, которая в соответствии с запросом пользователя перебирает индексы в поисках соответствующей информации и выдает результаты поиска в виде ранжированного
списка найденных веб-документов.
Принципы работы программы-паука, способы организации индекса и работа самой поисковой программы в разных поисковых машинах, как правило, различаются. Поэтому запрос по одним и тем же выражениям обычно дает разные результаты в разных поисковых машинах.
Программа поиска отыскивает страницы, которые соответствуют формальным требованиям запроса. Чтобы определить последовательность, в которой отобранные страницы будут представлены пользователю, применяется алгоритм ранжирования. В интересах пользователя документы, наиболее соответствующие потребностям пользователя, должны быть помещены первыми в списке результатов. Поисковые системы используют различные алгоритмы ранжирования, однако основные принципы определения соответствия документов запросу следующие:
• количество слов запроса в текстовом содержимом документа;
• тэги, в которых эти слова располагаются;
• местоположение искомых слов в документе;
• удельный вес искомых слов в общем количестве слов документа;
• время — как долго страница находится в базе поискового сервера;
• индекс цитируемости — как много ссылок на данную страницу идет с других страниц, зарегистрированных в базе поисковой машины.
Однако эффективность работы поисковых систем Интернет ограничивается четырьмя существенными факторами.
1. Топология Интернета такова, что поисковые машины могут просматривать не больше трети всех сайтов в Интернете.
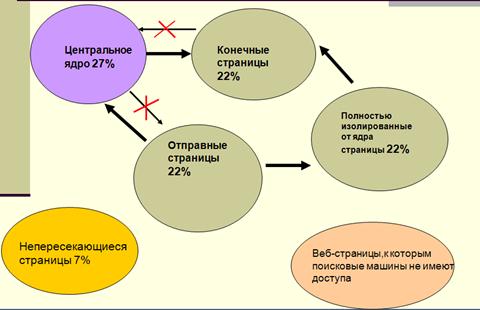
Просмотрев с помощью поисковых средств AltaVista свыше 600 млн. веб-страниц и 1,5 млн. ссылок, размещенных на этих страницах, специалисты пришли к выводу, что все исследуемое пространство состоит из следующих компонентов:
Центральное ядро (тесно связанные между собой веб-страницы) 27%
Отправные страницы (в них есть ссылки, ведущие к ядру, но с ядра попасть к отправным страницам нельзя) 22%
Конечные веб-страницы, к которым можно прийти по ссылкам из ядра, нок ядру попасть нельзя 22%
Полностью изолированные от ядра страницы, имеющие ссылки либо на конечные веб-страницы, либо ссылки с отправных страниц 22%
Веб-страницы, не пересекающиеся с остальными ресурсами Интернет 7%
К отдельным ресурсам Интернета поисковые машины не имеют доступа.
2. Глубина индексирования веб-сайтов. Большинство поисковых машин индексируют только определенное количество документов на одном веб-сайте.
3. "Невидимый Интернет" (скрытый). "Видимая" часть сайтов — это та часть, которая обрабатывается поисковыми системами и индексируется. "Невидимая" часть - это та часть сайта, которая не предназначена для обработки поисковыми системами. (Было разработано программное обеспечение по исследованию «невидимой» части сайтов. Полученные результаты показывают, что число документов «невидимой» части более чем в 500 раз превышают число документов, относящихся к «видимой».)
К невидимому Интернету в первую очередь относятся ресурсы, для доступа к которым требуется пароль или регистрация, профессиональные базы данных, а также различные форматы предоставления информации. Например, только с недавнего времени поисковые машины начали индексировать информацию в PDF-формате.
4. Индекс поисковых систем Интернета обновляется с периодичностью около недели. Отсюда видно, что в индекс поисковой системы не могут попасть материалы, например, периодических изданий, так как выходят они заведомо чаще, чем обновляется индекс.
Лидирующие позиции по количеству проиндексированных веб-страниц занимают поисковые машины Google, Yandex, Rambler.При работе с поисковыми машинами большое значение имеет язык запросов, так как единственным инструментом поиска становится полнотекстовый поиск по ключевым словам.
Критерии оценки поиска:
1) количество найденных документов;
2) найденные источники информации;
3) оперативность информации;
4) стоимость получения.
Целью ИПС является выдача документов, релевантных (семантически соответствующих) запросу (по-английски relevant - относящийся к делу). Различают релевантность содержательную и формальную. Релевантность содержательная трактуется как соответствие документа информационному запросу, определяемое неформальным путем (Василиса Премудрая сама прочитает письма всех добрых молодцев и выберет кандидатов в женихи, отвечающих ее требованиям), а релевантность формальная - как соответствие, определяемое алгоритмически путем сравнения поискового предписания и поискового образа документа на основании применяемого в информационно-поисковой системе критерия выдачи.
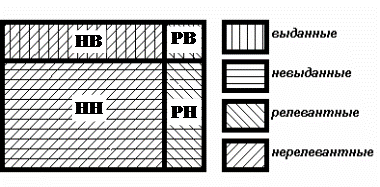
Массив документов разделяется на выданные и невыданные - по одному критерию, и на релевантные и нерелевантные - по другому
Из наиболее важных показателей эффективности поиска информационных систем, содержащих текстовую информацию, можно отметить семантические показатели, которые основаны на оценке релевантности между документами и запросами.
Релевантность — объективно существующее смысловое соответствие между содержанием документа и запроса. Объективность оценок релевантности обеспечивается тем, что они устанавливаются экспертным путем, а не автором запроса.
Введем следующие обозначения:
множество релевантных и выданных системой документов; РВ
множество нерелевантных, но выданных системой документов;НВ
множество релевантных, но не выданных системой документов;РН
множество нерелевантных и не выданных системой документов НН
 |
Семантическими показателями являются: полнота выдачи (потери информации) и точность выдачи (информационный шум).
полнота выдачи (ПВ) = РВ/(РВ+РН) *100%
точность выдачи (ТВ) = РВ/(РВ+НВ) *100%;
потери информации (ПИ) = РН/(РВ+РН) * 100%,
информационный шум (ИШ) = НВ/(РВ+НВ) *100%
В реальных системах коэффициент полноты достигает 70%, а коэффициент точности поиска колеблется в очень широких пределах, иногда снижаясь до 10%.
Величины этих коэффициентов зависят от целого ряда факторов: как внутренних свойств собственно поисковой системы (объема и характеристик информационного массива, информационно-поискового языка, критерия выдачи), так и от многих "внешних" условий: степени специфичности информационных запросов, способности пользователя правильно сформулировать свои информационные потребности на естественном языке, правильности построения конкретного запроса, а также от субъективного представления пользователя о том, что такое нужная ему информация. Из-за ошибок и неточностей, возникающих на каждом из этапов работы как пользователя, так и системы, результаты могут сильно отличаться от того, что хотел получить пользователь, обращаясь к ИПС.
|
|
|
|
|
Дата добавления: 2013-12-13; Просмотров: 4988; Нарушение авторских прав?; Мы поможем в написании вашей работы!