КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Метод Лемпеля–Зіва
|
|
|
|
Метод Хаффмена.
1. Повідомлення виписуються в порядку збільшення ймовірностей.
2. Два останніх повідомлення об'єднуються в одне допоміжне повідомлення, якому приписується сумарна ймовірність.
3. Ймовірності повідомлень знову розташовуються в порядку збільшення ймовірностей в додатковому стовпці, а дві останні об'єднуються.
4. Процес продовжується до тих пір, поки не отримаємо єдине повідомлення з імовірністю рівною одиниці.
Отриманий код є найекономічнішим з усіх методів кодування.
В основу методу покладена така ідея: якщо в тексті повідомлення з'являється послідовність з двох символів, які вже зустрічалися раніше, то ця послідовність називається новим символом і для неї призначається код, який може бути значно коротше вихідної послідовності. Надалі в стиснутому повідомленні замість вихідної послідовності записується призначений код. При декодуванні повторюються аналогічні дії і тому стають відомими послідовності символів для кожного коду.
Наприклад, якщо послідовність мала вигляд 1011010100010, то вона буде розбита на символи таким чином: 1, 0, 11, 01, 010, 00, 10.
Алгоритмічна реалізація цієї ідеї включає такі операції.
1. Спочатку кожному символу алфавіту присвоюється визначений код (коди – порядкові номери, починаючи з 0).
2. Вибирається перший символ повідомлення і заміняється на його код.
3. Вибираються наступні два символи і заміняються своїми кодами. Одночасно цієї комбінації двох символів присвоюється свій код. Найчастіше це номер, який дорівнює числу уже використаних кодів. Так, якщо алфавіт включає 8 символів, які мають коди від 000 до 111, те перша двосимвольна комбінація одержить код 1000, наступна - код 1001 і т.д.
4. Вибираються з вихідного тексту чергові 2, 3,..., N символів доти, поки не утвориться комбінація, яка ще не зустрічалася. Тоді цієї комбінації присвоюється черговий код, і оскільки сукупність А з перших N –1 символів уже зустрічалася, товона має свій код, який і записується замість цих N –1 символів. Кожний акт введення нового коду називається крокомкодування.
5. Процес продовжується до вичерпання початкового тексту.
Приклад. Нехай початковий текст являє собою двійковий код (перший рядок таблиці 1), тобто символами алфавіту є 0 і 1. Коди цих символів відповідно також 0 і 1. Код, який утворюється за методом Лемпеля–Зіва (LZ–код), показаний у другому рядку таблиці. У третьому рядку відзначені кроки кодування, після яких відбувається перехід на подання кодів збільшеним числом розрядів r. Так, на першому кроці вводиться код 10 для комбінації 00 і тому на наступних двох кроках R = 2, після третього кроку R = 3, після сьомого кроку R = 4, тобто в загальному випадку R = К послу кроку 2 K– 1 –1.
Таблиця 1
| Початковий текст | 0.00.000.01.11.111.1111.110.0000.00000.1101.1110. |
| LZ–код | 0.00.100.001.0011.011.1101.1.1010.00110.10010. 10001.10110. |
| R | 2 3 4 |
Розглянутий приклад дає фактично не стиск, а "розтягнення" пові–домлень, оскільки замість 37 біт на вході ми одержуємо 48 біт. У наведеному прикладі LZ–код має більшу довжину, ніж кінцевий код, оскільки короткі тексти не дають ефекту стиску. Для довгих послідовностей повідомлень ефективність алгоритму збільшується, і при n →∞, стиск повідомлень наближається до гранично можливого, обумовленого теоремою кодування в каналі без завад, а саме доводиться, що для будь–якого стаціонарного ергодичного джерела повідомлень
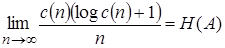 ,
,
де c (n) – число різних ланцюжків розбиття початкової послідовності довжиною n.
Ефект стиску виявляється в досить довгих текстах і особливо помітний у графічних файлах. Помітимо, що фактично для стиску файлів використовується модифікований алгоритм, який називається алгоритмом стиску Зіва–Лемпела–Велча. На основі цього алгоритму побудовані найбільш ефективні програми архівіровання файлів, такі як PKARC, PKZIP, ICE тощо.
|
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 791; Нарушение авторских прав?; Мы поможем в написании вашей работы!