КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Кодовые деревья
|
|
|
|
Рассмотрим реализацию алгоритма Хаффмана с использованием кодовых деревьев.
Кодовое дерево (дерево кодирования Хаффмана, Н-дерево) – это бинарное дерево, у которого:
· листья помечены символами, для которых разрабатывается кодировка;
· узлы (в том числе корень) помечены суммой вероятностей появления всех символов, соответствующих листьям поддерева, корнем которого является соответствующий узел.
Метод Хаффмана на входе получает таблицу частот встречаемости символов в исходном тексте. Далее на основании этой таблицы строится дерево кодирования Хаффмана.
Алгоритм построения дерева Хаффмана.
Шаг 1. Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемый текст.
Шаг 2. Выбираются два свободных узла дерева с наименьшими весами.
Шаг 3. Создается их родитель с весом, равным их суммарному весу.
Шаг 4. Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка.
Шаг 5. Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой – бит 0.
Шаг 6. Повторяем шаги, начиная со второго, до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Существует два подхода к построению кодового дерева: от корня к листьям и от листьев к корню.
Пример построения кодового дерева. Пусть задана исходная последовательность символов:
aabbbbbbbbccсcdeeeee.
Ее исходный объем равен 20 байт (160 бит). В соответствии с приведенными на рисунке 1 данными (таблица вероятности появления символов, кодовое дерево и таблица оптимальных префиксных кодов) закодированная исходная последовательность символов будет выглядеть следующим образом:
110111010000000011111111111111001010101010.
Следовательно, ее объем будет равен 42 бита. Коэффициент сжатия приближенно равен 3,8.
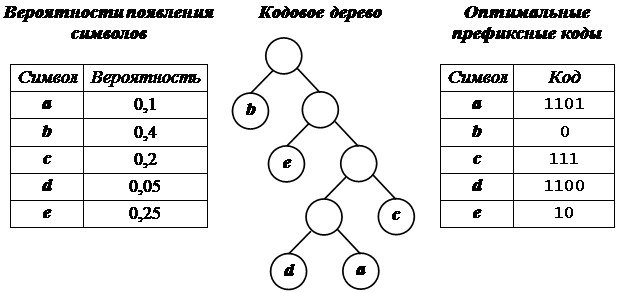 |
Рис.1. Создание оптимальных префиксных кодов
Классический алгоритм Хаффмана имеет один существенный недостаток. Для восстановления содержимого сжатого текста при декодировании необходимо знать таблицу частот, которую использовали при кодировании. Следовательно, длина сжатого текста увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию данных. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по тексту: одного для построения модели текста (таблицы частот и дерева Хаффмана), другого для собственно кодирования.
Пример 2. Программная реализация алгоритма Хаффмана с помощью кодового дерева.
#include "stdafx.h"
#include <iostream>
using namespace std;
struct sym {
unsigned char ch;
float freq;
char code[255];
sym *left;
sym *right;
};
void Statistics(char *String);
sym *makeTree(sym *psym[],int k);
void makeCodes(sym *root);
void CodeHuffman(char *String,char *BinaryCode, sym *root);
void DecodeHuffman(char *BinaryCode,char *ReducedString,
sym *root);
int chh;//переменная для подсчета информация из строки
int k=0;
//счётчик количества различных букв, уникальных символов
int kk=0;//счетчик количества всех знаков в файле
int kolvo[256]={0};
//инициализируем массив количества уникальных символов
sym simbols[256]={0};//инициализируем массив записей
sym *psym[256];//инициализируем массив указателей на записи
float summir=0;//сумма частот встречаемости
int _tmain(int argc, _TCHAR* argv[]){
char *String = new char[1000];
char *BinaryCode = new char[1000];
char *ReducedString = new char[1000];
String[0] = BinaryCode[0] = ReducedString[0] = 0;
cout << "Введите строку для кодирования: ";
cin >> String;
sym *symbols = new sym[k];
//создание динамического массива структур simbols
sym **psum = new sym*[k];
//создание динамического массива указателей на simbols
Statistics(String);
sym *root = makeTree(psym,k);
//вызов функции создания дерева Хаффмана
makeCodes(root);//вызов функции получения кода
CodeHuffman(String,BinaryCode,root);
cout << "Закодированная строка: " << endl;
cout << BinaryCode << endl;
DecodeHuffman(BinaryCode,ReducedString, root);
cout << "Раскодированная строка: " << endl;
cout << ReducedString << endl;
delete psum;
delete String;
delete BinaryCode;
delete ReducedString;
system("pause");
return 0;
}
//рeкурсивная функция создания дерева Хаффмана
sym *makeTree(sym *psym[],int k) {
int i, j;
sym *temp;
temp = new sym;
temp->freq = psym[k-1]->freq+psym[k-2]->freq;
temp->code[0] = 0;
temp->left = psym[k-1];
temp->right = psym[k-2];
if (k == 2)
return temp;
else {
//внесение в нужное место массива элемента дерева Хаффмана
for (i = 0; i < k; i++)
if (temp->freq > psym[i]->freq) {
for(j = k - 1; j > i; j--)
psym[j] = psym[j-1];
psym[i] = temp;
break;
}
}
return makeTree(psym,k-1);
}
//рекурсивная функция кодирования дерева
void makeCodes(sym *root) {
if (root->left) {
strcpy(root->left->code,root->code);
strcat(root->left->code,"0");
makeCodes(root->left);
}
if (root->right) {
strcpy(root->right->code,root->code);
strcat(root->right->code,"1");
makeCodes(root->right);
}
}
/*функция подсчета количества каждого символа и его вероятности*/
void Statistics(char *String){
int i, j;
//побайтно считываем строку и составляем таблицу встречаемости
for (i = 0; i < strlen(String); i++){
chh = String[i];
for (j = 0; j < 256; j++){
if (chh==simbols[j].ch) {
kolvo[j]++;
kk++;
break;
}
if (simbols[j].ch==0){
simbols[j].ch=(unsigned char)chh;
kolvo[j]=1;
k++; kk++;
break;
}
}
}
// расчет частоты встречаемости
for (i = 0; i < k; i++)
simbols[i].freq = (float)kolvo[i] / kk;
// в массив указателей заносим адреса записей
for (i = 0; i < k; i++)
psym[i] = &simbols[i];
//сортировка по убыванию
sym tempp;
for (i = 1; i < k; i++)
for (j = 0; j < k - 1; j++)
if (simbols[j].freq < simbols[j+1].freq){
tempp = simbols[j];
simbols[j] = simbols[j+1];
simbols[j+1] = tempp;
}
for(i=0;i<k;i++) {
summir+=simbols[i].freq;
printf("Ch= %d\tFreq= %f\tPPP= %c\t\n",simbols[i].ch,
simbols[i].freq,psym[i]->ch,i);
}
printf("\n Slova = %d\tSummir=%f\n",kk,summir);
}
//функция кодирования строки
void CodeHuffman(char *String,char *BinaryCode, sym *root){
for (int i = 0; i < strlen(String); i++){
chh = String[i];
for (int j = 0; j < k; j++)
if (chh == simbols[j].ch){
strcat(BinaryCode,simbols[j].code);
}
}
}
//функция декодирования строки
void DecodeHuffman(char *BinaryCode,char *ReducedString,
sym *root){
sym *Current;// указатель в дереве
char CurrentBit;// значение текущего бита кода
int BitNumber;
int CurrentSimbol;// индекс распаковываемого символа
bool FlagOfEnd; // флаг конца битовой последовательности
FlagOfEnd = false;
CurrentSimbol = 0;
BitNumber = 0;
Current = root;
//пока не закончилась битовая последовательность
while (BitNumber!= strlen(BinaryCode)) {
//пока не пришли в лист дерева
while (Current->left!= NULL && Current->right!= NULL &&
BitNumber!= strlen(BinaryCode)) {
//читаем значение очередного бита
CurrentBit = BinaryCode[BitNumber++];
//бит – 0, то идем налево, бит – 1, то направо
if (CurrentBit == '0')
Current = Current->left;
else
Current = Current->right;
}
//пришли в лист и формируем очередной символ
ReducedString[CurrentSimbol++] = Current->ch;
Current = root;
}
ReducedString[CurrentSimbol] = 0;
}
Для осуществления декодирования необходимо иметь кодовое дерево, которое приходится хранить вместе со сжатыми данными. Это приводит к некоторому незначительному увеличению объема сжатых данных. Используются самые различные форматы, в которых хранят это дерево. Обратим внимание на то, что узлы кодового дерева являются пустыми. Иногда хранят не само дерево, а исходные данные для его формирования, то есть сведения о вероятностях появления символов или их количествах. При этом процесс декодирования предваряется построением нового кодового дерева, которое будет таким же, как и при кодировании.
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 2783; Нарушение авторских прав?; Мы поможем в написании вашей работы!