КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Характеристики. 2. Більш складні структури даних
Масив
Купа
Дерево
Граф
Масив
1.2 Лінійний список.
А) Стек.
Б) Черга
В) Зв’язаний список
2. Більш складні структури даних
А) Бінарне дерево:
Б) Бінарне дерево пошуку:
А) Бінарна купа
Б) Біноменальна купа
В програмуванні та комп'ютерних науках структури даних -- це способи організації даних в комп'ютерах. Часто разом зі структурою даних пов'язується і специфічний перелік операцій, які можуть бути виконаними над даними, організованими в таку структуру.
Правильний підбір структур даних є надзвичайно важливим для ефективного функціонування відповідних алгоритмів їх обробки. Добре побудовані структури даних дозволяють оптимізувати використання машинного часу та пам'яті комп'ютера для виконання найбільш критичних операцій.
Відома формула "Програма = Алгоритми + Структури даних" дуже точно виражає необхідність відповідального ставлення до такого підбору. Тому іноді навіть не обраний алгоритм для обробки масиву даних визначає вибір тої чи іншої структури даних для їх збереження, а навпаки.
Підтримка базових структури даних, які використовуються в програмуванні, включена в комплекти стандартних бібліотек найбільш розповсюджених мов програмування, такиї як Standart Template Library для C++, Java API, Microsoft.NET.
1. Елементарні структури даних
В програмуванні масив (англ. array) — одна з найпростіших структур даних, сукупність елементів переважно одного типу даних, впорядкованих за індексами, які зазвичай репрезентовані натуральними числами, що визначають положення елемента в масиві.
Масив може бути одновимірним (вектором), та багатовимірним (наприклад, двовимірною таблицею), тобто таким, де індексом є не одне число, а кортеж (сукупність) з декількох чисел, кількість яких співпадає з розмірністю масива.
В переважній більшості мов програмування масив є стандартною вбудованою структурою даних.
Переваги та недоліки
Ефективність операцій
Масиви ефективні при звертанні до довільного елементу, яке відбувається за постійний час (O(1)), однак такі операції як додавання та видалення елементу, потребують часу O(n), де n — розмір масиву. Тому масиви переважно використовуються для зберігання даних, до елементів яких відбувається довільний доступ без додавання або видалення нових елементів, тоді як для алгоритмів с інтенсивними операціями додавання та видалення, ефективнішими є зв'язані списки.
Збереження в пам'яті
Інша перевага масивів, яка є досить важливою — це можливість компактного збереження послідовності їх елементів в локальній області пам'яті (що не завжди вдається, наприклад, для зв'язаних списків), що дозволяє ефективно виконувати операції з послідовного обходу елементів таких масивів.
Масиви є дуже економною щодо пам'яті структурою даних. Для збереження 100 цілих чисел в масиві необхідно рівно в 100 разів більше пам'яті, ніж для збереження одного числа (плюс, можливо, ще декілька байтів). В той же час, усі структури даних, які базуються на вказівниках, потребують додаткової пам'яті для збереження самих вказівників разом з даними. Однак, операції з фіксованими масивами ускладнюються тоді, коли виникає необхідність додавання нових елементів у вже заповнений масив. Тоді його необхідно розширювати, що не завжди можливо і для таких задач слід використовувати зв'язані списки, або динамічні масиви.
Індекси в масивах
У випадках, коли розмір масиву є досить великий та використання звичайного звертання за індексом стає проблематичним, або великий відсоток його комірок не використовується, слід звертатись до асоціативних масивів, де проблема індексування великих об'ємів інформації вирішується більш оптимально.
З тої причини, що масиви мають фіксовану довжину, слід дуже обережно ставитись до процедури звертання до елементів за їхнім індексом, тому що намагання звернутись до елементу, індекс якого перевищує розмір такого масива (наприклад, до елементу з індексом 6 в масиві з 5 елементів), може призвести до непередбачуваних наслідків.
Слід також бути уважним щодо принципів нумерації елементів масиву, яка в одних мовах програмування може починатись з 0, а в інших — з 1.
Зберігання багатовимірних масивів
Збереження одновимірного масиву в пам'яті є тривіальним, тому що сама пам'ять комп'ютера є одновимірним масивом. Для збереження багатовимірного масиву ситуація ускладнюється. Припустимо, що ми хочемо зберігати двовимірний масив наступного виду:
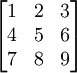
Найпоширеніші способи його організації в пам'яті такі:
· Розташування «рядок за рядком». Це найбільш уживаний на сьогодні спосіб, який зустрічається у більшості мов програмування.
· Розташування «стовпчик за стовпчиком». Такий метод розташування масивів використовується, зокрема, в мові програмування Fortran
· Масив з масивів. Багатовимірні масиви репрезентуються одновимірними масивами вказівників на одновимірні масиви. Розташування може бути як «рядок за рядком» так і «стовпчик за стовпчиком».
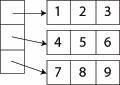
Перші два способи дозволяють розміщувати дані компактніше (мають більшу локальність), однак це одночасно і обмеження: такі масиви мають бути «прямокутними», тобто кожний рядок повинен містити однакову кількість елементів. Розташування «масив з масивів», з іншого боку, не дуже ефективне щодо використання пам'яті (необхідно зберігати додатково інформацію про вказівники), але знімає обмеження на «прямокутність» масиву.
1.2 Лінійний список.
Лінійний список в інформатиці та програмуванні визначається як екземпляр абстрактного типу даних, що формалізує концепцію впорядкованої множини елементів. Наприклад, абстрактний тип даних для безтипових, змінних списків можна визначити із допомогою конструктора та чотирьох операцій:
· конструктор для створення порожнього списка;
· операція визначення порожності списка;
· операція для додавання елемента в початок списка (cons в Лісп);
· операція отримання першого елемента списка (або «голови») списка (car в Лісп);
· операція для визначення списка, що складається із всіх елементів списка окрім першого (або його «хвоста») (cdr в Лісп).
За визначенням, список — це послідовність з n≥0 елементів X[1],X[2], … X[n], для якої виконується наступна умова: якщо n>0 та X[1] — перший елемент у списку, а X[n] — останній, то k-й елемент розташований між X[k-1] та X[k+1] елементами для усіх 1<k<n.
З такими структурами даних виконуються наступні операції:
· отримання k-го елемента списку для читання чи запису в нього нового значення;
· додавання нового елемента в будь-яку позицію в списку;
· видалення елемента списку;
· об'єднання в одному списку двох або більше лінійних списків;
· розбиття списку на два або більше фрагментів;
· створення копії списку;
· визначення кількості елементів в списку;
· сортування елементів списку;
· пошук елемента, що задовільняє певним критеріям.
Важливими окремими випадками лінійних списків, в яких операції додавання та вилучення певних значень можуть бути виконані лише для першого чи останнього елементу, є:
стек
лінійний список, в якому операції додавання та вилучення виконуються лише на одному кінці списку (верхівці стеку). Принцип побудови стеку називають LIFO
(англ. last in, last out).
черга (однобічна черга)
лінійний список, в якому усі операції додавання виконується на одному кінці (в голові черги), а операції вилучення — на іншому кінці списку (в хвості черги). Принцип побудови черги називають FIFO (англ. first in, first out).
дек або двобічна черга (англ. double-ended queue, deq)
лінійний список, в якому всі операції вставки та видалення виконуються на обох кінцях списку.
Не менш важливим окремим випадком лінійного списку є зв'язаний список, в якому кожний елемент окрім поля даних зберігає також вказівник на наступний. Така структура дозволяє зняти обмеження на зберігання лінійного списку в безперервній області пам'яті.
Важливим узагальненням лінійного списку є багатовимірний масив.
А) Стек.
СТЕК в інформатиці та програмуванні -- різновид лінійного списку, структура даних, яка працює за принципом (дисципліною) "останнім прийшов -- першим пішов" (LIFO, last in, first out). Всі операції (наприклад, видалення елементу) в стеку можна проводити тільки з одним елементом, який знаходиться на верхівці стеку та був введений в стек останнім.
Стек можна розглядати як певну аналогію до стопки тарілок, з якої можна взяти верхню, і на яку можна покласти верхню тарілку (інша назва стеку -- "магазин", за аналогією з принципом роботи магазину в автоматичній зброї)
Операції зі стеком
push ("заштовхнути елемент"): елемент додається в стек та розміщується в його верхівці. Розмір стеку збільшується на одиницю. При перевищенні розміру стека граничної величини, відбувається переповнення стека (stack overflow)
pop ("виштовхнути елемент"): отримує елемент з верхівки стеку. При цьому він видаляється зі стеку і його місце в верхівці стеку займає наступний за ним відповідно до правила LIFO, а розмір стеку зменшується на одиницю. При намаганні "виштовхнути" елемент з вже пустого стеку, відбувається ситуація "незаповнення" стеку (stack underflow)
Кожна з цих операцій зі стеком виконується за фіксований час O(1) і не залежить від розміру стеку.
Додаткові операції (присутні не у всіх реалізаціях стеку):
isEmpty: перевірка наявності елементів в стеку; результат: істина (true), коли в стеку немає елементів.
isFull: перевірка заповненості стека. Результат: істина, коли додавання нового елементу неможливе
clear: звільнити стек (видалити усі елементи).
top: отримати верхній елемент (без виштовхування).
size: отримати розмір (кількість елементів) стека.
swap: поміняти два верхніх елементи місцями.
Організація в пам'яті комп'ютера
Стек може бути організований як масив або множина комірок в певній області комп'ютера з додатковим зберіганням ще й вказівника на верхівку стека. Заштовхування першого елемента в стек збільшує адресу вказівника, виштовхування елементу зменшує її. Таким чином, адреса вказівника завжди відповідає комірці масиву, в якій зараз знаходиться верхівка стеку.
Багато процесорів ЕОМ мають спеціалізовані регістри, які використовуються як вказівники на верхівку стеку, або використовують деякі з регістрів загального вжитку для цієї спеціальної функції в певних режимах адресації пам'яті.
|
|
Дата добавления: 2014-01-05; Просмотров: 576; Нарушение авторских прав?; Мы поможем в написании вашей работы!