КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Мова SDL
|
|
|
|
Комп'ютерна інженерія
Автоматизація програмування
Створення імітаційних моделей — складне завдання. Недарма у своїй праці Шеннон [67] ставить програмістів, які створюють програмні реалізації імітаційних моделей, вище, ніж системних програмістів. Перші мислять просторово — часовими образами. Для спрощення процесу створення імітаційних моделей розробляються засоби автоматизації, які дають змогу не тільки вилучити проміжну ланку між аналітиком і людиною, що приймає рішення, а й під час створення моделі використовувати терміни предметної галузі, в якій працює аналітик.
У 1968 році на одній з конференцій НАТО з проблем розроблення програмного забезпечення було вжито термін «Software Engineering», який перекладається як комп'ютерна інженерія. Так було названо нову наукову дисципліну, об'єктом дослідження якої є великі комп'ютерні системи і проблеми, що виникають під час їх створення.
У наш час продовжують розвиватись різні методи розробки складного програмного забезпечення. У рамках комп'ютерної інженерії робиться спроба визначити абстрактну систему понять цього процесу. Кожний новий підхід передбачає свою систему, яка схожа на інші, але має деякі нюанси.
У цьому розділі розглядаються відомі об'єктно-орієнтовані методи автоматизації створення програмних систем і розкриваються поняття, які використовуються під час розроблення засобів автоматизації проектування імітаційних моделей.
Застосовувана в моделюванні мова SDL (Specification and Description Language) — це мова специфікацій та опису. Під специфікацією розуміють точне формальне визначення системи або її частини, під описом — неформальну специфікацію, яка ілюструє той або інший аспект системи. Описи використовують на початкових етапах розробки системи або для документування системи. На етапах детального проектування використовують специфікації, за якими передбачається виконання автоматичного генерування програмного коду. Той факт, що для різних етапів розробки системи пропонується одна мова, є суттєвою перевагою SDL, оскільки в такому випадку зникає проблема семантичних розривів.
Мову SDL призначено для розробки подійно-орієнтованих розподілених систем. Ця мова почала розвиватись за сприяння міжнародного комітету ITU ще в 1976 році і є однією з найдавніших розробок в комп'ютерній інженерії. Існує два варіанти цієї мови — текстовий (SDL/PR) та графічний (SDL/GR), синтаксис яких здебільшого співпадає. Викладення основ цієї мови можна знайти в літературі [93]. Крім того, є російський варіант стислого викладення мов SDL і MSC (Message Sequence Chart) [17].
Більше десяти компаній в Європі (Telelogic, Verigol та ін.) розробляють CASE- засоби (Computer-Aided Software Engineering — автоматизоване проектування і створення програм) на основі SDL. Ці продукти використовуються багатьма великими європейськими компаніями — виробниками телекомунікаційних систем.
Крім мови SDL комітетом ITU запропоновано цілу низку стандартів на засоби розробки телекомунікаційних систем. Серед них мови високого рівня CHILL, MSC [35] (графічна мова сценаріїв). У Європі щороку проходить велика кількість конференцій, на яких обговорюються різні аспекти цих стандартів.
Мова SDL як засіб аналізу систем широко використовується в європейських телекомунікаційних стандартах. Її основними складовими є структурна модель і розширений скінченний автомат. Вони орієнтовані на здійснення специфікації подійно-орієнтованих систем, хоча мають ширше використання.
Блочний аналіз є основою структурної декомпозиції системи за допомогою мови SDL. Він передбачає зображення системи у вигляді вкладених одна в одну частин (блоків), які не містять виконуваного коду, а містять лише описи. Блоки можуть відповідати великим модулям системи або підзавданням проекту. Виконуваний код у вигляді розширеного скінченного автомату міститься лише в листках дерева цієї декомпозиції, тобто процесах, які, подібно до блоків, можна поставити у відповідність об'єктам. Тому мову SDL було успішно розширено до об'єктно-орієнтованої мови.
Існують графічні нотації, що призначені для використання на початкових етапах розробки системи, а також процес розробки програмного забезпечення на основі мови SDL. Але на сьогоднішній день ці нотації замінено мовою UML, яка потіснила також SDL. У праці [36] визнано, що SDL є мовою програмування, подібною до Java, С++ та ін. Отже, виникає проблема співіснування UML-описів і SDL-специфікацій.
5.8.3. Метод OOSE
об 'єктно-орієнтований програмний інжиніринг — OOSE (Object-Oriented Software Engineering) описано у монографії [77], яка є однією з фундаментальних праць у галузі досліджень об'єктно-орієнтованих методів розробки програмного забезпечення. Основне завдання цього підходу — наблизити комп'ютерну інженерію до типового промислового процесу, яким є, наприклад, будівництво. Основний принцип підходу — об'єктна орієнтованість, як аналізу, проектування, програмування, так і опису процесу розробки програмного забезпечення загалом.
Підхід призначено, у першу чергу, для розроблення великих систем. На рис. 5.5 зображено рівні технології комп'ютерної інженерії згідно з OOSE. На основі OOSE створено метод Objectory, реалізований у продукті компанії Objectory АВ. У 1995 році, після злиття цієї компанії з корпорацією Rational Software Corp., цей метод використовувався під час створення раціонального об'єднаного підходу — RUP (Rational Unified Approach).
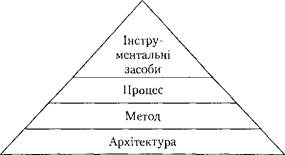
Рис. 5.5. Структура комп'ютерної інженерії
В OOSE пропонується компактний опис структури комп'ютерної інженерії, основою якої є поняття архітектури. Це поняття включає основні концепції і технології, визначені як об'єктно-орієнтовані, певний набір напівформальних моделей з графічними нотаціями, які надаються для опису розроблюваної системи.
Метод OOSE — лінійна послідовність кроків, тобто процедура для створення ідеальної системи «з нуля». За допомогою цього методу можна визначити, як застосовувати архітектуру для розроблення системи.
Процес розробки є розширенням методу. На відміну від методу він, по-перше, орієнтований на ітеративне розроблення програмного забезпечення (сам метод лінійний) і по-друге — адаптований до практичного застосування (метод — це ідеальна послідовність кроків).
І нарешті, інструментальні засоби — це реалізація архітектури, методу та процесу в конкретному програмному продукті — CASE-засобі, за допомогою якого відбувається розроблення системи.
Аналіз і проектування в OOSE засновані на методі випадків використання (use case approach), за допомогою яких, через побудовані для них сценарії, виділяються об'єкти. Пропонується кілька об'єктних моделей для різних стадій розробки системи і, як у SDL, блочний аналіз.
5.8.4. Метод Буча
Праця Буча [74] є класичною монографією, де висвітлюється об'єктно-орієнтований підхід до аналізу та проектування програмного забезпечення. За допомогою методу описуються об'єктна модель і візуальні засоби, а також сам процес розробки програмного забезпечення з визначенням цілей, видів діяльності та передбачуваних результатів. Крім того, розглядаються організаційні питання створення програмного забезпечення та вплив на них застосування об'єктно-орієнтованого підходу. Метод засновано на єдиній моделі класів. Її пропонується використовувати на різних етапах розробки отримання єдиної специфікації системи, яка змінюється від однієї фази розробки до іншої.
Як основні поняття у праці [74] використовуються методологія і метод.
«Методологія — це набір методів, які застосовуються протягом всього життєвого циклу створення програмного забезпечення, поєднаних єдиною філософською концепцією». Такою концепцією в Буча є об'єктно-орієнтований погляд на світ.
«Метод — це чітко визначений процес створення набору моделей за допомогою специфікованих нотацій; ці моделі описують різні аспекти програмного забезпечення». Буч називає свій підхід методом і ділить його на три частини - нотації, процес, прагматика.
Основа методу — можливість розглядати розроблювану систему з різних поглядів. Результат такого розгляду називається моделлю системи. Буч вирізняє такі типи моделей: логічну, фізичну, статичну та динамічну. Під моделлю розуміється як спосіб бачення, так і його результати. У першому випадку використовується також термін view, у перекладі з англійської - вид.
Нотація — це графічна мова для опису моделей. Ця частина методу є формальною.
Процес - це опис цілей, видів діяльності та результатів для різних фаз об'єктно-орієнтованого аналізу та проектування. Процес не формалізується як набір процедур, а поділяється на частини, для яких описуються інтерфейсні характеристики. Буч підкреслює, що його опис процесу не є набором готових рецептів.
Прагматика в контексті методу Буча — це та специфіка об'єктно-орієнтованого підходу, яка виявляється в організаційних питаннях створення програмного забезпечення: керування проектом, персоналом, ризиками, версіями системи, конкретні програмні засоби підтримки розробки програмного забезпечення та ін. Важливість цих питань зумовлена тим, що проектування та аналіз не є строгою та формально визначеною наукою, для розв'язання значної частини проблем не вдається знайти відповідних формалізацій, і залишається лише обговорити їх на неформальному рівні. Таким чином, ця частина методу є найбільш неформальною.
5.8.5. Мова UML
У класичних працях, присвячених проблемі створення великих програмних систем на основі об'єктно-орієнтованого підходу [74, 77], автори намагалися охопити всі боки життєвого циклу розробки програмного забезпечення, не залишаючи без уваги жодного організаційного питання. Але найбільше практичне втілення мали ті частини цих праць, в яких йдеться про візуальне моделювання як один з основних засобів аналізу та проектування великих програмних систем. Було створено велику кількість спеціалізованих програмних продуктів під загальною назвою CASE- засоби, які реалізують графічні нотації різних об'єктно-орієнтованих методологій. Нарешті, хаосу в цій галузі позбулися завдяки прийняттю стандарту щодо об'єктно-орієнтованих засобів візуальної специфікації - мови UML (Unified Modeling Language). Якщо слідувати структурі методу Буча, то можна сказати, що стандартизовано лише нотацію, а процес і прагматика в UML не увійшли, тобто було стандартизовано мову, а не способи її застосування.
Мова UML розвивається з 1994 року і є результатом злиття трьох найбільш відомих об'єктно-орієнтованих підходів: методу Буча [74], ОМТ [85] і OOSE [77]. У 1997 році мову UML було прийнято комітетом OMG як стандарт. Вона практично замінила собою всі інші об'єктно-орієнтовані підходи. Мова UML є грандіозною спробою розробити на основі об'єктно-орієнтованого підходу універсальну мову графічного моделювання для аналізу і проектування складних комп'ютерних систем. Вона об'єднує велику кількість різних графічних нотацій з метою впорядкування хаотичного набору графічних засобів, які використовуються під час створення програмного забезпечення. Стандартизація тут суттєво підвищує рівень розуміння між різними фахівцями, які розроблюють складну систему. Крім того, стандарт полегшує процес перенесення специфікацій, виконаних у різних CASE-пакетах.
В основному документі щодо мови UML [97] описано версію UML 1.1 1997 року. Ця праця ґрунтується на настанові з UML [84].
Нижче коротко розглядаються поняття UML, на яких засновано засоби структурної декомпозиції проекту та розроблюваної системи.
Пакет — це простір імен проекту, який складається з множини сутностей, виражених за допомогою понять і діаграм UML. Пакети можуть включати в себе інші пакети.
Модель — це тип пакету, який є певним закінченим образом системи, що описує її з певного погляду. Наприклад, для розроблюваної системи можна побудувати модель випадків використання, яка буде визначати функціональні вимоги до неї.
Погляд — це певний спосіб бачення системи, з огляду на який будується певна модель системи. Погляд включає в себе набір графічних нотацій та їх семантику. Виділяються такі погляди на систему: статичний, випадків використання, взаємодії, скінченно-автоматний, активностей, фізичний, керований.
Підсистема - це вид пакету, який описує певну частину системи, виділену в єдине ціле за реалізаційними або функціональними міркуваннями. Структура підсистеми ділиться на дві частини - декларативну та реалізаційну. Перша визначає зовнішню поведінку підсистеми і може включати в себе випадки використання, інтерфейси та ін. Реалізаційна частина описує, яким чином реалізується декларативна частина.
Підсистема аналогічна блоку SDL, але загалом система понять UML є більш загальною, ніж у SDL.
5.8.6. Методологія ROOM
Методологія ROOM (Real-Time Object-Oriented Modeling) - це об'єктно-орієнтована розробка систем реального часу. Її розвиток пов'язаний з канадською компанією Object Time Limited, яка на основі цієї методології випустила програмний продукт ObjectTime. Методологію було розроблено в 1992 році [98]. У 1994 році вийшла монографія [88], яка містить повний опис ROOM. Модель поведінки ROOM розглянуто в працях [94, 99]. Крім того, продовжує видаватись велика кількість статей, в яких описано різні аспекти використання цієї технології та подальший розвиток. Заслуговують на увагу праці [94, 99], в яких описано, як ROOM «вкладається» в UML за допомогою механізму розширень UML. Матеріал, викладений у цих працях є базисом для створення мостів між програмними продуктами, які реалізують ROOM і UML.
У методології ROOM передбачено два рівні подання розроблюваної системи:
рівень схем;
рівень деталізації.
Виділення цих рівнів спрямоване на автоматичну кодогенерацію. Таким чином, ця методологія суттєво відрізняється від UML, де пропонуються лише погляди на систему (view), застосування яких не зовсім зрозуміле. Для рівня схем методологія ROOM пропонує набір графічних нотацій. Рівень деталізації передбачає використання мови реалізації, оскільки очевидно, що всю систему, якщо вона достатньо складна, неможливо задати специфікацією у вигляді картинок, за якими можна автоматично згенерувати працюючу програму.
Рівень схем складається з графічних нотацій, що дозволяють зобразити структуру системи (класів і об'єктів) та опис моделі її поведінки.
5.8.7. Метод RUP
Мова UML є лише мовою моделювання і способи застосування винесені з її специфікації. Корпорацією IBM Rational Corp. створено надбудову над UML під назвою RUP (Rational Unified Process) [10], яка дає змогу систематизувати процес створення програмного забезпечення на основі UML, пропонуючи використовувати певний набір програмних продуктів (головним чином, компанії Rational Corp.).
Одним із основних понять методу RUP є фаза. Фаза — це етап розробки системи. З нею, як звичайно, пов'язана проміжна або кінцева звітність до проекту. За методом RUP вирізняється така множина фаз.
Початок — фаза визначення меж проекту, оцінювання реальності його виконання (терміни, плани, кошти, люди, ризики).
Деталізація — фаза створення архітектурного прототипу системи, визначення вимоги до проекту, його вартості і терміну виконання, складання детального плану роботи.
Конструювання — фаза реалізації проекту.
Передавання — фаза передавання системи замовнику.
Цикл розроблення системи завершується після виконання останньої фази, у результаті чого з'являється нова версія системи. Після цього розроблення продовжується вже на новому рівні внаслідок висування нових вимог до системи і завершується випуском чергової версії системи.
Метод RUP передбачає інтерактивність усередині однієї фази. Як звичайно, результатом ітерації є прототип системи. Наводяться такі варіанти кількості ітерацій за фазами: [0,1,1,1], [1,2,2,1], [1,3,3,2]. Таким чином, формулюється загальне правило про кількість ітерацій усередині одного циклу: 6 ± 3.
Поняття фази є вдалою абстракцією для виділення етапів розробки системи. Це поняття узгоджує ітеративний процес розробки програмного забезпечення та лінійний порядок звітності.
Розроблення системи виконується в чотири фази за допомогою робочих процесів (workflow), які є послідовністю дій, пов'язаних загальною специфікою. Робочі процеси розподіляються за різними фазами і можуть протікати паралельно. Метод RUP передбачає виконання таких робочих процесів.
Бізнес-моделювання (Business Modeling).
Висування вимог (Requirements).
Аналіз і проектування (Analysis and Design).
Реалізація (Implementation).
Тестування (Testing).
Впровадження системи (Deployment).
Крім того вирізняють такі допоміжні процеси.
керування проектом (Project Management);
створеня конфігурації змін та керування ними (Configuration and Change Management);
створення конфігурації середовища (Environment).
З наведеного вище огляду засобів CASE-технологій зрозуміло, що всі вони тією або іншою мірою можуть запроваджуватись під час розроблення складних імітаційних систем. Проте існує проблема, яку складно вирішувати за допомогою цих технологій — керування процесом моделювання в модельному часі. Спробою поєднати CASE-технології та імітаційне моделювання є розробка стандарту HLA (High Level Architecture).
5.8.8. Програмні генератори імітаційних моделей
З метою спрощення процесу створення імітаційних моделей останнім часом розробляються діалогові або інтерактивні системи моделювання, які за допомогою інтерфейсу транслюють висловлення на природній мові у програмні реалізації імітаційних моделей. Перші спроби побудови таких систем робились з використанням мови Simula, але засоби автоматичного програмування не були створені через складність реальних модельованих систем. Найбільшого успіху досягнуто під час розробки спеціалізованих систем моделювання для вузьких галузей.
Не зважаючи на те, що засоби генерування моделей орієнтовані на конкретні предметні галузі, бажано, щоб вони не враховували будь-які специфічні особливості певної галузі. Цього можна досягти завдяки уніфікації опису імітаційних моделей, який повинен базуватись на єдиній математичній основі для всіх форм зображення модельованого об'єкта: змістовного і формалізованого описів, програмної реалізації. Однак тоді спостерігається неоднорідність опису, зумовлена проблемою погодження опису елементів модельованого об'єкта у вигляді деяких математичних співвідношень з чіткими математичними залежностями та певним способами задания зв'язків між цими елементами.
Технологія створення засобів автоматичного генерування імітаційних моделей передбачає [60]:
вибір ефективної і коректної конструктивної множини елементів моделі;
розробка засобів специфікації, вибору та налагодження елементів моделі;
наявність засобів конструювання моделі із обраних елементів.
Коректний вибір конструктивної початкової множини елементів визначає клас моделей, які можуть бути реалізовані за допомогою даних засобів. Щоб максимально розширити клас моделей, потрібно обирати множину елементів, якомога ближчу до мовних засобів імітаційного моделювання. Більш того, мова, яка обирається для моделювання, має бути декларативною, що спростить розроблення інтерфейсу між системою програмування та створюваними генератором імітаційними моделями завдяки уніфікації побудови та використання мовних засобів, закладених у самій мові.
Серед мов, які задовольняють таким вимогам, слід виділити мову імітаційного моделювання GPSS. За допомогою блоків цієї мови можна будувати дискрет- но-подійні моделі загального виду. Більше того, ця мова перевірена на практиці протягом понад 40 років на комп'ютерах майже всіх типів. Таким чином, створення генератора імітаційних моделей, в якому як проміжний код використовується код мовою GPSS, дає змогу в разі необхідності змінювати або розширяти генеровану програмну реалізацію імітаційної моделі.
Що ж стосується формальної структури генератора імітаційних моделей, то відомо, що найширший клас структур імітаційних моделей покривають стохастич- ні мережі СМО, які використовуються під час моделювання інформаційних, технологічних, транспортних, ділових процесів, систем обслуговування загального вигляду. Вибір класу структур моделей визначає обмеження на використання об'єктів або систем конкретної предметної галузі, тобто їх необхідно зображувати як дискретні об'єкти класу стохастичних мереж СМО.
Для створення методики автоматизованого синтезу програмних реалізацій імітаційних моделей певного класу потрібно побудувати формалізовану модель системи чи процесу у вигляді теоретико-множинного опису. Широкий клас структур концептуальних і імітаційних моделей можна зобразити як орієнтовані графи у вигляді:
G = (V,P, U),
де V — кінцева множина вершин; Р - кінцева множина дуг; U — функція, яка ставить у відповідність кожному ребру із множини Р упорядковану пару вершин із множини V.
Для програмного генератора, що розробляється, вершинам графа відповідає кінцева множина можливих атомарних подмоделей А^ об'єктів класів К. Характеристика класу К визначається сукупністю атрибутів Ь, які задають на полі класу у вигляді пари b = (і, f), де і - ім'я атрибуту, що належить даному класу, а / - функція, визначена на полі класу, яка задає порядок розглядання вершин із множини V.
Отже, для стохастичних мереж множина вершин Vвідображається множиною атомарних підмоделей А\, яка розбивається на два класи - К\ і К2:
Ау=Кх и К2,
де К\, К2 — класи об'єктів, модельованих відповідно як одно- та багатоканальні СМО.
Уведемо визначення. Під повідомленням (транзактом) будемо розуміти вимогу на обслуговування СМО, тоді дуги графу стохастичної мережі визначають можливі напрямки передавання повідомлень (транзактів) від однієї підмоделі до іншої.
Множина At визначає створення і використання імітаційних підмоделей, які дають змогу будувати узагальнену імітаційну модель завдяки засобам агрегова- ного опису класів однотипних підмоделей.
Множина Р визначає створення і реорганізацію зв'язків між підмоделями. Тоді пара
(а\,рі) І <2! є Аьр є Р, і = 1,..., п; j = 1,..., т,
деп,т— відповідно кількість можливих підмоделей і зв'язків між ними, визначає підмодель СМО і можливі напрямки передавання повідомлень від неї.
Під час проектування СМО виникає необхідність не тільки визначити маршрути рухів повідомлень між підмоделями, але і вказати умови просування транзактів за визначеними маршрутами. Така ситуація можлива, якщо множина вихідних ребер, інцидентних деякому вузлу, містить більше одного елемента. Тому в разі побудови формалізованої моделі програмного генератора потрібно, щоб множина дуг Р описувалась деякою сукупністю атрибутів d, значення яких будуть визначати процедуру вибору маршруту руху повідомлень від даної підмоделі.
Нехай F — функція побудови множини пар (вищенаведений вираз для абстрактної імітаційної моделі, причому F = Qі F = {/}.
Використовуючи під час генерування імітаційної моделі функцію F, можна об'єднати атомарний елемент і правило передавання повідомлення від нього, що дасть змогу провадити параметричне настроювання проектованої імітаційної моделі.
Детальний аналіз предметної галузі, тобто мереж СМО (див. розділ 2), показав, що множину підмоделей потрібно доповнити джерелами повідомлень і стоками, тобто клас атомарних підмоделей необхідно розширити до класу
А2 = Л] u В u С,
де В, С — класи об'єктів, які відповідно породжують повідомлення (генератори) і знищують повідомлення (термінатори).
Для побудови концептуальної моделі достатньо використовувати структуру вигляду
МІ-(А2,Р).
У процесі побудови логічної моделі об'єкта ця структура вимагає уточнення. В цьому випадку структура М] перетвориться в структуру вигляду
M2 = (A2,P,F),
яка дає змогу додержуватись такої послідовності: атомарні підмоделі — правила вибору — параметричне налагодження.
Якщо для концептуального рівня досить використовувати структуру Mlt задавши її матрицею можливих переходів, то для логічного рівня використання структури М2 є явно недостатнім і поверхневим. Необхідно провести конкретизацію з урахуванням того, що генератор програм орієнтований на конкретну мову моделювання GPSS, яка у свою чергу орієнтована на процеси. Покажемо, як структуру М2 може бути перетворено на структуру М3, що відображає програмну реалізацію імітаційної моделі.
Для цього визначимо специфікацію дискретної системи як структуру
М3-(Х, Y, 5, 1У, Fu F2),
де X, У, S - множини відповідно зовнішніх, внутрішніх і вихідних процесів (алгоритмів передавання повідомлень); Fj - функції переходів; F2 - вихідні функції, W = (Wh W2) — змінні моделі. Тоді
А2 = {(х, у > І * є X, у є У},
де х, у є Ку и К2 и В и С; F= (Fh F2), P є S.
Наведемо зв'язок структури M3 з конкретними блоками мови моделювання GPSS:
4-Х - множина блоків GENERATE, TERMINATE;
Y — блоки, пов'язані з визначенням пристроїв, накопичувачів, черг та блоки для збирання статистичних даних про черги;
S - блоки, які визначають і (або) змінюють маршрут руху транзактів у моделі (TRANSFER, TEST, SELECT, SPLIT та ін.);
W- визначення змінних у моделі (VARIABLE, SAVEVALUE);
F1 - функції, пов'язані з використанням логічних ключів (GATE, LOGICAL) для визначення умов руху транзактів;
F2 — функції, які визначають дисципліни надходження, обслуговування, руху і виходу транзактів із моделі.У цьому разі множину F2 можна ще інтерпретувати як таке відображення: нехай — поточний процес моделі, — множина процесів моделі, куди може бути передано транзакт із процесу (можливе й таке включення а2 є {«г})* тоді
F2: а2 -> {а2}.
Для програмного рівня формалізації модель визначається синтаксисом мови моделювання GPSS. Цей рівень у процесі автоматизації створення програмної реалізації моделі звичайному користувачеві не доступний, за винятком користувача-програміста, тому немає потреби в його формальному описі.
Особливість використання імітаційних моделей в інтерактивних системах визначається тим, що процедури пов'язані як з діями людини, так і машини. Тому необхідно вирішити проблему забезпечення ефективного діалогу моделі з користувачем, якому не відомі тонкощі математики, імітації, програмування, у рамках наведеного формального зображення процесу проектування імітаційних моделей. Такий діалог здійснюється мовою інтерактивної взаємодії з користувачем, яку реалізують через ієрархічну систему меню, інструментальну візуальну лінійку об'єктів і за допомогою елементів керування.
Отже, формальна модель опису об'єкта для проектування програмної реалізації імітаційної моделі зазнає послідовних змін структур Мь М2, М3, причому, якщо структури М\, М2 задає користувач у інтерактивному режимі, відповідаючи на запити системи, то структуру М-л мас створювати програмний генератор, використовуючи лінгвістичний процесор (ЛП) і множину вибору альтернативних варіантів для компонентів атомарних підмоделей і їх зв'язків.
Основне призначення лінгвістичного процесора полягає в тому, що він шляхом інтерактивної взаємодії з користувачем деякою мовою L має побудувати під- множину таких висловлювань D із деякої множини G, що тільки висловлення D буде завжди істинне.
Отже, ЛП задається четвіркою елементів (І., D, G, Т), де множина Г визначає деяку теорію щодо висловлювань G. З прагматичного погляду множина G визначає всі можливі альтернативи вибору з меню, що утворюють мову L. Підмножи- на D визначає тільки ті вибрані альтернативи, за якими алгоритм роботи ЛП, що визначає теорію Т, будує семантично і синтаксично правильні оператори GPSS- програми.
Мова І — це система елементів керування інтерактивного проектування моделей. Множина G відповідає множині альтернативних варіантів підмоделей, а під- множина висловлень D визначає параметричні налагоджені підмоделі для конкретної реалізації імітаційного проекту.
Для формалізації опису роботи ЛП скористаємося методами побудови трансляторів. З прагматичного погляду необхідно перетворити мову L взаємодії користувача з інтерактивною системою проектування в семантично і синтаксично правильно побудовану послідовність блоків GPSS-програми [91]. З урахуванням вищеви- кладеного визначимо атрибути, які описують елементи класів складових множини атомарних підмоделей Аъ у вигляді, в якому вони обробляються ЛП (з погляду теорії граматик). Для цього введемо спочатку деякі класи функцій аргументу h є Н. Послідовність функції {/} використовується для задавання різних імовірнісних законів розподілів часу обслуговування вимог у СМО
{/} I V/e{/}: h => И,
де h є Н, а 9? — такий алфавіт:
9? = ("Експоненціальний", "Рівномірний", "Нормальний", "Ерланга", "Детермінований", "Логнормальний", "Гамма-розподіл", "Бета-розподіл", "Вей§ула".
За допомогою послідовності функції {л} можна задати правила обслуговування вимог у СМО з урахуванням необхідності пріоритетного обслуговування
{л} І Ул є{л}: h => Р*,
де h є Я, а Р * — такий алфавіт:
Р* = ("без пріоритету", "відносний", "абсолютний").
Послідовність функції {р} дає змогу змінювати пріоритет вимог після обслуговування у визначеної СМО
{р} I Vp є{р}: h => ("не змінюється", "після обслуговування");
За допомогою послідовності функцій можна визначати процедури вибору повідомлень на обслуговування з черги до пристрою.
ш, Vi; h => ("FIFO", "LIF0", "за параметром", "RAND").
Послідовність функції {X} служить для задавання певних обмежень для черги до пристою.
{Я.} І УХ є{Я.}: h => ("без обмежень", "на довжину", "на час перебування").
Послідовність функції {т} служить для задавання типів змінних
{т} I Vt є{т}: h => ("цілочисельні", "дійсні").
Визначимо класи підмоделей одноканальних СМО як
KV.tf=(x\f, а1, р1, я1, р1^1, q1),
де і1 — ім'я пристрою, функція, значення якої складається з послідовності букв латинського алфавіту та цифр (довжина не більше ніж 8 символів);
Z1 — закон розподілу часу обслуговування вимоги пристроєм, /* є {/};
а1, (3 і — параметри закону розподілу, числові скалярні функції аргументу h є є В;
л1 — пріоритет обслуговування повідомлення в СМО, л1 є {л}; р1 — зміна пріоритету, р1 є {р};
5 і - значення зміни пріоритету (скалярна цілочисельна функція аргументу h є Я;
q1 — характеристика черги повідомлень до пристрою, q{ е Q. Черга вимог до пристою описується такою структурою
Q = <V kq,Xq,& q),
де iq — ім'я черги, функція, значення якої складається з послідовності букв латинського алфавіту та цифр (довжина не більше ніж 8 символів);
- правило вибору повідомлень з черги, i;q є
Xq — обмеження, що накладаються на чергу, X q е {X};
5? - обмежувальне значення, скалярна цілочисельна функція аргументу h е Я. Клас підмоделей багатоканальних СМО будемо задавати такою структурою:
К2: 62 = (i2,iV2, n\f\ а2, р2, я2, Р2, 52, «Д
де і2 - ім'я пристрою, функція, значення якої складається з послідовності букв латинського алфавіту та цифр (довжина не більше ніж 8 символів); N2 - кількість каналів багатоканальної СМО, скалярна цілочисельна функція аргументу he Н;
и2 - кількість каналів багатоканальної СМО, що займає одночасно одна вимога, скалярна цілочисельна функція аргументу he Н; У2 — закон розподілу часу обслуговування вимоги пристроєм, f2 є {/};
а2, р2 — параметри закону розподілу, числові скалярні функції аргументу h е Н\
л2 — пріоритет обслуговування вимоги в СМО, л2 є {л'}, л': h => Р* \ ("абсолютний"); р2 - зміна пріоритету, р2 є {р};
52 — значення зміни пріоритету, скалярна цілочисельна функція аргументу А є Я;
q2 — характеристика черги повідомлень до пристрою, q2 е Q. Клас генераторів вимог задається такою структурою:
В: Ъъ = </3, а3, р3, А3, Д32, а|, dl d\, dj),
де У3 — закон розподілу часу надходження вимог до моделі, У3 є {/};
а3, р3 — параметри закону розподілу, числові скалярні функції аргументу he Н;
А3, Д2, A3 — відповідно затримка першої вимоги, обмеження на кількість вимог, які генеруються, задавання пріоритету вимогам, булеві функції аргументу h е Я, тобто перераховані значення або задаються, або ні;df, d\,d\ — значення описаних вище властивостей елементів класу генераторів вимог, числові скалярні функції аргументу h є Н.
Клас термінаторів задається структурою
С: с1 - (Q1, ш1),
де Q1 — підрахування кількості вимог, які залишили модель, величина, що може приймати значення 0 чи 1 (булева);
со1 — значення для підрахування кількості вимог, які залишили модель, числові скалярні функції аргументу h є Н.
Визначення змінних у моделі задається структурою
W-.w'-i^, Є1, т>,
де w1 — характеристика змінної;
Ф1 — ім'я змінної, функція, значення якої складається з послідовності букв латинського алфавіту та цифр (довжина не більше ніж 8 символів);
0і — тіло змінної, функція, значення якої складається з послідовності букв латинського алфавіту та символів #, $, +, /, Л, * (довжина не більше ніж 256 символів);
т — тип змінної, т1 = ("з фіксованою крапкою", "з плаваючою крапкою"). Визначимо алфавіт А теорії Т, тобто всі можливі послідовності, якими оперує ЛП:
А = SR и Р* и ("FIFO", "UFO", "за параметром", "RAND") и ("без обмежень", "на довжину", "на час перебування") u ("з фіксованою точкою", "дійсні") и А' и А8 и Ц,
де А1 — латинський алфавіт; Ag — алфавіт мови GPSS; Ц — арабські цифри.
Покажемо фрагмент правил виводу ланцюжків D для атомарних підмоделей класу Ку. Попередньо додатково визначимо операцію конкатенації як а ©* Ь, що означає:
якщо а і b — рядки або символи, то результатом буде проста їхня конкатенація;
якщо один з операндів є числом, то результатом буде конкатенація його строкового зображення з іншим операндом, наприклад "Windows" ©* 2000 = "Windows 2000".
Операції конкатенації необхідні для перевірки правильності введених користувачем числових значень параметрів, які після перевірки перетворюються у звичайний текстовий формат мови GPSS.
Спочатку покажемо як створюються рядки GPSS-програми вибору функцій розподілу {f} для блока ADVANCE:
("Рівномірний") => ("ADVANCE "©V ©*"."© У); ("Детермінований") ("ADVANCE "©'а1); ("Експоненціальний") ("ADVANCE "©'а1©*".FNSEXPDIS"); ("Нормальний") ("VNOR VARIABLE "©*a1©*"+"©*p1©*"#FN$N0RM"); ("ADVANCE VSVNOR");
("Ерланга") І ("Логнормальний") І ("Гамма-розподіл") І ("Бета-розподіл") |("Вейбула") ("ADVANCE FN$"©*Ar)©*"_"©*a1©*"_"©y©*),
де/*(г): г є SR => ("Ерланга", "Логнормальний", "Гамма-розподіл", "Бета-розподіл", "Вей- була").
Покажемо фрагмент створення рядків GPSS-програми для атомарних підмоделей класу К і, тобто одноканальних СМО:
("без пріоритету")|("відносний") ("SEIZE "©і1).("RELEASE "©і1); ("абсолютний") ("PREEMPT "©і1),("RETURN "©і1);
("абсолютний") => ("SAVEVALUE l.PR").("SAVEVALUE 1+. "©'8і).("PRIORITY XI"); ("FIFO") ("QUEUE "©iq).("DEPART "©iq>;
("LIFO") ("QUEUE "ffiiq>, ("DEPART "©iq).("LINK SP1. LIFO DEVICE1"), ("UNLINK SP1. DEVICE1");
("на довжину") => ("TEST L Q$"©iq©". "©*8q©*".COMTER"):
("на час перебування") => ("MARK T"©iq).("TEST L MP$T"©iq©". "©*8q©*".COMTER").
Список SP1 пов'язаний з пристроєм з номером 1. Позначка DEVICE1 використовується для блоку SEIZE з номером 1, а позначка COMTER — для вимог, яким відмовлено під час поставлення в чергу (наприклад, вони можуть знищуватись за допомогою блока TERMINATE, що має цю позначку).
Для класу К2 побудова ланцюжків правил виводу D буде аналогічною за винятком
(i2©"ST0RAGE "©'АГ2);
("без пріоритету") І ("відносний") ("ENTER "©і2©", "©V), ("LEAVE "®і2©","©У);
("на час перебування") ("MARK T"©iq), ("GATE SNF"©i2), ("TEST L MP$T"©iq©". "©*8q©*", "COMTER").
Як було зазначено вище, для більш повного покриття множини різних моделей стохастичних мереж необхідно визначити правила передавання повідомлень від вузла до вузла, коли множина вихідних ребер, інцидентних даній вершині концептуальної схеми моделі, перевищує 1. Набір атрибутів d, за допомогою яких описують елементи множини ребер Р, може бути рішенням цієї проблеми, однак зручніше розглядати всю множину вихідних ребер конкретного вузла. Позначимо цю множину як Ra2. Уведемо функцію аг як функцію вибору маршруту переміщення транзакту. Множиною значень цієї функції будуть елементи множини
а(а2\Є) є {pj} I V pj є{р/} 3 (а2\ рД
де а2 є А2, pj є Р, 0 — ознака, за якою описується стан вершини а2, а пари елементів (а2, pj) є припустимими щодо функції F.
Тобто функція су здійснює вибір ребра руху вимоги для вершини а2 із множини Ra2. Опишемо умови, які накладаються на переміщення вимог між підмоделями. Ці умови буде визначено як атрибути dг елементів множини Ra2.
dт = {(безумовно), (за імовірністю), {ф^обмеження числом){фг}, (в усіх напрямках)},
де {ф^ — множина значень імовірностей переміщення вимог по визначених ребрах, (числові скалярні функції);
{фг} — числа, які обмежують кількість транзактів, переданих по визначених ребрах (числові скалярні функції).
Таким чином, для передавання вимог можна побудувати правила висновку ланцюжків D, аналогічні правилам для атомарних підмоделей класу Kv
На множині вихідних ланцюжків правил висновку теорії Г задамо функцію Ф, яка встановлює антирефлексивне транзитивне відношення (строгий порядок). Покажемо в табличному вигляді цю функцію (табл. 5.1) для множини аргументів — ланцюжків D, одержуваних за правилами висновку для атомарних підмоделей класу
| Таблиця 5.1. Впорядкування послідовності блоків згідно з функцією Ф | |
| Аргумент | Значення |
| ("ADVANCE ") | |
| ("PREEMPT "> | |
| ("SEIZE "> | |
| ("RELEASE "> | |
| ("RETURN") | |
| ("SAVEVALUE l.PR") | |
| ("SAVEVALUE 1+."©V) | |
| ("PRIORITY XI") | |
| ("QUEUE "> | |
| ("DEPART ") | |
| ("LINK SP1.LIF0") | |
| ("UNLINK SP1") | |
| ("TEST L Q$"©iq©","©*5q®*",C0MTER") | |
| ("MARK T"©iq) | |
| ("TEST L MP$T" © iq © "," ©* 8q ©* ".COMTER") | |
| ("GATE NU") |
Таким чином, одержуємо пріоритетно-упорядковану множину операторів програми на мові GPSS.
Розглянемо приклад створення програми реалізації імітаційної моделі СМО. Нехай на вхід лінгвістичного процесора надійшов опис моделі у такому вигляді:
М2 = {а, 0, 0>,
де а є Кі I ba = ("MACHINE", "Експоненціальний", 50, 0, "абсолютний", "після обслуговування", 10, "QUEUE1", "LIF0", "на довжину", 8);
Застосовуючи правила виводу для класу К\, отримаємо такі рядки коду мовою GPSS:
ADVANCE 50.FNSEXPDIS PREEMPT MACHINE RETURN MACHINE SAVEVALUE l.PR SAVEVALUE 1+,10 PRIORITY XI QUEUE QUEUE1 DEPART QUEUE1 LINK SP1.LIF0.QUEUE1 UNLINK SP1.QUEUE1 TEST L QSQUEUE1.8,COMTER
Використовуючи функцію Ф, отримаємо впорядковану множину рядків:
TEST L QSQUEUE1.8.COMTER QUEUE QUEUE1 LINK SP1.LIF0.QUEUE1 PREEMPT MACHINE DEPART QUEUE1 ADVANCE 50.FNSEXPDIS RETURN MACHINE UNLINK SP1.QUEUE1 SAVEVALUE l.PR SAVEVALUE 1+.10 PRIORITY XI
З огляду на вказані вище умови і переходячи до програмної реалізації, можна стверджувати, що в ЛП необхідні такі підпрограми:
оперування з вершинами концептуальної мережі, які настроюються на тип конкретного вузла, що визначається належністю до заданої підмножини класу атомарних підмоделей;
генерування програмного коду мовою GPSS для випадку передавання повідомлень;
роботи з функціями імовірнісних розподілів і функціями, що задає користувач у моделі;
заповнення текстів заголовків для функцій, змінних, таблиць і накопичувачів;
збирання статистичних даних про роботу елементів моделі;
остаточного формування тексту GPSS-програми.Для зручності програмної реалізації ЛП необхідно задавати вузли не як деяку однорідну множину об'єктів, а розділити їх за типами. Причому якщо ввести типи вузлів аналогічно класам Klt К2, В и С, то завдяки уніфікації формальних правил виводу, визначених для кожного з цих класів, і програмних функцій обробки інформації трудомісткість написання коду й ефективність його роботи різко збільшиться.
Згідно з наведеними вище методами проектування імітаційних моделей та формалізованою процедурою проектування програмного генератора, а також з огляду на вимоги, виконання яких передбачає технологія проектування імітаційних моделей досліджуваних об'єктів, визначається організаційна структура інтерактивної системи імітаційного моделювання ISS 2000 [61]. Вона складається із сукупності взаємопов'язаних програмних модулів, які виконують різні процедури: керування, прийняття рішень і перетворення інформації й даних, що містять відомості функціонального та інформаційного характеру.
На концептуальному рівні модель системи задається графом, вершини якого являють собою множину об'єктів моделі, таких як генератори вимог, одно- або багатоканальні пристрої обслуговування, термінатори тощо. На логічному рівні визначаються властивості цих об'єктів і зв'язки між ними. Програмний рівень подання моделі містить готовий код програми моделювання на мові GPSS, який створюється після компіляції проекту моделі.
Такий програмний генератор повністю автоматизує процес створення імітаційної моделі та проведення експериментів з нею, але не означає, що користувач не може змінити або дописати код програми. Користувач може вносити зміни до коду програми моделювання.
5.9. Імітаційна модель персонального комп'ютера
Визначимо цілі моделювання персонального комп'ютера (ПК). Припустимо, що метою моделювання є прогнозування впливів зміни продуктивності устаткування на середню пропускну здатність ПК і середній час виконання програм. Будемо розглядати ПК із загальною шиною, схему якого зображено на рис. 5.6.
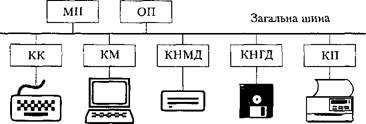
Клавіатура Монітор НМД НГД Принтер
Рис. 5.6. Структура персонального комп'ютера із загальною шиною
З основних пристроїв комп'ютера виділимо ті, які повинні бути відображені в моделі, а саме: мікропроцесор (МП), оперативну пам'ять (ОП), монітор, накопи- чувач на жорстких магнітних дисках (НМД), накопичувач на гнучких магнітних дисках (НГД), принтер, клавіатуру та контролери цих пристроїв — контролер клавіатури (КК), контролер монітору (KM), контролер НМД (КНМД), контро лер (КНГД), контролер принтера (КП).
Функціонування комп'ютера можна описати таким чином. Користувачі з клавіатури вводять команди, що складаються з кількох інструкцій, які викликають програмні модулі. Кожну інструкцію будемо вважати одним кроком завдання. Програма та дані знаходяться на магнітних дисках і завантажуються в оперативну пам'ять за окремою командою. Роботу користувача з клавіатурою в моделі можна не враховувати, припускаючи, що набір команд з клавіатури відображається на екрані монітора. Для перенесення програми з магнітних дисків у пам'ять комп'ютера організується вхідний буфер. Якщо обсяг пам'яті достатній для виконання першого кроку, то після завантаження програми в пам'ять і надання їй часу процесора вона може опрацьовуватися ним доти, доки не видасть запит до магнітних дисків або принтера. У той час, коли здійснюється введення-виведення даних на зовнішні пристрої, процесор може виконувати інше завдання. Після виконання операції введення-виведення даних завдання знову чекає в черзі, доки йому не буде надано час процесора. Якщо крок завдання закінчився, то звільняється пам'ять і здійснюється виведення даних на принтер через вихідний буфер.
Вважається, що на жорсткому диску знаходяться програми операційної системи і системні програми, а також бібліотеки користувача. Під час виконання програми вона може запитувати вхідні дані з гнучкого диска. Роботу операційної системи і системних програм до уваги не прийматимемо, припускаючи, що вони в однаковій мірі впливають на програми користувачів.
5.9.1. Концептуальна модель персонального комп'ютера
Всі пристрої, продуктивність яких впливає на час виконання завдання на комп'ютері, будемо розглядати як ресурси системи. Такі пристрої, як монітор, процесор, накопичувачі на магнітних дисках і принтер, не можна експлуатувати в режимі розподілу часу, тобто в конкретний час їх може використовувати тільки одне завдання. У пам'яті ж одночасно можуть знаходитись кілька завдань. Завдання може одночасно використовувати кілька ресурсів.
Враховуючи те, що швидкість роботи контролерів пристроїв уведення-виве- дення значно перевищує швидкість роботи самих пристроїв, будемо вважати, що швидкість роботи пристроїв визначається швидкістю роботи самих пристроїв, а не їх контролерів.
Тоді структурну схему концептуальної моделі комп'ютера можна відобразити так, як зображено на рис. 5.7. Зазначені на схемі лічильники необхідні для підра- хування кількості завдань, які надійшли до комп'ютера і залишили його.
Вхідні і вихідні буфери можна об'єднати відповідно з монітором і пристроєм для друку. Тоді в концептуальній моделі будуть явно задані такі ресурси: МП, ОП, НМД, НГД, МОНІТОР, ПРИНТЕР.
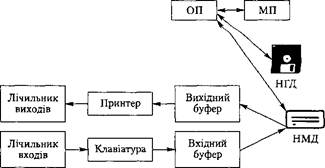
Рис. 5.7. Концептуальна модель комп'ютера
З огляду на мету моделювання визначимо, що на виході моделі необхідно отримати дані про середній час виконання завдань і пропускну здатність комп'ютера (кількість завдань, виконаних за певний час). Вхідні дані визначають закон розподілу надходження завдань у комп'ютер, число кроків у кожному завданні та ємність пам'яті, загальний час виконання кроку завдання процесором, частоту запитів до зовнішніх накопичувачів і пристроїв, розподіл обсягу виведеної на друк інформації, обсяг інформації, яка зчитується або записується на зовнішні накопичувані, обсяг інформації, що вводиться. Ці дані можна отримати за допомогою програм тестування реального комп'ютера. Крім цих даних необхідно задати параметри для пристроїв комп'ютера, такі як швидкодія процесора, ємність пам'яті, накопичувачів на магнітних дисках, вхідних і вихідних буферів, мінімальний та максимальний час пошуку даних на магнітних дисках, швидкість друку на принтері, швидкість уведення інформації з клавіатури.
5.9.2. Розроблення імітаційної моделі
Для розроблення моделі скористаємось подійним алгоритмом моделювання. Для кожної пари «завдання—ресурс» будемо визначати, як довго деяке завдання J використовуватиме деякий ресурс R, тобто визначатимемо інтервал часу, коли завданню J буде призначено ресурс R і коли воно звільнить цей ресурс.
Однак перед тим, як ресурс R буде призначено завданню J, повинна надійти вимога на його використання. У загальному випадку завдання може чекати в черзі надання ресурсу.
Тоді під час створення імітаційної моделі комп'ютера можна користуватись такими двома способами.
Створити та підтримувати протягом моделювання список подій у хронологічному порядку.
Створити підпрограми опрацювання подій кожного типу і викликати їх тоді, коли подія даного типу стає першою в списку подій. Всі підпрограми подій можуть змінювати список подій, створюючи нові події та плануючи їхнє виконання в деякому майбутньому модельному часі.
Діаграму подій імітаційної моделі комп'ютера зображено на рис. 5.8.
{8}
Надходження
Звільнення ОП
{7}
і
Запит-призначення пристрою друку
Введення команди з клавіатури на монітор
Запит-призначення монітора
І
Запит-призначення НМД
Запит-призначення НМДПошук, затримка, пересилання НМД - пристрій друку
Пошук, затримка, пересилання НМД - монітор
{1}
{9}
Звільнення НМД
Звільнення НМД
{2}
Звільнення монітора
{10}
13 Звільнення пристрою друку
Вихід
6 Запит-призначення ОП
1.
{5}
Запит-призначення НМД
Запит-призначення НМД
Пошук, затримка, пересилання НМД - ОП
Звільнення НМД
т
Звільнення НМД
{6}
{4}
Запит-призначення МП
W-
{2}~ {3>- {4}-
{5}- {6}~ {7}- {8}- {9}-
{10}-
Обчислення (Розрахунок)
Звільнення МП
{3}
Запит-призначення НГД
Затримка, пересилання НГД - ОП
Звільнення НГД
вхідний буфер порожній, пересилання не завершено; введення інформації завершено; запит до НМД; крок завдання не завершено; запит до НМД; крок завдання завершено; кроків завдань більше немає; ще є кроки завдання?; вхідний буфер повний, друк не завершено; друк завершено
Рис. 5.8. Діаграма подій імітаційної моделі комп'ютера Тепер опишемо алгоритми роботи цих підпрограм. Підпрограма Запит-призначення
Якщо ресурс R вільний і його можна негайно виділити завданню J, то він позначається як зайнятий і планується настання наступної події для завдання J. У протилежному випадку запит від завдання J ставиться в чергу до ресурсу R.
Підпрограма Звільнення
Ресурс R позначається як вільний і планується наступна подія для завдання J. Якщо черга до ресурсу R не порожня, планується подія Запит-призначення чергового завдання К для ресурсу R і завдання вибирається з черги до ресурсу R. У протилежному випадку підпрограма не виконує ніяких дій.
Для того щоб простежити шляхи проходження завдань по ресурсам комп'ютера, необхідно визначити ще дві події і відповідні підпрограми: Надходження та Вихід. Між цими подіями не існує явного зв'язку. Якщо уявити персональний комп'ютер як деякий узагальнений ресурс, то підпрограма Надходження завжди призначає цей узагальнений ресурс завданню, яке надійшло.
Підпрограма Надходження
Готує характеристику (параметри) завданню J, тобто фіксує час надходження завдання до ПК. Визначає вимоги завдання до ресурсів. Планує наступну подію для J і прибуття наступного завдання К.
Підпрограма Вихід
Підпрограма Вихід є набагато простішою за підпрограму Звільнення. Вона лише знищує характеристику завдання J.
Структурну схему програми імітаційної моделі комп'ютера наведено на рис. 5.9.
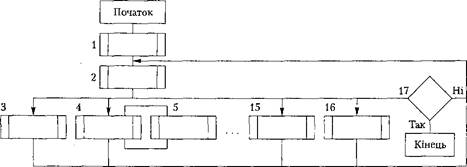
Рис. 5.9. Структурна схема програми імітаційної моделі комп'ютера: 1 — підпрограма ініціалізації; 2 — ПКМ; 3 — підпрограма події 1 (Надходження); 4 — підпрограма події 2 (Запит-призначення МОНІТОРА); 5 — Звільнення МОНІТОРА;... 15 — підпрограма події 13 (Вихід); 16 — Вибірка; 17 — перевірка завершення моделювання
Програма ініціалізації готує структури даних, необхідні для моделювання, та задає їм початкові значення. Програма керування моделюванням вибирає (викликає) наступну подію, яка після виконання підпрограми повертає керування ПКМ, а потім збільшує модельний час до наступної події. Обидва ці завдання виконуються шляхом перевірки запису в списку подій. Кожний запис у цьому списку містить:
тип події, яка використовується для виклику відповідної підпрограми події;
ім'я або номер завдання, що передається як аргумент усім підпрограмам події;
тип події, що буде викликатись за даною подією.
Якщо необхідно враховувати пріоритетне планування, алгоритм роботи підпрограми обробки події процесора значно ускладнюється. Програми, які виконуються комп'ютером, можуть мати різний пріоритет, наприклад програми операційної системи і програми користувачів. Якщо поява більш пріоритетного завдання може перервати виконання процесором завдання з меншим пріоритетом, то необхідно дозволити процесору виконувати завдання з більшим пріоритетом, як тільки воно з'явиться в черзі. У цьому випадку подію звільнення процесора від завдання потрібно вивести зі списку подій за допомогою програми Запит-призначення для процесора і процесор призначити завданню з більш високим пріоритетом. Ця ж підпрограма повинна поставити перерване завдання в чергу до процесора для того, щоб надати їй його знову для доопрацювання перерваної програми. Надходження завдання з більшим пріоритетом може також перервати завдання, яке виконує процесор, тобто в цьому випадку може утворитись список перерваних завдань.
На діаграмі подій є події, після яких можливе одночасне настання двох подій. Ці події є взаємовиключними. Порядок звертання до тих або інших подій залежить від логіки та характеристик завдань, виконуваних користувачем.
Наприклад, після звільнення НМД для 7-го завдання необхідно запланувати настання однієї з таких подій:
Запит-призначення НМД;
Запит-призначення МП;
Звільнення ОП;
Звільнення принтера.
Наприклад, Запит-призначення МП буде заплановано в тому випадку, якщо завдання J було тільки що завантажене в пам'ять або запит на НМД був задовільний, а обчислення для поточної команди завдання ще не завершене. Таким чином, інформація про послідовність виконання подій у програмі повинна утримуватись у самій моделі та безперервно опрацьовуватись у процесі моделювання.
Підпрограму Вибірка призначено для збору статистичних даних у процесі моделювання. Наприклад, пропускну здатність комп'ютера можна визначити, якщо підрахувати завдання, які залишили комп'ютер у підпрограмі Вихід, і поділити їх на час моделювання після виходу всіх завдань. Також потрібно збирати статистичні дані про завантаження ресурсів. Для цього необхідно визначити загальний час використання ресурсу та поділити його на загальний час моделювання.
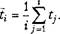
Для визначення середнього часу виконання завдань користувачів у системі позначимо через tt середній час проходження по перших і завданнях, а через tj — час проходження завдання/ Тоді середній час виконання завдань знайдемо як
(5.1)
Для наступного завдання,/ + 1 формула (5.1) буде мати такий вигляд:
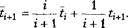
(5.2)
Аналогічно запишемо оцінку вибіркової дисперсії of+1, використовуючи визначення для оцінки дисперсії та знаючи erf, отримаємо за допомогою кількох алгебричних дій вираз
+ (5-3)
і + 1 (г +1)
Формули (5.2) і (5.3) дають змогу рекурентно обчислювати всі послідовні значення відповідно для оцінювання математичного сподівання та дисперсії (of = 0). Потрібно тільки знати значення і, сі;2, ti+\ і t{.
5.9.3. Процесно-орієнтований алгоритм моделювання персонального комп'ютера
СМП
ПУМ
Для того щоб урахувати взаємодію процесів у моделі, потрібно вести два списки подій: список майбутніх подій (СМП) і список умовних подій (СУП) (рис. 5.10). Основна увага при розробці моделюючого алгоритму зосереджується на шляхах проходження завдання в моделі і взаємодіях процесів, що виконуються паралельно. Підпрограма процесу описує «життєвий цикл» завдання в системі.
Початок
Ініціалізація]
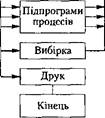
Рис. 5.10. Списки подій для моделі комп'ютера, орієнтованої на процеси
Якщо наступна подія для модельованого завдання повинна відбутись у деякий модельний час, то цю подію можна планувати безумовно, і для неї додається запис у СМП. Якщо це зробити неможливо, наприклад через взаємодію з іншими завданнями, які в даний момент займають необхідні ресурси, то запит подається в СУП. Після цього керування повертається до ПКМ, яка здійснює повернення в підпрограму процесу через точку входу, що є безпосередньо наступною за оператором ЧЕКАТИ (умови) доти, доки завдання не буде вибране для обслуговування цим ресурсом. Таким чином, підпрограми процесів повинні мати ряд точок входу та виходу з процесів.
На рис. 5.11 зображено схему частини процесу для надання завдання МП для обчислювання. У цій схемі ПКМ, а не програма процесу, планує та призначає ресурси. Схему можна модифікувати, щоб це завдання вирішувала програма процесу.Дійсно, ресурси розглядаються як пасивні об'єкти, і ця схема не моделює в явному вигляді поведінку ресурсу.
Точка входу
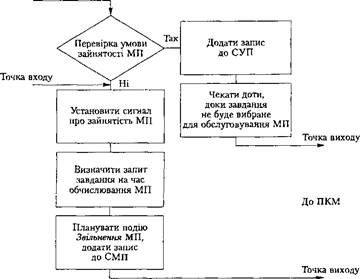
Рис. 5.11. Фрагмент блок-схеми призначення процесора завдання
Фрагмент блок-схеми, яка в явному вигляді моделює поведінку ресурсу, зображено на рис. 5.12.
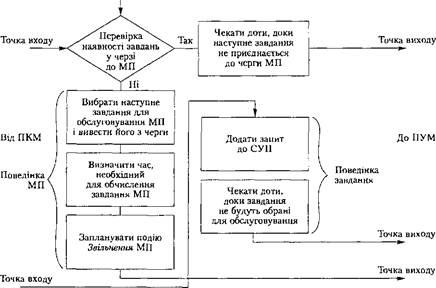
Рис. 5.12. Фрагмент схеми, яка
в явному вигляді моделює поведінку ресурсу
5.10. Перевірка достовірності і правильності імітаційних моделей
Технологія імітаційного моделювання охоплює всі етапи життєвого циклу моделі — від її створення до впровадження та супроводження. У розділі 5.3 було визначено основні взаємопов'язані етапи імітаційного моделювання, після кожного з яких необхідно робити перевірки, щоб довести відповідність моделі цілям моделювання. Перш за все під час перевірки моделі потрібно відповісти на два основних запитання:
Чи правильно побудовано імітаційну модель?
Чи побудовано правильну імітаційну модель?
Перше питання стосується верифікації (verification) — перевірки достовірності моделі, яка доводить, що модель правильно і з достатньою точністю переведено від однієї форми в іншу. Перевірка достовірності моделі пов'язана з правильною побудовою моделі. Точність перетворення формулювання проблеми в модельний опис і точність перетворення модельного зображення із логічної блок-схеми у розроблену комп'ютерну програму оцінюються під час перевірки достовірності моделі.
Друге питання стосується валідації (validation), тобто обґрунтованості моделі, відповідності її задуму, або доказу правильності моделі. Модель повинна в межах галузі використання працювати з потрібною точністю, і її використання повинне відповідати цілям моделювання. Це стосується порівняння поведінки моделі з поведінкою системи.
Останнім часом використовують ще один термін — акредитація (accreditation), тобто офіційне свідчення того, що імітаційна модель прийнятна для застосування в межах деякої області, обумовлених цілями моделювання.
Існує багато методів для перевірки достовірності та правильності імітаційної моделі й довіри до неї. У праці Болкі [71] розглянуто понад 100 методів для дослідження звичайних і об'єктно-орієнтованих імітаційних моделей та загальні принципи перевірки моделей. Перевірка достовірності і правильності моделі, тестування, адекватність, легалізація і дії щодо оцінювання довіри насамперед пов'язані з вимірюванням і оцінюванням точності під час моделювання та імітації. Обґрунтування адекватності моделі доводить, що модель працює, у межах використання, із задовільною точністю, сумісною з метою імітаційного моделювання.
Ітераційна процедура проектування імітаційної моделі передбачає порівняння результатів моделювання та вихідних змінних реальної системи за умови, що вхідні дані однакові, у результаті чого визначається точність моделі. Модель вважається досить точною, якщо її вихідні змінні відрізняються від вихідних даних модельованої системи менш ніж на задані граничні значення. Отже, точність моделі визначається різницею між вихідними даними системи та моделі. Під час порівняння двох варіантів моделі для визначення кращого необхідно використовувати однакові послідовності випадкових чисел. За показник якості критерію оцінювання точності можна брати похибку, яка визначається як різниця між середніми значеннями вихідних величин системи та моделі. Якщо для деякої вихідної змінної системи у і (і = 1,..., т) знайдено п значень, то
1 "
Еі -y'ij)' і=1,-,т; j = і,..., п,
п і=1
де y\j — і-та вихідна змінна моделі.
У разі використання похибки як показника якості критерію Е\ можливий значний розкид конкретних і-х значень для величин у у та у'у. Тому такий критерій буде кращим у тому разі, якщо в ньому використовуються функції розподілу для Уу та у'у, тобто відповідно Ffy) та -F;(z/'). Тоді можна визначити похибку як
+СС
j\Fi(y)-Fi(y')\dy.
о
Доцільніше використовувати оцінку Еь ніж Е{, бо перша дає змогу порівнювати локально, або поточково, ці дві функції і підсумовувати абсолютні значення їх різниць. Завдяки цьому можна уникнути часткової компенсації похибок через різницю знаків. Здобуття результатів моделювання, розподіли яких ідентичні або близькі, є необхідною, але не достатньою умовою для того, щоб модель була точною в межах області розумних значень вхідних змінних. У цьому разі цілком можливо, що поведінка деяких процесів у моделі відрізнятиметься від поведінки цих самих процесів у системі, навіть якщо модель за деяких вхідних умов демонструє такі самі вихідні розподіли, як і система. Причому ефективнішим критерієм оцінювання, ніж Е{ та Е2, буде той, в якому використовується розподіл різниці значень для у у та у\у Як такий критерій можна застосувати середнє арифметичне квадратів різниць значень:
1 "
£з -y'ijf, і=1,-,Щ j=l,...,n.
п
Отже, ітераційне проектування імітаційної моделі має мінімізувати обрані критерії Ех, Е2, Е3. Критерії Е2, £3 можуть використовуватись і для детермінованих моделей, хоча вони мають вигляд випадкових і визначають розкид значень вихідної величини.
Складності під час оцінювання точності моделі виникають тоді, коли модельованої системи не існує або вона є недоступною для проведення експериментів. У цьому разі необхідно використовувати ті самі методи, що й під час перевірки правильності моделі з використанням контрольних завдань і залученням експертів.
Порівнюючи два або більше варіантів імітаційної моделі, звичайно не цікавляться абсолютними показниками для кожної моделі, а тільки звертають увагу на характеристики, які порівнюють. Для порівняння потрібно знати діапазони змін основних вхідних змінних і провести якісний аналіз варіантів порівнюваних моделей, як, наприклад, зображено на рис. 5.13. Передбачається, що розглядається два варіанти моделі мережі обробки інформації А та В, для яких основним критеріємвибору системи є час її реакції на запит користувача £від, який залежить від кількості увімкнутих терміналів N. На рис. 5.13, а видно, що варіант А в цьому діапазоні зміни навантаження кращий за варіант В. Якщо маємо графіки, зображені на рис. 5.13, б, то необхідне уточнення значень параметрів.