КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
И их применение для решения экономических задач
|
|
|
|
Централизованные и распределенные базы данных
С появлением и развитием корпоративных и иных сетей появилась возможность организации доступа к одним и тем же данным из различных структурных подразделений предприятия или из других регионов. При этом разработаны два вида баз данных:
- централизованные;
- распределенные.
Централизованная база данных характерна тем, что она полностью находится на центральном компьютере, к которому обращаются пользователи (клиенты) с помощью своих компьютеров за информацией. Управление базой данных (ее корректировка и прочие процедуры, поддерживающие ее целостность, безопасность и пр.) осуществляется централизованно (см. рис.
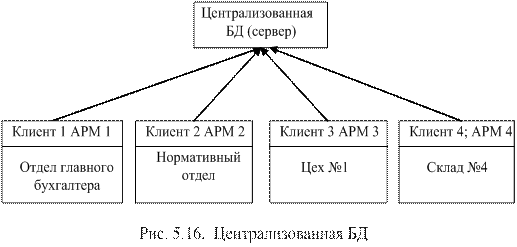
5.16). Один компьютер, который располагает ресурсами, называется сервером. Компьютер, который обращается к серверу за данными или требованием решения задачи, называется клиентом.
Недостатки централизованной БД состоят в следующем:
- требуется передача большого потока данных;
- низкая надежность;
- низкая производительность.
Преимущества: минимальные затраты на корректировку централизованной БД.
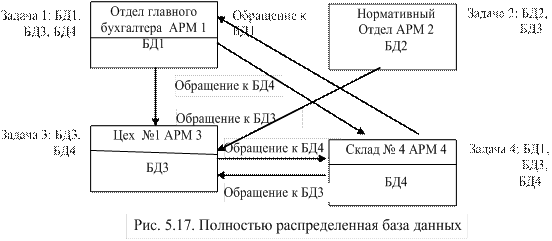
Для снижения остроты перечисленных недостатков создают распределенные базы данных, то есть базы, части которой находятся в различных узлах сети. Предприятия сами по себе имеют распределенную структуру, поэтому данные фактически распределены по структурным подразделениям. Фактически распределенная база данных есть виртуальный объект, составные части которого хранятся в разных узлах сети. Для пользователя они находятся в одной логической модели базы данных. На рис 5.17 представлена сеть с полностью распределенной БД. Стрелки указывают на направление передачи данных, необходимых для решения задач в конкретном узле:
· для решения задачи 1 в отделе главного бухгалтера требуются базы данных БД1, БД3, БД4;
· для решения задачи 2 в нормативном отделе требуются базы данных БД2, БД3;
· для решения задачи 3 в цеху № 1 требуются базы данных БД3, БД4;
· для решения задачи 4 на складе № 4 требуются базы данных БД3, БД4.
Полностью распределенная БД создается в тех случаях, когда частота решения всех задач и объемы передаваемых данных для их решения примерно одинаковы.
Главный критерий распределения данных в сети состоит в следующем: данные должны находится там, где существует наибольшая частота обращения к ним.
Для решения экономических задач в средах централизованной или распределенной базы данных можно воспользоваться одним из следующих методов доступа к данным:
1. Доступ на основе архитектуры сети вида "файл-сервер";
2. Доступ на основе архитектуры сети вида "клиент-сервер".
1. Доступ на основе архитектуры сети вида "файл-сервер".
Схематично такой метод доступа можно представить в виде рис. 5.19.
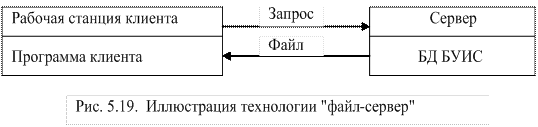
В процессе решения задач пользователя, который использует доступ вида "файл-сервер", будет передаваться кроме необходимых данных и сопутствующая. Примеры. Пусть общая база данных бухгалтерской информационной системы (БУИС) хранится на сетевом сервере. Тогда:
- для запуска программы печати журнала/ордера к счету "Касса", согласно данной технологии, будут передаваться все проводки, среди которых нужно будет выбрать те, что касаются счета "Касса";
- если потребуются сведения о каком-либо основном средстве, то будет передан из сервера весь файл инвентарных карточек, среди которых следует отыскать нужную;
- если поступит запрос о начисленной заработной плате какого-либо сотрудника, то будет передан из сервера фал со всеми сотрудниками, в котором необходимо отыскать нужную запись.
Таким образом, файл-серверная обработка – это обработка данных преимущественно на рабочих местах клиентов. Сетевое программное обеспечение занято лишь передачей данных на рабочую станцию.
2. Доступ на основе архитектуры сети вида "клиент-сервер".
В данной архитектуре возможны следующие варианты доступа:
- доступ к удаленным данным (ДУД);
- доступ с помощью сервера баз данных (СБД);
- доступ с помощью сервера приложений (СП).
А). Согласно модели ДУД на компьютере клиента располагается программа, которая производит ввод исходных данных, программа, осуществляющая решение задачи на основе дополнительно поступивших из сервера данных и программа печати результатов. Если запущена программа "Касса", то будут переданы лишь те проводки, которые необходимы для обработки и печати журнала/ордера. Иллюстрацией этого служит рис. 5.20.

Б). Согласно модели СБД на компьютере клиента находятся программы ввода исходных данных и печати. Программа решения задачи находится на сервере, где собственно, и происходит ее запуск. На компьютере клиента осуществляется лишь ввод исходных данных и печать результатов (см. рис. 5.22).

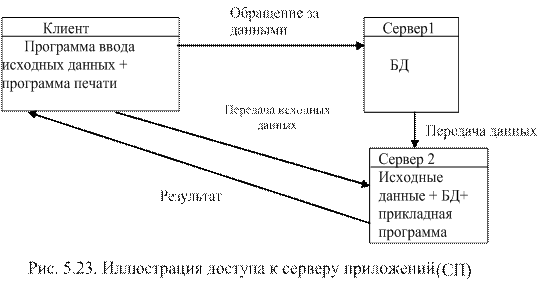
В). Согласно модели СП (см. рис. 5.23) ввод, передача, обработка и печать результатов выполняется также как и в модели СБД за исключением того, что прикладная программа и исходные данные находятся на одном сервере, а БД на другом.
11. Хранилища данных и их применение для формирования экономических решений
Рассмотренные ранее OLAP-технологии часто реализуются с помощью хранилищ данных, являющихся дальнейшим развитием реляционных баз данных. Хранилище данных (ХД) – это предметно-ориентированный, неизменяемый и поддерживающий хронологию набор данных. Часто возникает вопрос: для чего нужны хранилища данных, если существуют базы данных? Ответом может быть следующее: в отличие от баз данных, которые предназначены для обслуживания повседневной деятельности предприятия, ХД ориентированы на многолетний оперативный многомерный анализ данных, результаты которого могут быть использованы для принятия решений.
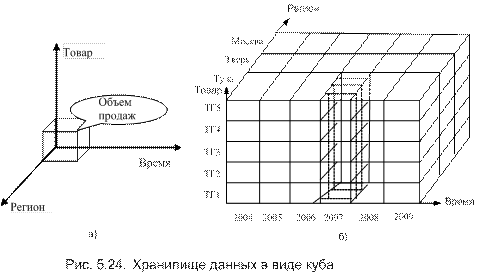
Моделью данных в ХД служат гиперкубы, т.е. многомерные базы данных, в ячейках которых находятся анализируемые данные. По осям многомерного куба указываются измерители объекта с различных точек зрения. Пример гиперкуба (три измерения) представлен на рис. 5.24.
Аналитические измерения – это набор учетных признаков, которые могут быть присвоены каждой хозяйственной операции. Аналитические отчеты это данные объектов учета и управления, сгруппированные по нескольким измерениям. Например, для параметра “время” это последовательность месяцев, для параметра “регион” – список городов. Большинство измерений можно представить иерархической структурой. Например, измерение “исполнитель” может иметь следующие иерархические уровни: предприятие – подразделение – служащий.
На пересечении осей измерений находятся данные, количественно характеризующие события, факты, процессы (объемы продаж, остатки товаров на складах, прибыль, затраты и т.д.).
Оси измерений позволяют создавать многомерную модель данных (гиперкуб), над которым можно выполнять следующие операции:
- срез;
- вращение;
- консолидация или детализация.
Операция среза позволяет выделить из многомерного куба те данные, которые соответствуют зафиксированному (указанному) значению одного или нескольких элементов измерений. Из одного куба можно создать множество срезов. Пример операции среза представлен на рис. 5.24, который иллюстрирует хранилище данных, предназначенное для подготовки аналитической информации по продажам. Объем продаж характеризуется тремя измерениями: регион, время, товарная группа (ТГ). На рис. 5.24б с помощью заштрихованной части показан тот срез, который характеризует объемы продаж в г. Туле в 2003 году по всем товарным группам. Такой срез позволяет подготовить информацию для принятия решений о том, какие товарные группы следует сворачивать, а какие развивать в регионах.
Обратимся к более детальному представлению хранилища данных в виде срезов, приведенных на рис. 5.25. Базовый показатель, на основании которого принимается такое решение, - объем продаж. Он зависит от – времени, группы товаров и региона. Для построения информационного куба, прежде всего, необходимо определить иерархию в измерении реквизитов-признаков показателя "объем продаж".
Объем продаж характеризуется следующими признаками:
Время: год- квартал- месяц- неделя- день;
Товар: группа товаров (ТГ) - подгруппа - наименование товара;
Регион: 1-й уровень (Центральный, Уральский, Поволжье);
2-й уровень (Москва, Тула, Орел);
3-й уровень (Магазин-1, Магазин-2).
С помощью информационного куба, получив из него необходимый срез, можно извлечь различную информацию, например:
1. Как изменяется объем продаж по каждой товарной группе в течение 2007 года в Туле.
2. Как изменялся объем продаж в г. Туле по товарной группе ТГ1 за последние три года?
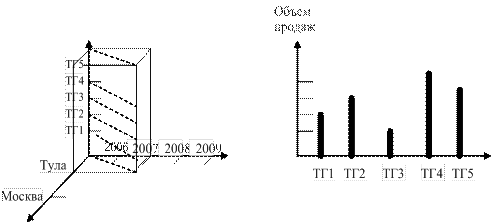
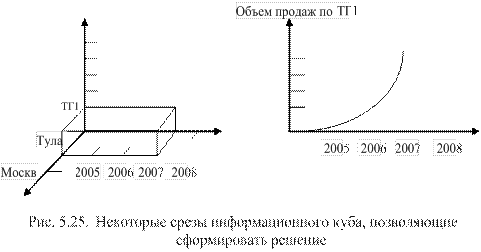
Справа от среза показан график поведения объема продаж, получаемый обычно путем сопряжения OLAP-технологии с табличным процессором помощью табличного процессора. Для наглядного представления информации, сведения из отчетов могут быть экспортированы в сводные таблицы MS Excel, а затем выводиться в виде графиков
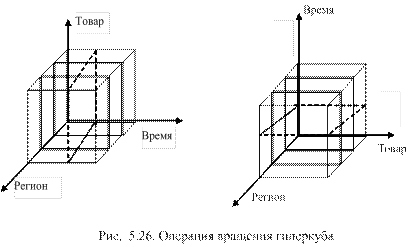
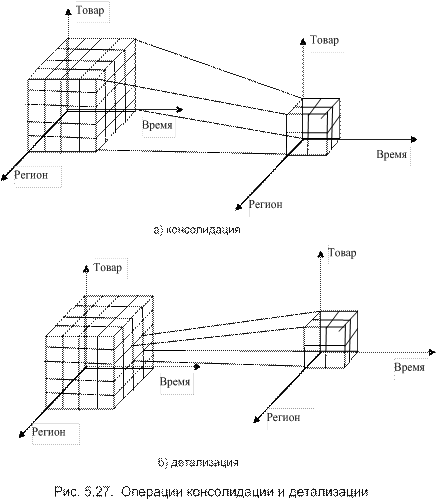
Операция вращения – это изменение расположения измерений в пространстве, что, возможно, облегчит принятие решений. Например, измерение «время», ранее представленное горизонтально, можно повернуть и расположить вертикально, а товар показать горизонтально (см. рис. 5.26 [29]). Возможно, именно эта операция поможет принять правильное решение.
Операции консолидации и детализации предназначены либо для агрегирования данных (обобщения) либо для их детализации. Осуществить эти операции можно благодаря иерархии, установленной среди измерителей. Эти операции иллюстрируются на рис. 5.27.
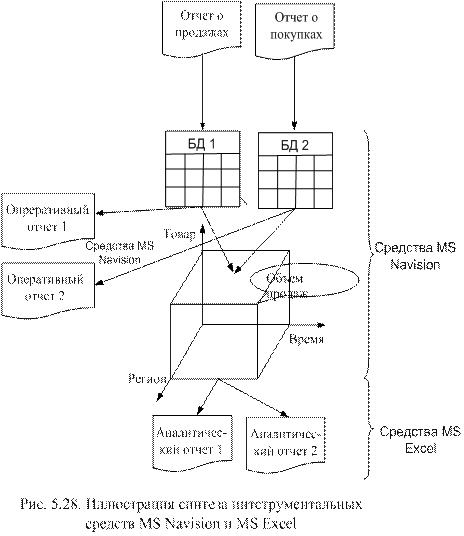
Хранилище данных относится к одному из перспективных направлений развития систем формирования решений. Как правило, современные ERP-системы оснащены средствами их создания. Например, система MS Navision полностью поддерживает идею хранилищ данных, что позволяет получить аналитическую информацию для принятия решений. На рис. 5.28 приведена общая схема использования гиперкубов в среде MS Navision.
Исходные данные, отражающие производственно-хозяйственные операции, вводятся в основную базу данных (БД1, БД2 и т.д.) после чего средствами MS Navision, в соответствии с используемыми измерениями, формируется хранилище данных в виде куба. Основные базы данных используются для оперативной обработки данных и выдачи оперативных отчетов. Аналитические отчеты, необходимые для формирования решений, создаются в виде таблиц или графиков (диаграмм) для чего, в большинстве случаев, подключается MS Excel.
12. Базы знаний и их применение для формирования экономических решений
Базу знаний, как одну из форм информационной модели, следует рассмотреть отдельно из-за ее исключительной перспективности в формировании решений. Будучи предметом изучения специального научного направления, известного под названием инженерия знаний, базы знаний легли в основу создания экспертных систем, одного из продуктов искусственного интеллекта. База знаний – это знания человека (эксперта, специалиста), помещенные в память компьютера в соответствии с некоторой моделью.
Модель, как известно, - это правила или соглашения, выполнение которых позволяет представить некоторую сферу знаний в том виде, которая позволяет использовать формальные (программные) средства для их обработки (получение новых знаний).
Существуют различные модели представления знаний, среди которых наиболее популярными являются:
- продукционные модели (деревья вывода);
- семантические сети (ассоциативные сети),
- фреймы;
- деревья целей;
- нечеткие множества.
Семантическая сеть – это ориентированный граф, вершины (узлы) которого соответствуют понятиям моделируемой предметной области, а дуги – отношениям между ними. В качестве понятий обычно выступают конкретные или абстрактные объекты, а отношений – связи. В отличие от всех других моделей базы знаний могут содержать описание связей в явной форме, указанных с помощью синтаксических, семантических и прагматических отношений. Наиболее часто в семантических сетях используется следующие отношения:
-целое-часть (класс – подкласс, элемент – множество и т.д.);
-функциональная связь, определяемая глаголом (производит, находится, поставляет … и т.д.);
-атрибутивные (иметь значение, иметь свойство);
- логические (И, ИЛИ, НЕТ);
- временные (в течение, раньше, позже…).
Пояснить базу знаний легче в сравнении с базой данных, так как различия между ними нечеткие (размытые). Обратимся к рис. 5.21, на котором представлена информация о поставках, поставщиках и прочее с помощью реляционной базы данных и базы знаний в виде семантической сети.
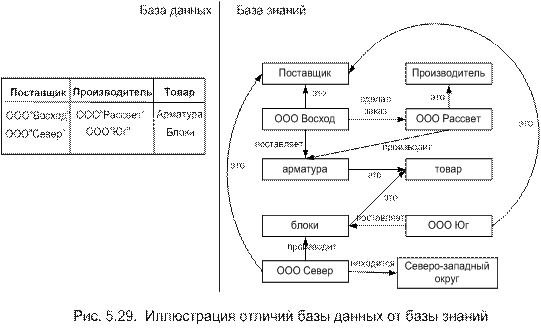
Анализируя базу данных и базу знаний можно заметить, что в базе данных информация более скудная и поэтому с уверенностью трудно ответить на вопрос: Арматура это товар, который производит производитель или это то, что поставляет поставщик? В то же время семантическая сеть прямо указывает на то, что арматура – это товар, который поставляет ООО “Восход”, а производит ее ООО” Рассвет”. Также можно определить поставщика и производителя строительных блоков: блоки поставляет ООО “Юг”, а производит их ООО “Север”. Кроме того, указано, что ООО “Восход” относится к поставщикам, а ООО “Рассвет” к производителям, ООО “Север” находится в Северо-Западном округе.
Таким образом, отличие баз знаний от баз данных состоит в том, что первые содержат связи между объектами в явной форме, тогда как у вторых эти связи скрыты.
Обрабатывается семантическая сеть на основе принципа сопоставления объекта и отношений, указанных в запросе, с объектами и отношениями, имеющимися в семантической сети. Например, если запрос имеет вид "Что производит ООО "Рассвет"? будет выделен тот фрагмент сети, где фигурирует указанный объект ("Рассвет") и отношение "производит". Ответом будет: "ООО "Рассвет" производит арматуру".
С помощью приведенной на рис. 5.29 семантической сети можно получить, кроме прочих, ответы на следующие вопросы:
1. Какие предприятия производят арматуру?
2. Какие предприятия поставляют арматуру?
3. В каком регионе находятся ООО “Север”?
4. Является ли поставщиком ООО “Восход”? и т.д.
Дерево вывода – это множество объединенных правил, отражающих условия выполнения некоторого процесса. Правила представляют собой языковую конструкцию вида:
ЕСЛИ <условие, ct(условия)>, ТО <заключение, ct(заключения)> ct(правила),
где ct(условия) – коэффициент определенности условия;
ct(заключения) - коэффициент определенности заключения;
ct(правила) - коэффициент определенности правила.
Коэффициент, равный 0, указывает на полную неопределенность, а 1 – на полную определенность. В правиле эксперт указывает значения в этом диапазоне.
Множество правил объединяются в дерево вывода. Рассмотрим пример.
Пусть задано два правила.
Правило 1. ЕСЛИ индекс цен возрастет не менее чем на 3% (условие В)
ct(В)
И цены на энергоносители вырастут не более чем на 19%
(условие С), ct(С) = 0,6
ТО акции покупать (заключение А) ct(А) =?, ct(правила 1) =
0,8.
Правило 2. ЕСЛИ ВВП возрастет не менее чем на 1,5% (условие Д) ct(Д)
= 0,4
ИЛИ ставки Центрального банка будут в пределах 12%
(условие Е) ct(Е) = 0,7
ИЛИ объем экспорта возрастет более чем на 5% (условие G)
ct(G) = 0,5
ТО индекс цен возрастет не менее чем на 3%. (заключение В)
ct(В) =?, ct(правила 2) = 0,98.
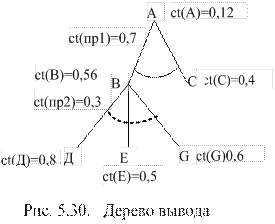
Эти правила объединяются в дерево, представленное на рис. 5.30.
Рассмотрим, каким образом знания такого рода представляются графически, а также как рассчитывается коэффициент определенности заключения. Правило с одним условием вида ЕСЛИ А, ТО В графически представится следующим образом:
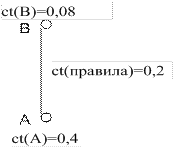
Здесь А - это условие, В - заключение. Далее условимся заключение, получаемое с помощью правила, изображать сверху, а условия - снизу. Число рядом с условием указывает на его определенность, а число рядом с линией - на определенность самого правила.
Условий в правиле может быть несколько, которые связанны между собой союзами И или ИЛИ. Например
ЕСЛИ А и В и С, ТО Е,
ЕСЛИ А или В или С, ТО Е.
Графически эти правила изображаются так, как это показано на рис. 5.31.
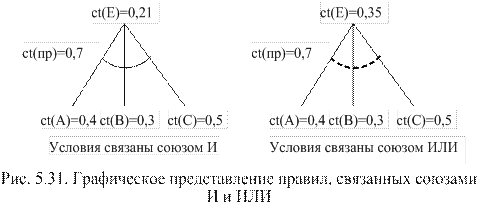
Сплошная или пунктирная дуга указывает на вид объединения условий: союзом И или союзом ИЛИ соответственно. Число, находящееся рядом с дугой (сплошной или пунктирной), указывает на определенность правила, а число рядом с условиями и заключениями - на определенность условий и заключений. Лицо, принимающее решение, условиям (А, В, С), а также правилу присваивает коэффициент определенности от 0 до 1. С помощью специальных формул рассчитывается коэффициент определенности для заключения.
Для простого правила, содержащего лишь одно условие, например, ЕСЛИ Е, ТО С, коэффициент определенности для заключения С рассчитывается так:
ct(C) = ct(E) · ct(правила)
где ct(C) - коэффициент определенности заключения С;
ct(E) - коэффициент определенности условия Е;
сt(правила) - коэффициент определенности правила.
Пример: при ct(E) = 0,4;
ct(правила) = 0,2;
коэффициент определенности заключения равен ct(C)=0,08.
Если в правиле несколько условий, связанных союзом И, то для расчета коэффициента определенности заключения применяется следующая операция:
ЕСЛИ(Е1 и Е2), ТО С.
сt(С) = min(ct(E1), ct(E2)) * сt(правила).
Для правила, в котором присутствуют несколько условий, связанных связкой ИЛИ, применяется операция вида:
ЕСЛИ (Е1 или Е2), ТО С.
ct(С) = max(ct(E1), ct(E2)) * сt(правила).
Пример:
ЕСЛИ (Е1 и Е2),ТО С. При ct(E1)=0,7; ct(E2)=0,6; ct(правила)=0,8;
ct(условия) = min(0,7;0,6)=0,6 коэффициент определенности заключения равен ct(С)=0,6 · 0,8=0,48.
Для заключения А, вывод которого представлен на рис. 5.13, при ct(Д) = 0,8; ct(Е) = 0,5; ct(G) = 0,6; ct(пр1) = 0,7; ct(С) = 0,4; ct(пр2) = 0,3, его коэффициент определенности равен ct(А) = 0,12.
Фреймы – предназначены для представления типовой ситуации. Они объединяют декларативные и процедурные знания. Основная идея фрейма – сосредоточение всей информации об объекте в одной структуре данных. Ниже приведен пример фрейма «Руководитель».





В некоторых слотах фрейма находятся процедуры, автоматически выполняемые при определенных условиях. Условия могут быть следующими:
- реакция на событие «если добавлено»;
- реакция на событие «если удалено»;
- реакция на событие «если изменено».
Во фрейме «Руководитель» указаны процедуры 1, 2, 3, активизируемые при изменении значений слотов. Слот «Заработная плата» связан с фреймом «Зарплата», который активизируется с помощью процедуры 3.Процедуры 4 и 5 включаются при изменении значений слотов «Код налога» и «Налог на дату» (например, вывод результатов пересчета налога).
Дерево целей является дальнейшим совершенствованием целевого управления, развиваемым в нашей стране с семидесятых годов прошлого столетия. В основу его построения положено понятие цели, измерение достижения которой осуществляется с помощью значений соответствующих экономических показателей. Например, уровень достижения цели “Увеличить рентабельность предприятия” можно измерить показателем “Рентабельность” в числовом диапазоне от 0 до 1. Цель “Увеличить рентабельность предприятия с 0,3 до 0,5” в дереве целей указывается именно таким образом.
Допустим, целью является увеличение прибыли, которое обычно достигается за счет увеличения выручки и снижения затрат. Это можно представить графически. Для примера на рис. 5.32 представлена часть дерева целей, на котором с помощью знаков плюс и минус показаны желаемые направления изменения подцелей: В (выручка) - увеличение, З (затраты) - снижение, П (прибыль) - увеличение. Если В = 20 ед., З = 15 ед, то П = 5 ед.
Используется дерево целей для формирования решений следующим образом: допустим, необходимо поднять прибыль до 7 ед. Для этого необходимо установить приоритеты путей в достижении данной цели с помощью коэффициентов α и β. Пользуясь типовыми формулами обратных вычислений, можно определить каковыми должны быть выручка и затраты:
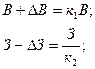
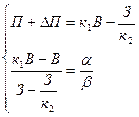
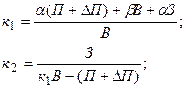
где 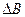 и
и 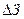 - искомый прирост выручки, и искомое снижение затрат.
- искомый прирост выручки, и искомое снижение затрат.

Подставив исходные данные, при 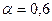 и
и 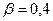 ,получим:
,получим:
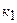 = 1,07;
= 1,07; 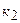 = 1,04;
= 1,04; 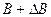 = 21,4;
= 21,4; 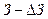 = 14,4. Сделаем проверку правильности полученных результатов:
= 14,4. Сделаем проверку правильности полученных результатов: 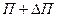 = 21,4 – 14,4 = 7.
= 21,4 – 14,4 = 7.
Дерево целей можно продолжить, если указать из чего состоят выручка и затраты. Это позволит рассчитать управляющие воздействия более детального характера (см. раздел 8.4). Представление знаний в виде дерева целей возможно, если известна цель управления и формулы, согласно которым можно рассчитать уровень достижения каждой из подцелей.
В процессе создания моделей баз знаний специалисты сталкиваются с проблемой отражения и использования нечеткой, то есть неопределенной информации. Представление таких знаний “как высокий человек”, “добросовестный поставщик”, “надежный партнер” и т.д., потребовали нового взгляда на методы их формализации. Задачи, решаемые человеком, в большинстве случаев опираются именно на нечеткие, размытые и неопределенные знания о процессах или событиях.
Нечеткие множества.
Знания человека в большинстве случаев нечеткие. Человек оперирует такими понятиями как высокий, низкий, горячее, холодное, бедный, богатый и т.д. в повседневной производственной практике и в быту. Для того чтобы такого рода знания можно было использовать для формирования решений, в 1965 году Л.Заде предложил теорию нечетких множеств. В основе данной теории лежит понятие функции принадлежности, которая указывает степень принадлежности какого-либо элемента некоторому множеству элементов. Данная функция является субъективной и строится на основании знаний, опыта или ощущений некоторого субъекта к какому-либо объекту, процессу, явлению и т.д.
Вводится U – полное множество, охватывающее все объекты некоторого класса. Нечеткое подмножество F множества U определяется через функцию принадлежности 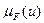 , где
, где 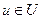 . Эта функция отображает элементы u множества U на множество чисел в отрезке [0,1], которые указывают степень принадлежности этих элементов множеству F.
. Эта функция отображает элементы u множества U на множество чисел в отрезке [0,1], которые указывают степень принадлежности этих элементов множеству F.
Нечеткое множество F можно представить следующим образом:
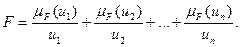
Знак + указывает не на сложение, а на совокупность, а знак / - не деления, а на степень принадлежности.
Рассмотрим пример. Пусть имеется два множества:
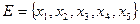 и
и 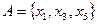 .
.
Степень принадлежности элементов множества Е множеству А можно однозначно представить как: 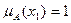 ,
, 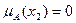 ,
, 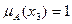 ,
, 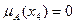 ,
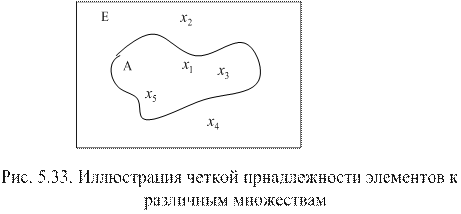
, 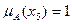 . На рис. 5.33 иллюстрируется четкая (однозначная) принадлежность элементов одного множества другому.
. На рис. 5.33 иллюстрируется четкая (однозначная) принадлежность элементов одного множества другому.
Но принадлежность элементов может характеризоваться и приблизительно, например:
- более или менее принадлежит;
- скорее принадлежит;
- возможно принадлежит и т.д.
Для этого можно воспользоваться функцией принадлежности, которая записывается в данном случае следующим образом:
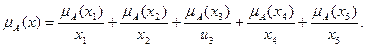
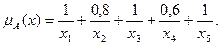
Если функцию принадлежности применить для четких множеств (см. рис. 5.33), то можно получить следующее:
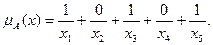
Как правило, функции принадлежности иллюстрируются графически. На рис. 5.34 представлено субъективное понимание возраста с помощью функций принадлежности и графиков.
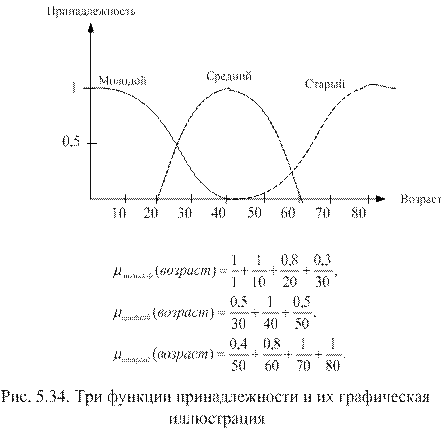
На рис. 5.35 представлено субъективное понимание понятия «низкие процентные ставки».
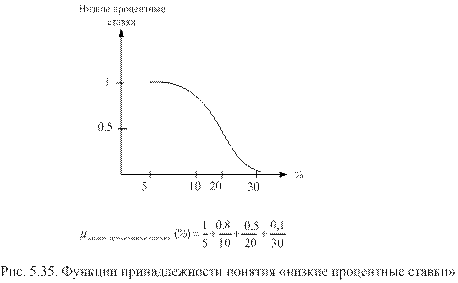
Для того чтобы функцию принадлежности можно было использовать в практических расчетах, вводятся операции пересечения и объединения нечетких множеств.
Операция пересечения нечетких множеств соответствует нахождению минимума значений их функций принадлежности:
|
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 725; Нарушение авторских прав?; Мы поможем в написании вашей работы!