КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Технологии параллельного программирования
|
|
|
|
Классы параллельных систем
История появления параллелизма в архитектуре ЭВМ
Закон Амдала
Закон Амдала
S<= 1/ [f + (1-f)/p]где S - ускорение, f - доля операций, которые нужно выполнить последовательно, p - число процессоров.
Следствие из закона Амдала: для того чтобы ускорить выполнение программы в q раз, необходимо ускорить не менее чем в q раз и не менее чем (1-1/q)-ую часть программы. Следовательно, если нужно ускорить программу в 100 раз по сравнению с ее последовательным вариантом, то необходимо получить не меньшее ускорение на не менее чем 99,99 % кода!
Все современные процессоры используют тот или иной вид параллельной обработки. Изначально эти идеи внедрялись в самых передовых, а потому единичных компьютерах своего времени:
- 1953 г. - IBM 701, 1955 г. - IBM 704: разрядно параллельная память и арифметика, АЛУ с плавающей точкой.
- 1958 г. - IBM 709: независимые процессоры ввода/вывода (т.е. контроллеры ВУ).
- 1961 г. - IBM STRETCH: опережающий просмотр вперед, расслоение памяти на 2 банка.
- 1963 г. - ATLAS: реализована конвейерная обработка данных - конвейер команд.
- 1964 г. - CDC 6600: независимые функциональные устройства.
- 1969 г. - CDC 7600: конвейерные независимые функциональные устройства (8 конвейеров).
- 1974 г. - ALLIAC: матричные процессоры (УУ + матрица из 64 процессоров).
- 1976 г. - CRAY1: векторно-конвейерные процессоры. Введение векторных команд, работающих с целыми массивами независимых данных.
I. Векторно-конвейерные компьютеры (PVP). Имеют MIMD-архитектуру (множество инструкций над множеством данных).
Основные особенности:
- конвейерные функциональные устройства;
- набор векторных инструкций в системе команд;
- зацепление команд (используется как средство ускорения вычислений).
Характерным представителем данного направления является семейство векторно-конвейерных компьютеров CRAY.
Рассмотрим, например, суперкомпьютер CRAY Y-MP C90, имеющий следующие характеристики:
- Максимальная конфигурация - 16 процессоров, время такта - 4,1 нс, что соответствует тактовой частоте почти 250 МГц.
- Разделяемые ресурсы процессора:
- Оперативная память (ОП) разделяется всеми процессорами и секцией ввода/вывода, разделена на множество банков, которые могут работать одновременно.
- Секция ввода/вывода. Компьютер поддерживает три типа каналов с разной скоростью передачи:
Low-Speed Channels - 6 Мбайт/с
High-Speed Channels - 200 Мбайт/с
Very High-Speed Channels - 1800 Мбайт/с
- Секция межпроцессорного взаимодействия содержит регистры и семафоры, предназначенные для передачи данных и управляющей информации.
- Вычислительная секция процессора состоит из:
- регистров (адресных, скалярных, векторных);
- функциональных устройств;
- сети коммуникаций.
- Секция управления.
Команды выбираются из ОП блоками и заносятся в буфера команд.
- Параллельное выполнение программ.
Все основные операции, выполняемые процессором - обращение в память, обработка команд и выполнение инструкций - являются конвейерными.
II. Массивно-параллельные компьютеры с распределенной памятью. Объединяется несколько серийных микропроцессоров, каждый со своей локальной памятью, посредством некоторой коммуникационной среды.
Достоинств у такой архитектуры много: если нужна высокая производительность, то можно добавить еще процессоров; если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.д.
Каждый процессор имеет доступ лишь к своей локальной памяти, а если программе нужно узнать значение переменной, расположенной в памяти другого процессора, то задействуется механизм передачи сообщений. Этот подход позволяет создавать компьютеры, включающие в себя тысячи процессоров.
Но эта архитектура имеет 2 существенных недостатка:
- требуется быстродействующее коммуникационное оборудование, обеспечивающее среду передачи сообщений;
- при создании программ необходимо учитывать топологию системы и специальным образом распределять данные между процессорами, чтобы минимизировать число пересылок и объем пересылаемых данных.
Последнее обстоятельство и мешает широкому внедрению подобных архитектур.
К данному классу можно отнести компьютеры Intel Paragon, IBM SP1, Parsytec, IBM SP2 и CRAY T3D.
Компьютеры Cray T3D и T3E используют единое адресное пространство (общая виртуальная память) (см. рис. 11.1). По аппаратному прерыванию особого случая адресации ОС выполняет пересылку страницы с одного узла на другой. У каждого МП своя локальная память, но единое виртуальное адресное пространство.
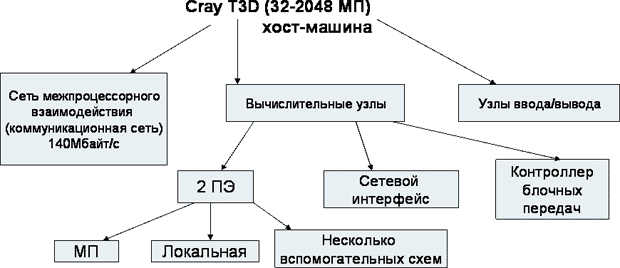
Рис. 11.1. Структура супер-ЭВМ Cray T3D
Факторы, снижающие производительность параллельных компьютеров:
- Закон Амдала.
В табл. 11.1 показано, на какое максимальное ускорение работы программы можно рассчитывать в зависимости от доли последовательных вычислений и числа доступных процессоров.
| Таблица 11.1. | ||||||
| Число ПЭ | Доля последовательных вычислений | |||||
| 50% | 25% | 10% | 5% | 2% | ||
| 1,33 | 1,60 | 1,82 | 1,90 | 1,96 | ||
| 1,78 | 2,91 | 4,71 | 5,93 | 7,02 | ||
| 1,94 | 3,66 | 7,80 | 12,55 | 19,75 | ||
| 1,99 | 3,97 | 9,83 | 19,28 | 45,63 | ||
| 2,00 | 3,99 | 9,96 | 19,82 | 48,83 |
- Время инициализации посылки сообщения (латентность) и время передачи сообщения по сети.
Максимальная скорость передачи достигается на больших сообщениях, когда латентность, возникающая лишь вначале, не столь заметна на фоне непосредственно передачи данных.
- Возможность асинхронной посылки сообщений и вычислений.
Если или аппаратура, или программное обеспечение не поддерживают возможности проводить вычисления на фоне пересылок, то возникнут неизбежные накладные расходы, связанные с ожиданием полного завершения взаимодействия параллельных процессов.
- Неравномерная загрузка всех процессорных элементов.
Если равномерности нет, то часть процессоров будут простаивать, ожидая остальных, хотя в этот момент они могли бы выполнять полезную работу.
- Время ожидания прихода сообщения.
Для его минимизации необходимо, чтобы один процесс отправил требуемые данные как можно раньше, отложив независящую от них работу на потом, а другой процесс выполнил максимум работы, не требующей ожидаемой передачи, прежде чем выходить на точку приема сообщения.
- Реальная производительность одного процессора.
III. Параллельные компьютеры с общей памятью (SMP). Вся оперативная память разделяется между несколькими одинаковыми процессорами. Это снимает проблемы предыдущего класса, но добавляет новые - число процессоров, имеющих доступ к общей памяти, нельзя сделать большим. В данное направление входят многие современные многопроцессорные SMP-компьютеры или, например, отдельные узлы компьютеров HP Exemplar и Sun StarFire.
Основное преимущество таких компьютеров - относительная простота программирования. В ситуации, когда все процессоры имеют одинаково быстрый доступ к общей памяти, вопрос о том, какой процессор какие вычисления будет выполнять, не столь принципиален, и значительная часть вычислительных алгоритмов, разработанных для последовательных компьютеров, может быть ускорена с помощью распараллеливающих и векторных трансляторов. SMP-компьютеры - это наиболее распространенные сейчас параллельные вычислители. Однако общее число процессоров в SMP-системах, как правило, не превышает 16, а их дальнейшее увеличение не дает выигрыша из-за конфликтов при обращении к памяти.
IV. Кластерная архитектура. По такому принципу построены CRAY SV1, HP Exemplar, Sun StarFire, NEC SX-5, последние модели IBM SP2 и другие. Кластерная архитектура представляет собой комбинации предыдущих трех. Из нескольких процессоров (традиционных или векторно-конвейерных) и общей для них памяти формируется вычислительный узел. Если полученной вычислительной мощности не достаточно, то объединяется несколько узлов высокоскоростными каналами. Часто создаются из общедоступных компьютеров на базе Intel и недорогих Ethernet-сетей под управлением операционной системы Linux.
Средства программирования: параллельные расширения и диалекты языков - Fortran, C/C++, ADA и др. Самым крупным достижением в деле создания программного обеспечения была стандартизация интерфейса передачи сообщений MPI (Message Passing Interface). Набор функций этого интерфейса вобрал в себя лучшие черты своих предшественников. Основные достоинства MPI:
- поддержка нескольких режимов передачи данных;
- предусматривает гетерогенные вычисления;
- передача типизированных сообщений;
- построение библиотек - MPICH, LAM MPI;
- наличие вариантов для языков программирования C/C++, Fortran;
- поддерживает коллективные операции: широковещательную передачу, разборку/сборку, операции редукции;
- совместимость с многопоточностью.
|
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 545; Нарушение авторских прав?; Мы поможем в написании вашей работы!