КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Источника информации
|
|
|
|
Лекция 7. Системы сжатия данных для кодирования
Тема. Основы экономного кодирования
Адаптивное руководство
Различные ситуационные модели помогают осознать необходимость гибкого подхода к руководству. Для правильной оценки ситуации руководитель должен знать способности подчиненных (и свои тоже), природу задачи, потребности, полномочия и качество информации.
Руководитель, который строго придерживается одного стиля руководства в силу того, что этот стиль зарекомендовал себя при решении конкретных задач в прошлом, не может рассчитывать, что этот стиль будет также эффективен в других ситуациях и на более высоком посту. Аналогичная проблема может возникнуть при переводе на работу (в подразделение) с неструктуризованной задачей (работой), если на предыдущей работе задача была структуризована.
Приведенный анализ стилей руководства показывает, что руководитель должен уметь применять различные стили руководства в различных ситуациях, чтобы обеспечить эффективность руководства решением различных задач.
Лучшим во всех ситуациях может быть только “адаптивный” стиль, т.е. стиль, ориентированный на реальность.
Эффективным руководителем может считаться только тот руководитель, который может вести себя по-разному, в зависимости от требований реальной ситуации.
Лидерство, как и менеджмент, является искусством. Это подтверждается тем, что не удалось исследователям разработать или обосновать теорию такого стиля. Важным является вывод, сделанный в рамках ситуационного подхода к лидерству, о необходимости уметь применять определенный стиль лидерства в соответствующей ситуации.
Сообщения, передаваемые с использованием систем передачи информации (речь, музыка, телевизионные изображения и т.д.) в большинстве своем предназначены для непосредственного восприятия органами чувств человека и плохо приспособлены для эффективной передачи по каналам связи. Поэтому в процессе передачи, они, как правило, подвергаются кодированию.
Под кодированием понимают преобразование алфавита сообщения A {λi }, (i = 1,2…K) в алфавит некоторых кодовых символов R {xj}, (j = 1,2…N). Обычно размер алфавита кодовых символов dim R{ xj } существенно меньше размера алфавита источника dimA { λi }.
Кодирование сообщений может преследовать различные цели - например засекречивание передаваемой информации. При этом элементарным сообщениям li из алфавита A { λi } ставятся в соответствие последовательности, к примеру, цифр или букв из специальных кодовых таблиц, известных лишь отправителю и получателю информации.
Другим примером кодирования может служить преобразование дискретных сообщений li из одних систем счисления в другие (из десятичной в двоичную, преобразование буквенного алфавита в цифровой и т. д.).
Кодирование в канале, или помехоустойчивое кодирование информации, используется для уменьшения количества ошибок, возникающих при передаче по каналу с помехами.
Наконец, кодирование сообщений может производиться с целью сокращения объема информации и повышения скорости ее передачи. Такое кодирование называют кодированием источника, экономным (эффективным) кодированием или сжатием данных. В этой теме мы рассмотрим именно такое кодирование. Процедуре кодирования обычно предшествуют дискретизация и квантование непрерывного сообщения λ(t), то есть его преобразование в последовательность элементарных дискретных сообщений { λiq }.
Поясним суть процедуры кодирования.
Любое дискретное сообщение li из алфавита источника A { λi } объемом в K символов можно закодировать последовательностью соответствующим образом выбранных кодовых символов xj из алфавита R { xj }.
Например, любое число (а li можно считать числом) можно записать в
заданной системе счисления следующим образом:
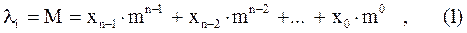
где 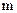 - основание системы счисления;
- основание системы счисления;  - коэффициенты при степенях ;
- коэффициенты при степенях ; 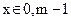 .
.
Например, значение li = M = 59 в восьмеричной (m = 8) системе счисления запишется в виде
M = 59 = 7·81 + 3·80 =738.
Если основание кода m = 2, то
M = 59 = 1×25 + 1×24 + 1×23 + 0×22 + 1×21 + 1×20 = 1110112.
Таким образом, числа 73 и 111011 можно считать, соответственно, восьмеричным и двоичным кодами числа M = 59.
Наибольшее распространение получили двоичные коды, или коды с основанием 2, длякоторых размер алфавита кодовых символов R{ xj } равен двум, 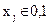 . Двоичные коды содержат только нули и единицы, они очень просто формируются и передаются по каналам связи и, главное, являются внутренним языком компьютеров и без всяких преобразований могут обрабатываться цифровыми средствами. В дальнейшем мы будем рассматривать только двоичные коды.
. Двоичные коды содержат только нули и единицы, они очень просто формируются и передаются по каналам связи и, главное, являются внутренним языком компьютеров и без всяких преобразований могут обрабатываться цифровыми средствами. В дальнейшем мы будем рассматривать только двоичные коды.
Самым простым способом задания кодов являются кодовые таблицы, ставящие в соответствие сообщениям l i соответствующие им коды (табл. 1).
Таблица 1
| Буква li | Число li | Код с основанием 10 | Код с основанием 2 |
| А | |||
| Б | |||
| В | |||
| Г | |||
| Д | |||
| Е | |||
| Ж | |||
| З |
Другим наглядным способом описания кодов является их представление в виде кодового дерева (рис. 1).
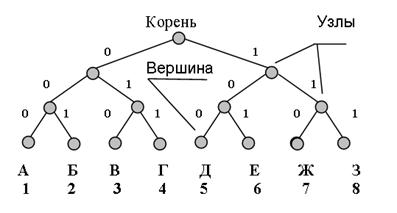 Рис. 1
Рис. 1
Для того, чтобы построить кодовое дерево для данного кода, начиная с некоторой точки - корня кодового дерева - проводятся ветви - 0 или 1. На вершинах кодового дерева находятся буквы алфавита источника, причем каждой букве соответствуют своя вершина и свой путь от корня к вершине. К примеру, букве А соответствует код 000, букве В – 010, букве Е – 101 и т.д.
Код, полученный с использованием кодового дерева, изображенного на рис. 1, является равномерным трехразрядным кодом.
Равномерные коды очень широко используются в силу своей простоты и удобства процедур кодирования-декодирования: каждой букве – одинаковое число бит; при получении заданного числа бит –в кодовой таблице ищется соответствующая буква.
Наряду с равномерными кодами могут применяться и неравномерные коды, когда каждая буква из алфавита источника кодируется различным числом символов, к примеру, А - 10, Б – 110, В – 1110 и т.д.
Кодовое дерево для неравномерного кодирования может выглядеть, например, так, как показано на рис. 2.
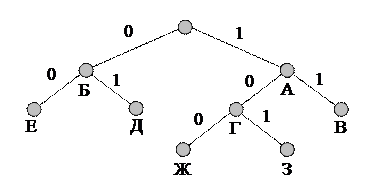 |
Рис. 2.
При использовании этого кода буква А будет кодироваться, как 1, Б - как 0, В – как 11 и т.д. Однако можно заметить, что, закодировав, к примеру, текст АББА = 1001, его нельзя однозначно декодировать, поскольку такой же код дают фразы: ЖА = 1001, АЕА = 1001 и ГД = 1001. Такие коды, не обеспечивающие однозначного декодирования, называются приводимыми, или непрефиксными, кодами и не могут на практике применяться без специальных разделяющих символов. Примером непрефиксных кодов служит азбука Морзе, в которой кроме точек и тире есть специальные символы разделения букв.
Однако можно построить неравномерные неприводимые коды, допускающие однозначное декодирование. Для этого необходимо, чтобы всем буквам алфавита соответствовали лишь вершины кодового дерева (см. Рис. 3). Здесь ни одна кодовая комбинация не является началом другой, более длинной, поэтому неоднозначности декодирования не будет. Такие неравномерные коды называются префиксными.
 |
Рис. 3
Прием и декодирование неравномерных кодов - процедура гораздо более сложная, чем для равномерных. Возникает вопрос, зачем же используются неравномерные коды?
Рассмотрим пример кодирования сообщений li из алфавита объемом K = 8 с помощью произвольного n -разрядного двоичного кода.
Пусть источник сообщения выдает некоторый текст с алфавитом от А до З и одинаковой вероятностью букв Р(li) = 1/8.
Кодирующее устройство кодирует эти буквы равномерным трехразрядным кодом (см. табл. 1).
Определим основные информационные характеристики источника с таким алфавитом:
- энтропия источника 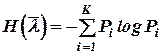 ,
, 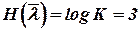 ;
;
- избыточность источника 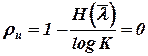 ;
;
- среднее число символов в коде 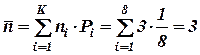 ;
;
- избыточность кода 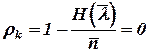 .
.
Таким образом, при кодировании сообщений с равновероятными буквами избыточность выбранного (равномерного) кода оказалась равной нулю.
Пусть теперь вероятности появления в тексте различных букв будут разными (табл. 2).
Таблица 2
| А | Б | В | Г | Д | Е | Ж | З |
| Ра=0.6 | Рб=0.2 | Рв=0.1 | Рг=0.04 | Рд=0.025 | Ре=0.015 | Рж=0.01 | Рз=0.01 |
Энтропия источника 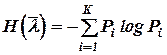 в этом случае, естественно, будет меньшей и составит
в этом случае, естественно, будет меньшей и составит 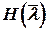 = 1.781.
= 1.781.
Среднее число символов на одно сообщение при использовании того же равномерного трехразрядного кода
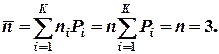
Избыточность кода в этом случае будет
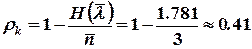 ,
,
или довольно значительной величиной (в среднем 4 символа из 10 не несут никакой информации).
В связи с тем, что при кодировании неравновероятных сообщений равномерные коды обладают большой избыточностью, было предложено использовать неравномерные коды, длительность кодовых комбинаций которых была бы согласована с вероятностью появления различных букв. Такое кодирование называется статистическим.
Неравномерный код при статистическом кодировании выбирают так, чтобы более вероятные буквы передавались с помощью более коротких комбинаций кода, менее вероятные - с помощью более длинных. В результате уменьшается средняя длина кодовой группы в сравнении со случаем равномерного кодирования.
Один способ такого кодирования предложен Хаффменом. Построение кодового дерева неравномерного кода Хаффмена для передачи одного из восьми сообщений li с различными вероятностями иллюстрируется табл. 3.
Таблица 3.
| Буква | Вероятность Рi | Кодовое дерево | Код | ni | ni × Pi |
| А Б В Г Д Е Ж З | 0.6 0.2 0.1 0.04 0.025 0.015 0.01 0.01 | 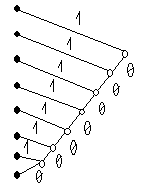
| 0.6 0.4 0.3 0.16 0.125 0.08 0.07 0.08 |
Среднее число символов для такого кода составит
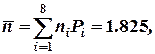
а избыточность кода
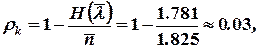
т.е. на порядок меньше, чем при равномерном кодировании.
Другим простейшим способом статистического кодирования является кодирование по методу Шеннона-Фано. Кодирование здесь производится так:
Ø сначала все буквы из алфавита сообщения записывают в порядке убывания их вероятностей;
Ø затем всю совокупность букв разбивают на две примерно равные по сумме вероятностей группы; одной из них (в группе может быть любое число символов, в том числе – один) присваивают символ “1”, другой - “0”;
Ø каждую из этих групп снова разбивают (если это возможно) на две части и каждой из частей присваивают “1” и “0” и т.д.
Процедура кодирования по методу Шеннона-Фано иллюстрируется табл. 4.
Таблица 4
| Буква | Р(li) | I | II | III | IV | V | Kод | ni × Pi |
| А | 0.6 | 0.6 | ||||||
| Б | 0.2 | 0.6 | ||||||
| В | 0.1 | 0.3 | ||||||
| Г | 0.04 | 0.12 | ||||||
| Д | 0.025 | 0.1 | ||||||
| Е | 0.015 | 0.075 | ||||||
| Ж | 0.01 | 0.06 | ||||||
| З | 0.01 | 0.06 |
Для полученного таким образом кода среднее число двоичных символов, приходящихся на одну букву, равно 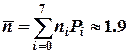 ,
,
а избыточность кода составит 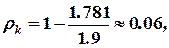
то есть также существенно меньшую величину, чем для равномерного кода.
Можно видеть, что как для кода Хаффмена, так и для кода Шеннона-Фано среднее количество двоичных символов, приходящееся на символ источника, приближается к энтропии источника, но не равно ей. Данный результат представляет собой следствие теоремы кодирования без шума для источника (первой теоремы Шеннона), которая утверждает:
Любой источник можно закодировать двоичной последовательностью при среднем количестве двоичных символов на символ источника li, сколь угодно близком к энтропии, и невозможно добиться средней длины кода, меньшей, чем энтропия H(λ).
Эта теорема устанавливает те границы в компактности представления информации, которых можно достичь при правильном ее кодировании
Цель сжатия данных и типы систем сжатия
Передача и хранение информации требуют больших затрат. Большая часть данных, которые нужно передавать и хранить, не имеет компактное представление. Как правило, эти данные хранятся в форме, обеспечивающей их наиболее простое использование, например: обычные книжные тексты, коды текстовых редакторов (ASCII), двоичные коды данных ЭВМ и т.д. Такое наиболее простое в использовании представление данных требует иногда в сотни раз больше места для хранения и очень широкие полосы частот для передачи. Поэтому сжатие данных – это одно из наиболее актуальных направлений развития современных систем передачи и хранения информации.
Цель сжатия данных - обеспечить компактное представление данных, вырабатываемых источником, для их более экономного сохранения и передачи по каналам связи.
Приведем условную структуру системы сжатия данных:
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 400; Нарушение авторских прав?; Мы поможем в написании вашей работы!