КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Тема № 4. Многофакторная эконометрическая модель
|
|
|
|
Где
Где

 S а1=S ост. / σx√n - 2, Sa0=S ост/√п - 2, Sr =√ (1-r2 )/(n-2)
S а1=S ост. / σx√n - 2, Sa0=S ост/√п - 2, Sr =√ (1-r2 )/(n-2)
S2ост. = Σ(Y – Ŷ)2/ n
Формулы для расчета доверительных интервалов имеют следующий вид:
а0 ± ∆ а0; а1 ± ∆ а1 (3. 15)
Если в границы доверительного интервала попадает 0,т.е. нижняя граница отрицательная, а верхняя положительная, то оцениваемый параметр прини -
мается нулевым, так как он не может одновременно принимать и положительные и отрицательные значения.
Прогнозное значение ypнайдем, подставив в уравнение регрессии
ух = а 0+а1 ·х
соответствующее (прогнозное) значениехр.
Вычислим среднюю ошибку прогноза myp:
 |
 myp = σост. . √1 + 1/ n +((xp – x)2 / Σ(xi – x)2) (3. 16)
myp = σост. . √1 + 1/ n +((xp – x)2 / Σ(xi – x)2) (3. 16)
 σост. = √Σ(y – y x)2/(n – (m – 1)); (3. 17)
σост. = √Σ(y – y x)2/(n – (m – 1)); (3. 17)
тогдадоверительный интервал прогноза:
ур ± ∆ ур; где ∆ ур = tтабл. mур. (3. 18)
Пример2. Вернемся к предыдущему примеру1 и проверим адекватность пос-
троенной модели.Для этого найдем, используя вспомогательную таблицу 2:
Таблица 2.
    у-у у-у
| (у- у)2 | Ŷ- у | (Ŷ- у)2 | у - ŷ | (у-Ŷ)2 |
| -3.3 | 10.89 | -2.7 | 7.29 | -0.6 | 0.36 |
| -2.3 | 5.29 | -2.1 | 4.41 | -0.2 | 0.04 |
| -1.3 | 1.69 | -1.5 | 2.25 | 0.2 | 0.04 |
| -0.3 | 0.09 | -0.9 | 0.81 | 0.6 | 0.36 |
| -0.3 | 0.09 | -0.3 | 0.09 | ||
| 0.7 | 0.49 | 0.3 | 0.09 | 0.4 | 0.16 |
| 0.7 | 0.49 | 0.9 | 0.81 | -0.2 | 0.04 |
| 1.7 | 2.89 | 1.5 | 2.25 | 0.2 | 0.04 |
| 2.7 | 7.29 | 2.1 | 4.41 | 0.6 | 0.36 |
| 1.7 | 2.89 | 2.7 | 7.29 | -1 | |
| Σ | 32.1 | - | 29.7 | - | 2.4 |

 Sост. =√Σ(у – ŷ)²/ n = √ 2.4/10 =0.49
Sост. =√Σ(у – ŷ)²/ n = √ 2.4/10 =0.49
 |
σx = √ 38.5 – (5.5)2 = 2.87
 Тогда расчетные значения t - критерия равны:
Тогда расчетные значения t - критерия равны:
 t β 0 = 4* √(10 – 2) / 0.49 = 23.1; t β 1 = 0.6* (√(10 – 2) /0.49)* 2.87= 9.94
t β 0 = 4* √(10 – 2) / 0.49 = 23.1; t β 1 = 0.6* (√(10 – 2) /0.49)* 2.87= 9.94
По таблице распределения Стьюдента для 10 – 2 = 8 степеней свободы и уровне значимости α = 0.05, найдем критическое значение t– критерия: t табличное равно 2.31.
Так как t расчетное больше t табличного, для каждого параметра, то оба параметра β0 и β1 значимы.
Вычислим коэффициент корреляции:
 r xy =(yx – y. x)/σxσy = ( 45.1 – 5.5*7.3)/2.87*1.792 = = 0.962.
r xy =(yx – y. x)/σxσy = ( 45.1 – 5.5*7.3)/2.87*1.792 = = 0.962.
 |  | ||
так как σy = у2 – (у)2 = 56.5 – 7.32 =1.7917
Вывод: существует достаточно тесная связь между производительностью труда и стажем работы.
и коэффициент детерминации:
R2 = 0,962*0,962 = 0,925
Вывод: 92,5% вариации у объясняется вариацией х.
Проверим значимость коэффициента корреляции используя критерий Стьюдента:
 |  |
 t = r * (n-2)/(1-r2) = 0,962 * (10 – 2)/ (1 – 0,925) = 9,93.
t = r * (n-2)/(1-r2) = 0,962 * (10 – 2)/ (1 – 0,925) = 9,93.
Вывод: Так как расчетное значение больше критического значения, то коэффициент корреляции значим.
Таким образом, построенная модель в целом адекватна, и выводы, полученные по результатам малой выборки, можно с достаточной вероятностью распространить на всю гипотетическую генеральную совокупность.
Из модели, следует, что возрастание на 1 год стажа рабочего приводит к увеличению им дневной выработкм в среднем на 0.6 изделия.
Вычислив коэффициент эластичности
 Э = β1 х / у = 0,6*5,5/ 7.3 = 0,45 сделаем вывод: с возрастанием стажа работы на 1% следует ожидать повышение производительности труда в среднем на 0,45%.
Э = β1 х / у = 0,6*5,5/ 7.3 = 0,45 сделаем вывод: с возрастанием стажа работы на 1% следует ожидать повышение производительности труда в среднем на 0,45%.
Анализируя остатки модели можно сделать ряд практических выводов, в частности определить наиболее передовых (наибольшие положительные остатки) и отстающих (наибольшие отрицательные остатки) рабочих.
Как известно, все явления складываются под воздействием не одного, а нескольких факторов. Между факторами существуют сложные взаимосвязи, поэтому их влияние комплексное и его нельзя рассматривать как простую сумму изолированных влияний. В этом случае используют многофакторную економетрическую модель. Ее анализ удобно проводить используя элементы матричной алгебры. При этом объект исследования представляют регрессионной функцией:
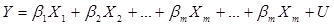 , (4.1)
, (4.1)
где Y – регрессанд, X1, X2, …, Xm – регрессоры, U – случайные переменные.
Для реализации случайных переменных Yt и Ut уравнение (4.1) примет вид:
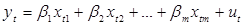 (4.2)
(4.2)
Чтобы статистически оценить параметры регрессионной модели, необходимы ряды данных длиной п для регрессандов (Y) и для каждого из К регрессоров (переменных Х). При этом длина рядов наблюдений должна быть больше количества регрессоров (п>m). Длина временных рядов образует опорный (базовый) период. Для наблюдаемых в моменты времени t =1, 2, …, п значений можно записать п уравнений регрессии:
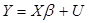 , (4.3)
, (4.3)
где
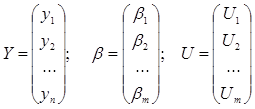 (4.4)
(4.4)
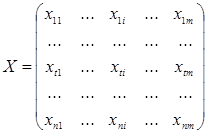
Вектор наблюдений Y и матрица наблюдений Х образуют матрицу данных D.
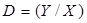 (4.5)
(4.5)
Она содержит все данные, необходимые для статистической оценки вектора коэффициентов регрессии 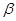 и прочих параметров модели.
и прочих параметров модели.
Метод оценки регрессионных коэффициентов βm, в котором применяется сумма квадратов ошибок как мера качества адаптации эмпирической функции к наблюдаемым данным, называется одношаговым методом наименьших квадратов (1-МНК). Ошибка уравнения для t-го наблюдения равна:
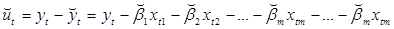 (4.6)
(4.6)
Тогда сумма квадратов ошибок 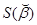 для Т наблюдений имеет вид:
для Т наблюдений имеет вид:
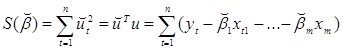 (4.7)
(4.7)
или
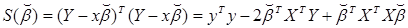
Дифференцируя по 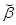 , получим, с учетом необходимого условия существования минимума (
, получим, с учетом необходимого условия существования минимума (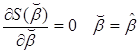 ):
):
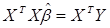 , (4.8)
, (4.8)
где 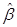 - вектор коэффициентов регрессии минимизирующий
- вектор коэффициентов регрессии минимизирующий 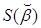 ; выражение (4.8) называется системой нормальных уравнений. Домножив слева равенство (4.8) на обратную матрицу
; выражение (4.8) называется системой нормальных уравнений. Домножив слева равенство (4.8) на обратную матрицу 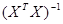 , получим формулу для вычисления вектора 1-МНК оценок
, получим формулу для вычисления вектора 1-МНК оценок 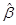 для :
для :
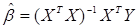 (4.9)
(4.9)
Порядок расчетов по формуле (4.9) может быть следующим:
1. Вычислить 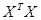 ;
;
2. Определить вектор 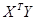 ;
;
3. Найти матрицу обратную матрице ;
4. Рассчитать как результат произведения на .
Подставив в оцениваемое уравнение, получим оцененную с помощью 1-МНК эмпирическую регрессионную функцию:
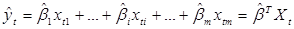 (4.10)
(4.10)
Эмпирический коэффициент βi определяет количество единиц, на которое изменится 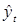 при изменении Xi на единицу при прочих равных условиях.
при изменении Xi на единицу при прочих равных условиях.
Все n значений – прогноз величины Y (величины ее математического ожидания) образуют вектор Ŷ:
Ŷ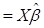 (4.11)
(4.11)
Тогда 1-МНК оценщик 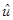 вектора возмущений u имеет вид:
вектора возмущений u имеет вид:
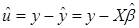 (4.12)
(4.12)
Важной характеристикой регрессионной модели является дисперсия возмущений 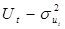 . Ее величина должна быть как можно меньше. 1-МНК оценщик для
. Ее величина должна быть как можно меньше. 1-МНК оценщик для  можно вычислить по одной из формул:
можно вычислить по одной из формул:
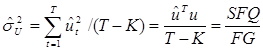 (4.13)
(4.13)
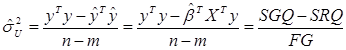 (4.14)
(4.14)
где 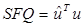 - сумма квадратов ошибок;
- сумма квадратов ошибок; 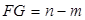 - количество степеней свободы;
- количество степеней свободы; 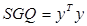 - сумма общих квадратов.
- сумма общих квадратов.
Для t – тестирования гипотез по отдельным коэффициентам регрессии и их линейным комбинациям необходимо знать элементы ковариационной матрицы. Ковариационная матрица для 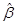 , оцененная методом 1-МНК, может быть представлена следующим образом:
, оцененная методом 1-МНК, может быть представлена следующим образом:
 (4.15)
(4.15)
На главной диагонали оцененной ковариационной матрицы 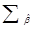 , i-ый элемент
, i-ый элемент 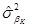 является 1-МНК оценщиком дисперсии i-го коэффициента βi, а элемент
является 1-МНК оценщиком дисперсии i-го коэффициента βi, а элемент 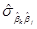 , расположенный вне диагонали, является 1-МНК оценщиком ковариации между
, расположенный вне диагонали, является 1-МНК оценщиком ковариации между  и
и 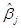 . Наиболее желательными являются, по возможности, узкие доверительные и прогнозные интервалы. И, как следствие, меньшие оцененные дисперсии и ковариации.
. Наиболее желательными являются, по возможности, узкие доверительные и прогнозные интервалы. И, как следствие, меньшие оцененные дисперсии и ковариации.
 Средние коэффициенты эластичности,для линейной регрессии, расчитыва-
Средние коэффициенты эластичности,для линейной регрессии, расчитыва-
ютсяпо формуле:
Э yxj = аj xj / y (4.16)
Для измерения тесноты связи между двумя из рассматриваемых переменных
(без учета их взаимодействия с другими переменными) применяются парные коэффициенты корреляции:
| | |  | | |
r y x1 = (x1y –x1 y) /σ x1 σy; r y x2 = (x2y – x2 y) /σ x2 σy;


r x1 x2 = (x1 x2 – x1 x2) /σ x1 σ x2 . (4.17)
где


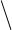

 σ x1 = x1 2 - (x1)2
σ x1 = x1 2 - (x1)2
 |
σ x2 = x2 2 – (x2) 2
 |
σy = y 2 – (y)2
Так как в реальных условиях все переменные, как правило,взаимосвязаны, то на значение коэффициента корреляции частично влияют другие переменные.В связи с этим возникает необходимость исследовать частную корреляцию между переменными при исключении (элиминировании) влияния одной или нескольких переменных. Теснота этой связи определяется частными коэффициентами корреляции.между переменными Xi и Xj при фиксированных значениях остальных m - 2 переменных по формуле:
 |
r xixj (x 1,x 2, …, x m) = - Аij / A ii * Ajj,
где A ii и Ajj -алгебраические дополнения элементов rii и rjj матрицы парных коэффициентов корреляции ∆ r 11 или по рекуррентной формуле:
r xixj (x 1,x 2,…,x i-1,x i+1, …, x j-1, x j+1, …,x m) =
rxixj, x 1,x 2,x i-1,x i+1, …, x m -1 - rxixm (x 1,x 2, …, x m –1)rxj x m(x 1,x2,…,xm -1)


(1 –r2xixm(x 1,x 2, …, x m –1)) (1 –r2xj x m(x 1,x2,…,xm -1)) (4.18)
Частные коэффициенты (индексы) корреляции, измеряющие степень и влияние на у фактора хi при неизменом уровне других факторов, можно определить по рекуррентной формуле:
r yxi (x 1,x 2,x i-1,x i+1, …, x m) =
 ryxi,x1,x2,x i-1,x i+1,…, xm -1 - ryxm (x 1,x 2, …, x m –1)rxi x m(x1,x2,…,xm-1)
ryxi,x1,x2,x i-1,x i+1,…, xm -1 - ryxm (x 1,x 2, …, x m –1)rxi x m(x1,x2,…,xm-1)

(1 –r2yxm(x 1,x 2, …, x m –1)) (1 –r2xi x m(x 1,x2,…,xm -1))
В зависимости от количества переменных, влияние которых исключается, частные коэффициенты корреляции могут быть различного порядка: при исключе-
нии влияния одной переменной получим частный коэффициент корреляции первого порядка; при исключении влияния двух переменных - частный коэф-
фициент корреляции второго порядка и т. д.
Для двухфакторной модели частный коэффициент корреляции первого порядка между признаками х1 и у при исключении признака х2 вычисляют по формуле:
ry x 1 - ryx 2 rx 1x2
r yx1 (x 2) = _______________________


 (1 – r2yx 2) (1 – r2x1x2)
(1 – r2yx 2) (1 – r2x1x2)
Для двухфакторной модели частный коэффициент корреляциипервого порядка между признаками х2 и у при исключении признака х1 вычисляют по формуле:
ry x 2 - ryx 1 rx 1x2
r yx2 (x 1) = ________________________



(1 – r2yx 1) (1 – r2x1x2)
Для двухфакторной модели частный коэффициент корреляции первого порядка между признаками х1 и х2 при исключении влияния результативного признака у вычисляют по формуле:
rх1 x 2 - ryx 1 rуx

r х2x1 (у) = _______________________
(1 – r2yx 1) (1 – r2уx2),
где ryxi – парные коэффициенты корреляции между соответствующими признаками.Очевидно, что коэффициент корреляции r между остатками будет отражать тесноту частной корреляции между переменными хi и хj при исключении влияния остальных переменных. Можно показать, что коэффициент корреляции r между остатками равен частному коэффициенту корреляции rxixj. Частный коэффициент корреляции, как и парный коэффициент rij, может принимать значения от –1 до 1 и его значимость оценивают так же, как и обычного коэффициента корреляции r, но при этом полагают df = n – m –2.
Изучение парных и частных коэффициентов корреляции позволяет отобрать наиболее существенные, значимые факторы. Тесноту совместного влияния фак
торов на результат оценивает коэффициент (индекс)множественной корреля-
ции R yx1x2,…,xm:
 |
R yx1x2,…,xm = 1-σ2y ост. /σ2y
Значение коэффициента (индекса) множественной корреляции лежит в пределах от 0 до 1 и должно быть больше или равно максимальному парному индексу корреляции r yxi.
В случае линейной двухфакторной связи совокупный коэффициент множественной корреляции можно найти следующим образом:
 | |||
 |
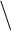 R yx1x2 = (r2y x1+ r2y x2 – 2 r y x1 ry x2 rx1 x2 ) / (1 – r2x1 x2)
R yx1x2 = (r2y x1+ r2y x2 – 2 r y x1 ry x2 rx1 x2 ) / (1 – r2x1 x2)
Индекс множественной корреляции для уравнения в стандартизованном виде можно записать следующим образом:
 |
R yx1x2,…,xm = Σ βι ryxι
При линейной зависимости коэффициент множественной корреляции можно, также, определить через матрицу парных коэффициентов корреляции:
 |
R yx1x2,…,xm = 1- ∆ґ /∆ґ11,
где
 1 ry x1 ry x2 … ry x m
1 ry x1 ry x2 … ry x m
∆ r = ry x1 1 rx1x2 … rx1 x m
ry x 2 rx2x1 1 … rx2 x m
--------------------------------------------------------
ry x m rxm x1 rxm x2 … 1
- определитель матрицы парных коэффициентов корреляции;

 1 rx1 x2 rx1x3 … rx1x m
1 rx1 x2 rx1x3 … rx1x m
∆ r 11 = rx2 x1 1 rx2x3 … rx2 x m
rx3 x 1 rx3x2 1 … rx3 x m
--------------------------------------------------------
rx m x1 rxm x2 rxm x3 … 1
- определитель матрицы межфакторной корреляции.
Регрессионное уравнение оценено тем лучше, чем больше при прочих равных условиях R2.При вычислении R2 наблюдается следующая тенденция:R2 (c m+1 регрессорами) > R2 (c m регрессорами).Следовательно, уравнение с относительно большим числом регрессоров, как правило, будут давать лучшие результаты, чем с малым их количеством. Однако с каждым дополнительным регрессором теряется одна степень свободы, поэтому в статистическом отношении наличие дополнительного регрессора может быть не всегда желательным. Для того, чтобы определить на 
какую величину уменьшается R2 если i-й регрессор будет исключен, используют частный коэффициент детерминации 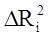 .
.
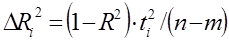 [2.5]
[2.5]
где ti- t – статистика для i-го коэффициента. Используя скорректированные коэффициенты детерминации можно определить изменение R2, вызванное дополнительным регрессором. Наиболее часто используются скорректированные коэффициенты по Тэйлу:
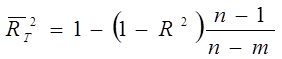 [2.6]
[2.6]
и по Амемии:
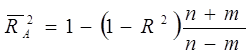 [2.7]
[2.7]
Совокупный коэффициент (индекс) множественной детерминации опреде
ляет только качество выравнивания по уравнению регрессии. Так как многофакторный регрессионный анализ оперирует случайными наблюдениями, и необязательно распределенными по многомерному нормальному закону (этому закону должны подчиняться отклонения фактических значений регрессанда от расчетных), то показатели множественной регрессии и корреляции сами могут оказаться подверженными действию случайных факторов. Поэтому только после проверки адекватности уравнения в целом, оно может использоваться для дальнейшего экономического анализа.
Общая оценка адекватности уравнения может быть получена с помощью дисперсионного F – критерия Фишера:
F = R²(n-m-1) / (1- R²). m, или F = σ ²у .(n-m-1) / σ ²ост.. m
где m -число факторов.(число параметров р = m + 1)
Полученное значение F– критерия (Fрасч.) сравнивают с табличным для принятого уровня значимости и чисел степеней свободы k1 = m и k2 = n-m-1.
Если Fрасч. > Fтабл ., то уравнение регрессии статистически значимо, т.е.
доля вариации, обусловленная регрессией, намного превышает случайную ошибку.
Принято считать, что уравнение регрессии пригодно для практического использования в том случае, если Fрасч. > Fтабл не менее чем в 4 раза.
Частный F – критерий Фишера оценивает статистическую значимость присутствия каждого из факторов в уравнении регрессии и определяется по формуле:
R2 yx1x2,…,xm -r 2yxi (x 1,x 2,x i-1,x i+1, …, x m). (n-m-1)
Fi част. =-------------------------------------------------------------------------,
R2 yx1x2,…,xm
Или
Fi =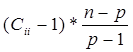 , где
, где
Сii -i –ый диагональный элемент матрицы С обратной к корреляционной матрице R:
C = R-1, где R = (XT.X)/(n –1)
Для оценки значимости коэффициентов регрессии при линейной зависимости используют t - критерий Стьюдента при n – (m + 1) степенях свободы:
 | |
ta1 = a1σx1 * √1-r2x1x2 * √n-m-1 / σy √1-R2yx1x2
| | ||||
|
ta2= a2σx2 * √1-r2x1x2 * √n-m-1 / σy√1-R2yx1x2
|
 tRyx1x2 = Ryx1x2 * √n-m-1 / √1-R2yx1x2
tRyx1x2 = Ryx1x2 * √n-m-1 / √1-R2yx1x2
Если в уравнении все коэффициенты регрессии значимы, то данное урав -
нение признают окончательным и применяют в качестве модели изучаемого показателя для последующего анализа.
Оценку значимости коеффициентов регрессии с помощью t – критерия
используют, также, для отбора существенных (информативных) факторов при многошаговом регрессионном анализе. Он заключается в том, что после оценки значимости всех коэффициентов регрессии из модели исключают тот фактор, коэффициент при котором незначим и имеет наименьшее значение критерия. Затем строится уравнение регрессии без исключенного фактора, и снова проводится оценка адекватности уравнения и значимости коэфициентов регрессии. Процесс длится до тех пор, пока все коэффициенты регрессии не окажутся значимыми, что свидетельствует о наличии в регрессионной модели только существенных факторов.В некоторых случаях расчетное значение t расч. находится вблизи tтабл., поэтому с точки зрения содержательности модели такой фактор можно оставить для последующей проверки его значимости в сочетании с другим набором факторов.
При построении уравнения множественной регрессии может возникнуть проблемма мультиколлинеарности факторов, их тесной линейной связи.
Наиболее полно исследовать мультиколлинеарность можно с помощью алгоритма ФАРРАРА-ГЛОБЕРА.Он содержит три вида статистических критериев с помощью которых проверяется мультиколлинеарность соответственно: 1 ). всего массива объясняющих переменных (хи-квадрат);2). каждой объясняющей переменной с остальными объясняющими переменными (F- критерий); 3).каждой пары объясняющих переменных (t -критерий).
АЛГОРИТМ ФАРРАРА –ГЛОБЕРА состоит из следующих шагов:
ШАГ 1. НОРМАЛИЗОВАТЬ ПЕРЕМЕННЫЕ ИСПОЛЬЗУЯ ФОРМУЛУ:
|
Х* = (Х – Х)/ σк
ШАГ 2. НАЙТИ КОРРЕЛЯЦИОННУЮ МАТРИЦУ R:
R = X* ′ ● X*
ШАГ 3. ОПРЕДЕЛИТЬ КРИТЕРИЙ χ² = - [ n – 1 – 1/6(2m+5)] · ln |R|,
ГДЕ |R| -ОПРЕДЕЛИТЕЛЬ КОРРЕЛЯЦИОННОЙ МАТРИЦЫ.
ЗНАЧЕНИЕ ЭТОГО КРИТЕРИЯ СРАВНИВАЕТСЯ С χ² табл. ПРИ ½(р-1)(р-2) СТЕПЕНИ СВОБОДЫ И УРОВНЮ ЗНАЧИМОСТИ α. ЕСЛИ χ²факт.<χ²табл., ТО В МАССИВЕ НЕЗАВИСИМЫХ ПЕРЕМЕННЫХ М УЛЬТИКОЛЛИНЕАРНО
СТЬ ОТСУТСТВУЕТ.
ШАГ 4. ОПРЕДЕЛИТЬ МАТРИЦУ С ОБРАТНУЮ К R.
C = R ¯ ¹ = (X*´X*)¯ ¹
ШАГ 5. РАССЧИТАТЬ F -КРИТЕРИИ:
Fk = (Ckk - 1) ((n - р) / (р- 1)),
ГДЕ Ckk – ДИАГОНАЛЬНЫЕ ЭЛЕМЕНТЫ МАТРИЦЫ С.
ФАКТИЧЕСКИЕ ЗНАЧЕНИЯ КРИТЕРИЕВ Fk СРАВНИВАЮТСЯ С ТАБЛИЧНЫМИ ПРИ р-1 И n-р СТЕПЕНЕЙ СВОБОДЫ И УРОВНЮ ЗНАЧИМОСТИ α.
ЕСЛИ Fk факт. > Fтабл., ТО СООТВЕТСТВУЮЩАЯ k-Я ОБЪЯСНЯЮЩАЯ ПЕРЕМЕННАЯ МУЛЬТИКОЛЛИНЕАРНА С ДРУГИМИ.
КОЭФФИЦИЕНТ ДЕТЕРМИНАЦИИ ДЛЯ k–ОЙ ПЕРЕМЕННОЙ ВЫЧИСЛЯЕТСЯ ПО ФОРМУЛЕ:
R²k = 1 – 1/Сkk.
ШАГ 6. НАЙТИ ЧАСТНЫЕ КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ:
 |
rki = - Скj / √ Скк· Cjj,
ГДЕ Скj -ЭЛЕМЕНТ МАТРИЦЫ С РАСПОЛОЖЕННЫЙ В к – ОЙ СТРОКЕ И j –ОМ СТОЛБЦЕ, Скк И С jj – ДИАГОНАЛЬНЫЕ ЭЛЕМЕНТЫ МАТРИЦЫ С.
ШАГ 7. РАССЧИТАТЬ t – КРИТЕРИИ:
|  |
tkj = (rki *√ n – р)/√1-r²ki.
ФАКТИЧЕСКИЕ ЗНАЧЕНИЯ tkj СРАВНИВАЮТСЯ С ТАБЛИЧНЫМИ ПРИ n-р СТЕПЕНЕЙ СВОБОДЫ И УРОВНЕ ЗНАЧИМОСТИ α.ЕСЛИ tkj факт. > t табл., ТО МЕЖДУ ПЕРЕМЕННЫМИ Хк И Хj СУЩЕСТВУЕТ МУЛЬТИКОЛЛИНЕАРНОСТЬ.
Для устранения или уменьшения мультиколлинеарности используется ряд методов.Самый простой из них состоит в том, что из двух объясняющих переменных, имеющих высокий коэффициент корреляции(больше 0,8),
одну из переменных исключают из рассмотрения.При этом, какую переменную оставить,а какую удалить из анализа, решают в первую очередь на основании экономических соображений.Если с экономической точки зрения ни одной из переменных нельзя отдать предпочтение, то оставляют ту из двух переменных, которая имеет больший коэффициент корреляции с зависимой переменной.
Другой метод устранения или уменьшения мультиколлинеарности заключается в переходе от несмещенных оценок, определяемых по методу 1-МНК, к смещенным оценкам, обладающим, однако, меньшим рассеянием относительно оцениваемого параметра.Так, например, при использовании “ридж-регрессии” или “ гребневой регрессии “вместо несмещенных оценок рассматривают смещенные оценки задаваемые вектором
β=(ХтХ+τEp+1)¯¹ X т У,
где τ – некоторое положительное число, называемое “ гребнем “ или “ хребтом “, Ep+1- единичная матрица p+1 – го порядка.Добавление τ к диагональным элементам матрицы ХтХ делает оценки параметров модели смещенными, но при этом увеличивается определитель матрицы системы нормальных уравнений.Вместо ХтХ он будет равен ХтХ+τEp+ 1 Таким образом, становится возможным исключение мультиколлинеарности в случае, когда определитель ХтХ близок к нулю.
Возможен, также, переход к новым переменным, представляющим линейные комбинации исходных.В качестве таких переменных берут, например главные компоненты вектора исходных объясняющих переменных и рассматривают регрессию на главных компонентах.
Еще одним из возможных методов устранения или уменьшения мультиколлинеарности является использование пошаговых процедур отбора наиболее информативных переменных.Например,на первом шаге рассматривается лишь одна переменная, имеющая с переменной У наибольший коэффициент детерминации.На втором шаге включается в регрессию новая переменная, которая вместе с первоначально отобранной образует пару переменных, имеющую с У наиболее высокий (скорректированный) коэффициент детерминации, и т. д. Процедура введения новых переменных продолжается до тех пор, пока будет увеличиваться соответствующий (скорректированный) коэффициент корреляции.
На основе коэффициентов регрессии невозможно указать какой из фактор-ных признаков оказывает наибольшее влияние на результативный признак у, так как они не сопоставимы между собой, поскольку измеряются разными единицами.На их основе невозможно также установить в развитии каких фак-
торных признаков заложены наиболее крупные резервы изменения регрессан
да у, потому что в них не учтена вариация факторных признаков.
Для ответа на выше перечисленные вопросы построим уравнение множественной регрессии в стандартизированном виде:
ty = βıtx ı + β2t x 2 + … + βptx p
где
 ty = у – у /σу, tхi = (xi – xi) /σxi - стандартизованные переменные, βi –
ty = у – у /σу, tхi = (xi – xi) /σxi - стандартизованные переменные, βi –
стандартизованные коэффициенты.
Стандартизованные коэффициенты регрессии (β - коэффициенты) опре-
деляются из следующей системы:
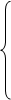 β1 + β2 rx1x2 + β3 rx1x3 + … + βp rx1xp = ryx1
β1 + β2 rx1x2 + β3 rx1x3 + … + βp rx1xp = ryx1
β1 rx2x1 + β2 + β3 rx2x3 + … + βprx2xp = ryx2
…………………………………………………..
β1 rxpx1 + β2 rxpx2 +β3 rxpx3 + … + βp = ryxp
и показывают на какую часть среднего квадратичного отклонения изменяется регрессанд у (результативный признак у) с изменением соответствующего факторного признака на величину его среднего квадратичного отклонения. С помощью β – коэффициентов определяют факторы в развитии которых заложены наиболее крупные резервы изучаемого показателя.
Так как связь коэффициентов множественной регрессии ai со стандартными коэффициентами βi (β – коэффициентами) описывается соотношениями:
| | | |
ai = βiσу / σxi; a0 = y - b1 x1 - b2 x2 - … - bp xp,
то β - коэффициенты можно также найти по формулам:
βi = ai σxi/ σу,
Средние коэффициенты эластичности для линейной регрессии расчитываются по формуле:
Э yxj = аj xj /y
Частные коэффициенты эластичности вычисляются по формуле:
Э yxj = аj xj /ŷxi (x1,x2,xi-1, xi+1,…,xm)
и показывают на сколько процентов в среднем изменяется анализируемый показатель с изменением на 1% сответствующего фактора при фиксированном положении других факторов.
С помощью частных коэффициентов эластичности можно определить фак-
тор оказывающий наибольшее влияние на регрессанд у (без учета различия в степени варьирования входящих в уравнение факторов, что, в отличие от β – коэффициентов не дает возможности определить факторы в развитии которых заложены наиболее крупные резервы улучшения изучаемого показателя).
Для определения доли вклада анализируемого фактора в суммарное влияние всех факторов вычисляют∆і - коэффициентпо формуле:
∆і = βіrі/R²
С помощью ∆і – коэффициентов можно определиться фактор, развитием которого можно обеспечить наибольшую долю прироста регрессанда у.
Таким образом на основании частных коэффициентов эластичности Э yxj,βi -, ∆і - коэффициентов можно судить о резервах роста исследуемого показателя у (регрессанда у) которые заложены в том или ином факторе xi.
ПРОСТРАНСТВЕННАЯ КОРРЕЛЯЦИЯ ВОЗМУЩЕНИЙ (Гетероскедастичность остатков).
Методы случайных выборок, приобретающие все большее значение в эмпирических исследованиях, связаны с обработкой больших объёмов пространственных данных. При работе с набором таких данных могут проявляться пространственные связи в виде пространственных корреляций, возмущений Они нарушают предпосылку классической регрессионной модели и отрицательно сказываются на 1-МНК оценщике. Эти последствия отсутствуют если пространственная корреляция возмущений является равновеликой.
ОПРЕДЕЛЕНИЕ: Возмущение 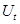 в регрессионном уравнении проявляют равновеликую пространственную корреляцию, если:
в регрессионном уравнении проявляют равновеликую пространственную корреляцию, если:
1. 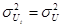 для t=1,2,…,T-условие гомоскедастичности.
для t=1,2,…,T-условие гомоскедастичности.
2. 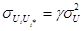 где
где 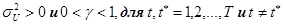
Выполнение предпосылки с равновеликой пространственной корреляции приводит к обобщённой модели с ковариационной матрицей:
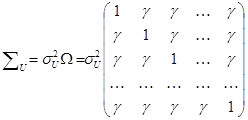
При этом обычные 1-МНК оценки , рассчитанные на основе исходной матрицы данных, идентичны оценкам Эйткена 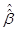 .
.
ОПРЕДЕЛЕНИЕ: Гетероскедастичность возмущений имеет место, если существует хотя бы один 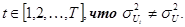
Пути устранения отрицательных последствий при гетероскедастичности возмущений такие же как и при автокорреляции:
1. Стремится к свободной от гетероскедастичности спецификации модели:
2. Провести оценивание по методу Эйткена.
При диагностике на гетероскедастичность используются различные статистические тесты. Наиболее распространённым и простым является тест Гольдфельда- Квандта.
При тесте Г-Ф нулевая гипотеза имеет вид:
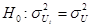 для t=(1,2,…,T)
для t=(1,2,…,T)
Альтернативная:
Существует по меньшей мере один 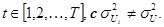
В первом варианте теста Г-Ф на гетероскедастичность возмущений делят все T наблюдений на две группы, так, что в первую входят 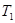 наблюдений с предположительно меньшей дисперсией, вторую группу образуют
наблюдений с предположительно меньшей дисперсией, вторую группу образуют 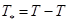 наблюдений с предположительно большей дисперсией. Тем самым матрица будет разделена на два блока:
наблюдений с предположительно большей дисперсией. Тем самым матрица будет разделена на два блока:
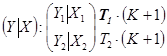
в каждом из которых проводят оценку по 1-МНК. В качестве тест статистики используют величину:
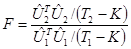
где 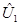 представляет собой вектор остатков регрессии в блоке оцененный 1-МНК. Тест статистика имеет распределение с T2-K и T1-K степенями свободы.
представляет собой вектор остатков регрессии в блоке оцененный 1-МНК. Тест статистика имеет распределение с T2-K и T1-K степенями свободы.
Нулевая гипотеза отклоняется, если: 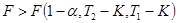
Тест Г-Ф может быть применён если 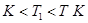 и матрицы X2 обладают полным рангом.
и матрицы X2 обладают полным рангом.
Чувствительность теста Г-Ф может быть повышена, если при разделении на группы исключить m средних наблюдений (второй вариант теста).
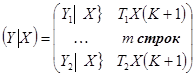
При T=30 рекомендуется исключать 8 строк, при T=60-16 строк.
Исходная матрица данных при гетероскедастичность может быть преобразована следующим образом:
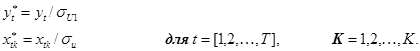
При этих вычислениях используется матрица преобразования:
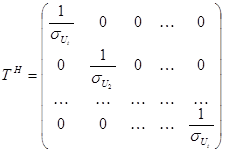
поэтому вспомогательная модель для периода t будет следующая:
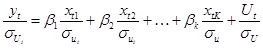
Для определения диагональных элементов матрицы применяют два способа:
1. Определение без статистической оценки:
2. Определение по принципу «гетероскедастичность между гомоскедастичными группами».
Оценки 1-МНК преобразованной относительно гетероскедастичности матрицы данных идентичны оценкам Эйткена.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 773; Нарушение авторских прав?; Мы поможем в написании вашей работы!