КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Основні етапи розвитку інформаційних систем
|
|
|
|
Автоматизовані інформаційні технології в обліку - людино-машинна система функціонування на базі локальних обчислювальних мереж та інших сучасних засобів обчислювальної техніки, що забезпечують автоматизоване виконання функцій бухгалтерського обліку.
Розвиток комп'ютерної інформаційної технології нерозривно пов'язаний з розвитком інформаційних систем, які в економіці використовуються для автоматизованого (людино-машинного) розв’язування економічних задач. Для розв'язування будь-якої допомогою комп'ютера необхідно створити інформаційне забезпечення (забезпечити розрахунки потрібними даними) і математичне забезпечення (створити математичну модель розв'язування задачі, наприклад за якою складається програма для ЕОМ). Спрощену схему автоматизованого розв'язування економічної задачі (наприклад, розрахунок оптимальної виробничої програми) зображено на рис. 1. Необхідна для розв'язування інформація може надходити безпосередньо (вхідна інформація) або через систему інформаційного забезпечення, яка може поповнюватися і за рахунок нової інформації. Визначальною особливістю інформаційної системи є те, що вона забезпечує користувачів інформацією з кількох організацій
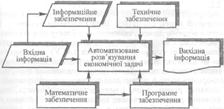
Рис.1. Схема автоматизованого розв’язання економічних задач
Математичні моделі й алгоритми можуть бути подані.у вигляді, який передбачає етап програмування, і у формі, придатній для прямого використання при розв'язуванні задачі. Вихідна інформація може бути подана в різних варіантах.
У системах обробки інформації головними її компонентами є дані та обчислення. Більшість інформаційних систем управління інформаційними ресурсами в організаціях містять і багато інших компонентів, таких як вимоги, запити, трігери і звіти. І всі вони, зокрема, містять великі описи свого власного змісту в тій чи іншій формі. Ці описи необхідні для інтерпретації і для коректного використання наданої інформації (коли в системі немає повного опису, то передбачається, що користувачі отримують його з іншого джерела).
Для головних компонент інформації (даних і обчислень) важливе значення має така характеристика, як їх надмірність. Означення надмірності суттєво залежить від одиниці інформації. Коли одиниця вибрана, то надмірність — це просто дублювання однієї й тієї самої одиниці в системі. Важливим у виборі одиниці інформації є її розмір. Вибір занадто малої одиниці призводить до високого рівня незалежності блоків інформації, але водночас і до збільшення накладних витрат затрат на їх підтримку; у разі взяття великої одиниці неможливо виключити численне дублювання підблоків інформації.
За час виникнення і розвитку інформаційних систем організаційного типу структура і надмірність даних і обчислень значно змінювались, чим визначались покоління цих систем. Схему розвитку інформаційних систем, що ілюструє особливості розв'язування функціональних задач залежно від характеру інформаційного і математичного забезпечення.
В інформаційних системах першого покоління, які в зарубіжній літературі відомі під назвою Ваіа Ргосеssing System - DPS(«Системи обробки даних», синоніми - «Електронна обробка даних», «Системи електронної обробки даних»), а у вітчизняній - «Автоматизовані системи управління (АСУ) - позадачний підхід» — для кожної задачі окремо готувалися дані і створювалася математична модель. Такий підхід зумовлював інформаційну надмірність (одні й ті самі дані могли використовуватись для розв'язування різних задач) і математичну надмірність (моделі розв'язування різних задач мали загальні блоки). Типовими прикладами систем обробки даних є системи керування запасами, виписування рахунків, нарахування зарплати.
Системи обробки даних були вузько прикладними й орієнтованими на автоматизацію робіт з паперами за рахунок комп'ютеризації великих масивів і потоків даних на операційному рівні. Розпізнавальною ознакою цих систем є ефективна обробка запитів, використання інтегрованих файлів для пов'язування між собою задач і генерування зведених звітів для керівництва. Оскільки кожна система була націлена на конкретне застосування, то опис її функцій (як правило, у формі надрукованих керівництв (інструкцій) до процедур або у вигляді стандартів) подавався мінімально і призначався для спеціаліста в цій предметній галузі. Крім того, передбачалось, що користувачі мають належний досвід як у прикладній галузі, так і в роботі із системами, які обслуговують відповідне застосування.
Створення ІС першого покоління в нашій країні відносять до початку 60-х років XX століття, коли на великих підприємствах почали використовувати ЕОМ для розв'язування задач організаційно-економічного управління. Перші такі системи обмежувалися розв'язуванням деяких функціональних управлінських задач, наприклад задач бухгалтерського обліку. Тому системність автоматизованої обробки економічної інформації в зазначений період характеризувалася частковістю та локальністю. Протягом наступних років поступово переходять від локальних систем обробки даних, призначених для тих чи інших ділянок управлінських робіт, до систем, що охоплюють широке коло задач управління. Подальший розвиток інформаційних систем пов'язаний з концепцією баз даних. На цій основі з'явились інформаційні системи другого покоління.
Інформаційні системи другого покоління відомі під назвою Маnagement Іnformation System - MIS («управлінські (адміністративні) інформаційні системи» або «інформаційні системи в менеджменті»), ми будемо використовувати термін «АСУ - концепція баз даних». Основною функцією таких систем є забезпечення керівництва інформацією. Типову управлінську інформаційну систему характеризує структурований потік інформації, інтеграція задач обробки даних, генерування запитів і звітів.
В управлінських інформаційних системах (УІС) вже були визнані переваги колективного користування даними, а також відзначено, що в одній організації багато прикладних програм використовують одні й ті самі робочі дані і відбувається дублювання робіт у процесі збирання, зберігання і пошуку цих даних. Зі збільшенням кількості прикладних програм, що обслуговують всі рівні управління та обробляють одні й ті самі робочі дані, зростав обсяг дублювання, що ставало гальмом на шляху комп'ютеризації управління. Більш того, це дублювання часто було неефективним, оскільки призводило до несумісності прикладних програм. Виходом із цієї ситуації стала концепція створення єдиної централізовано керованої бази даних, яка за допомогою спеціального програмного продукту — СУБД обслуговує всі прикладні програми організацій.
Основною проблемою створення великих розподілених баз даних є складність опису даних, що має на меті об'єктивного, незалежного від окремих прикладних програм, спростити колективне використання даних різними прикладними програмами. Для опису даних широко застосовуються моделі та словники даних. Семантика даних, тобто вивчення їх змісту незалежно від окремих прикладних програм, стала самостійною галуззю досліджень.
Подальшим розвитком інформаційних систем в економіці саме й було створення АСУ (ІС) на основі ідеології автоматизованих банків даних і баз даних. Цей етап створення ІС другого покоління розпочався 1972 року, коли вперше до державного плану було внесено питання розвитку економіки і створення АСУ. Розширилися технічна та програмна бази АСУ, урізноманітнилися варіанти їх побудови з орієнтуванням на окремі класи та моделі ЕОМ, зокрема міні- та мікрокомп'ютери. Зросла також варіантність ІС завдяки збільшенню кількості технологічних режимів експлуатації ЕОМ та всього комплексу технічних засобів, зокрема почалося впровадження діалогового режиму та режиму телеобробки даних.
У середині 80-х років був нагромаджений значний досвід створення та використання інформаційних систем організаційного управління. Створено багато автоматизованих систем управління технологічними процесами (АСУ ТП), систем автоматизованого проектування конструкцій та технологій (САПР).
Економічна ефективність АСУ була значна. Крім прямого економічного ефекту впровадження АСУ мало великий вплив на зміну характеру діяльності управлінського персоналу. Підвищилась оперативність, наукова обґрунтованість та об'єктивність прийманих управлінських рішень; стало можливим розв'язувати принципово нові економічні задачі, які до впровадження ІС не розв'язувалися апаратом управління; збільшився час на творчу роботу працівників за рахунок скорочення обсягів виконання рутинних операцій вручну; у результаті автоматизації процесів інформаційного обслуговування підвищилася інформованість управлінського персоналу.
Системи підтримки прийняття рішень — СППР (Decision Support Systems - DSS) - це інформаційні системи третього покоління. СППР — інтерактивна комп'ютерна система, яка призначена для підтримки різних видів діяльності в разі прийняття рішень зі слабоструктурованих або неструктурованих проблем.
Інтерес до СППР як перспективної галузі використання обчислювальної техніки та інструментарію підвищення ефективності праці у сфері управління економікою постійно зростає. У багатьох країнах розробка та реалізація СППР перетворилася на сферу бізнесу, що швидко розвивається.
СППР мають не тільки загальне інформаційне забезпечення, а й загальне математичне забезпечення — бази моделей, тобто реалізована ідея розподілу обчислень подібно до того, як розподіл даних став вирішальним фактором у звичайних інформаційних системах.
Усвідомлення важливості розподілу обчислень в автоматизованих розрахунках виникло тоді, коли було помічено, що в багатьох прикладних програмах використовуються аналогічні обчислення, а індивідуальні фактори, які впроваджуються в прикладні програми для допомоги конкретному користувачеві, вносять незначні відмінності. Крім того, спостерігалося значне дублювання дій і процедур під час розробки, реалізації та тестування цих обчислювальних функцій.
Зі зростанням кількості прикладних програм для надання персоналізованої оперативної підтримки, а також кількості інформаційних систем збільшувався обсяг обчислювального дублювання, що стало значною мірою гальмівним фактором: для індивідуальної оперативної підтримки необхідно виконувати досить багато персоналізованих версій однієї й тієї самої прикладної програми, причому кожна версія підлягає багаторазовій модифікації протягом періоду її експлуатації з тією метою, щоб вона відповідним чином реагувала на зміни в можливостях, знаннях, позиції і побажаннях користувача. Більш того, дубльована версія часто виявлялась менш ефективною, призводила до взаємної несумісності програм і меншої продуктивності обчислень. Виходом із такої ситуації стала концепція утворення єдиної централізовано керованої бази моделей.
Оскільки у вітчизняній літературі питання створення бази моделей практично не висвітлене, доцільно дати опис концепції бази моделей на простому прикладі.
Нехай на підприємстві діють дві прикладні задачі:
Задача А - обчислення повного обсягу збуту продукції за п періодів часу (наприклад, місяць);
Задача В — обчислення середнього обсягу збуту продукції за п періодів часу. Математичні моделі цих задач і інші характеристики наведені на рис. 2. В інформаційних системах першого покоління для розв'язування цих задач необхідно створити дві незалежні системи зі своїми файлами даних і своїми обчислювальними функціями:
для задачі А - файл даних М1 і обчислювальна функція ПОВН, що охоплює операції підсумовування і присвоєння (знак рівності "=");
для задачі В - файл даних М1 і величина п; обчислювальні функції: ПОВН, ДІЛ (ділення), ПРИС (присвоєння).
а – до обґрунтування концепції БМ
б – схема розв’язування задач в інформаційних системах
рис. 2 Приклад створення бази моделей (БМ)
 |
В інформаційних системах другого покоління дані про обсяг збуту розглядались би як загальний компонент і були б створені два незалежні алгоритми для обробки колективно використовуваних даних. А в третьому поколінні було усвідомлено, що обчислення повного обсягу також необхідне для середнього обсягу збуту; тому один і той самий алгоритм ПОВН застосовувався б в обох системах.
На цьому простому прикладі відразу помітна задача розпізнавання одиниць обчислювальних функцій, оскільки у другій прикладній задачі можна не побачити, що обчислення повного обсягу — незалежна частина алгоритму і що можна використати уже створений алгоритм. Отже, одна з важливих проблем створення єдиної бази моделей полягає в опису обчислень об'єктивно і незалежно від застосування, що має на меті охоплення якомога ширшого діапазону прикладних задач.
Підсумовуючи сказане з приводу трьох поколінь розвитку інформаційних систем, слід зазначити, що інформаційні системи нового покоління не витісняли попередні інформаційні системи, а просто розширювався діапазон застосування інформаційних систем. Більш того, у деяких сучасних гібридних інформаційних системах присутні елементи всіх трьох поколінь ІС. Загальний огляд розвитку перспективних інформаційних систем буде наведено далі.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 707; Нарушение авторских прав?; Мы поможем в написании вашей работы!