КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Суперскалярные процессоры
|
|
|
|
Поскольку возможности по совершенствованию элементной базы уже практически исчерпаны, дальнейшее повышение производительности ВМ лежит в плоскости архитектурных решений. Как уже отмечалось, один из наиболее эффективных подходов в этом плане — введение в вычислительный процесс различных уровней параллелизма. Ранее рассмотренный конвейер команд — типичный пример такого подхода. Тем же целям служат и арифметические конвейеры, где конвейеризации подвергается процесс выполнения арифметических операций. Дополнительный уровень параллелизма реализуется в векторных и матричных процессорах, но только при обработке многокомпонентных операндов типа векторов и массивов. Здесь высокое быстродействие достигается за счет одновременной обработки всех компонентов вектора или массива, однако подобные операнды характерны лишь для достаточно узкого круга решаемых задач. Основной объем вычислительной нагрузки обычно приходится на скалярные вычисления, то есть на обработку одиночных операндов, таких, например, как целые числа. Для подобных вычислений дополнительный параллелизм реализуется значительно сложнее, но тем не менее возможен и примером могут служить суперскалярные процессоры.
Суперскалярным (этот термин впервые был использован в 1987 году [45]) называется центральный процессор (ЦП), который одновременно выполняет более чем одну скалярную команду. Это достигается за счет включения в состав ЦП нескольких самостоятельных функциональных (исполнительных) блоков, каждый из которых отвечает за свой класс операций и может присутствовать в процессоре в нескольких экземплярах. Так, в микропроцессоре Pentium III блоки целочисленной арифметики и операций с плавающей точкой дублированы, а в микропроцессорах Pentium 4 и Athlon — троированы. Структура типичного суперскалярного процессора [234] показана на рис. 9.40. Процессор включает в себя шесть блоков: выборки команд, декодирования команд, диспетчеризации команд, распределения команд по функциональным блокам, блок исполнения и блок обновления состояния.
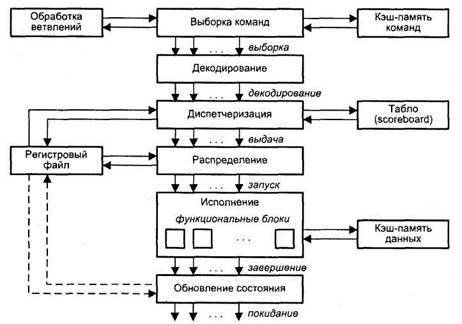
Рис. 9.40. Архитектура суперскалярного процессора
Блок выборки команд извлекает команды из основной памяти через кэш-память команд. Этот блок хранит несколько значений счетчика команд и обрабатывает команды условного перехода.
Блок декодирования расшифровывает код операции, содержащийся в извлеченных из кэш-памяти командах. В некоторых суперскалярных процессорах, например в микропроцессорах фирмы Intel, блоки выборки и декодирования совмещены.
Блоки диспетчеризации и распределения взаимодействуют между собой и в совокупности играют в суперскалярном процессоре роль контроллера трафика. Оба блока хранят очереди декодированных команд. Очередь блока распределения часто рассредоточивается по несколько самостоятельным буферам — накопителям команд или схемам резервирования (reservation station), — предназначенным для хранения команд, которые уже декодированы, но еще не выполнены. Каждый накопитель команд связан со своим функциональным блоком (ФБ), поэтому число накопителей обычно равно числу ФБ, но если в процессоре используется несколько однотипных ФБ, то им придается общий накопитель. По отношению к блоку диспетчеризации накопители команд выступают в роли виртуальных функциональных устройств. Оба вида очередей показаны на рис. 9.41 [234]. В некоторых суперскалярных процессорах они объединены в единую очередь.
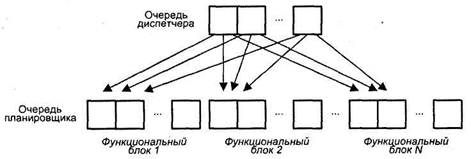
Рис. 9.41. Очереди диспетчеризации и распределения
В дополнение к очереди, блок диспетчеризации хранит также список свободных функциональных блоков, называемый табло (scoreboard). Табло используется для отслеживания состояния очереди распределения. Один раз за цикл блок диспетчеризации извлекает команды из своей очереди, считывает из памяти или регистров операнды этих команд, после чего, в зависимости от состояния табло, помещает команды и значения операндов в очередь распределения. Эта операция называется выдачей команд. Блок распределения в каждом цикле проверяет каждую команду в своих очередях на наличие всех необходимых для ее выполнения операндов и при положительном ответе начинает выполнение таких команд в соответствующем функциональном блоке.
Блок исполнения состоит из набора функциональных блоков. Примерами ФБ могут служить целочисленные операционные блоки, блоки умножения и сложения с плавающей запятой, блок доступа к памяти. Когда исполнение команды завершается, ее результат записывается и анализируется блоком обновления состояния, который обеспечивает учет полученного результата теми командами в очередях распределения, где этот результат выступает в качестве одного из операндов.
Как было отмечено ранее, суперскалярность предполагает параллельную работу максимального числа исполнительных блоков, что возможно лишь при одновременном выполнении нескольких скалярных команд. Последнее условие хорошо сочетается с конвейерной обработкой, при этом желательно, чтобы в суперскалярном процессоре было несколько конвейеров, например два или три.
Подобный подход реализован в микропроцессоре Intel Pentium, где имеются два конвейера, каждый со своим АЛУ (рис. 9.42). Отметим, что здесь, в отличие от стандартного конвейера, в каждом цикле необходимо производить выборку более чем одной команды. Соответственно, память ВМ должна допускать одновременное считывание нескольких команд и операндов, что чаще всего обеспечивается за счет ее модульного построения.
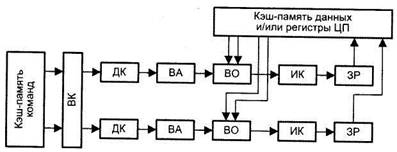
Рис. 9.42. Суперскалярный процессор с двумя конвейерами
Более интегрированный подход к построению суперскалярного конвейера показан на рис. 9.43. Здесь блок выборки (ВК) извлекает из памяти более одной команды и передает их через ступени декодирования команды и вычисления адресов операндов в блок выборки операндов (ВО). Когда операнды становятся доступными, команды распределяются по соответствующим исполнительным блокам. Обратим внимание, что операции «Чтение», «Запись» и «Переход» реализуются самостоятельными исполнительными блоками. Подобная форма суперскалярного процессора используется в микропроцессорах Pentium II и Pentium III фирмы Intel, а форма с тремя конвейерами — в микропроцессоре Athlon фирмы AMD.
По разным оценкам, применение суперскалярного подхода приводит к повышению производительности ВМ в пределах от 1,8 до 8 раз.

 Для сравнения эффективности суперскалярного и суперконвейерного режимов на рис. 9.44 показан процесс выполнения восьми последовательных скалярных команд. Верхняя диаграмма иллюстрирует суперскалярный конвейер, обеспечивающий в каждом тактовом периоде одновременную обработку двух команд. Отметим, что возможны суперскалярные конвейеры, где одновременно обрабатывается большее количество команд.
Для сравнения эффективности суперскалярного и суперконвейерного режимов на рис. 9.44 показан процесс выполнения восьми последовательных скалярных команд. Верхняя диаграмма иллюстрирует суперскалярный конвейер, обеспечивающий в каждом тактовом периоде одновременную обработку двух команд. Отметим, что возможны суперскалярные конвейеры, где одновременно обрабатывается большее количество команд.
В процессорах некоторых ВМ реализованы как суперскалярность, так и суперконвейеризация (рис. 9.45). Такое совмещение имеет место в микропроцессорах Athlon и Duron фирмы AMD, причем охватывает оно не только конвейер команд, но и блок обработки чисел в форме с плавающей запятой.
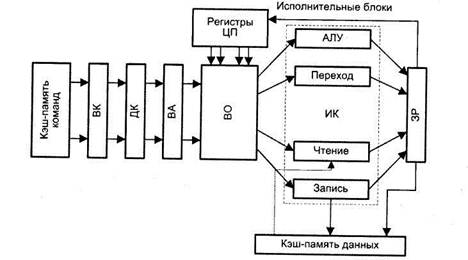
Рис. 9.43. Суперскалярный конвейер со специализированными исполнительными блоками
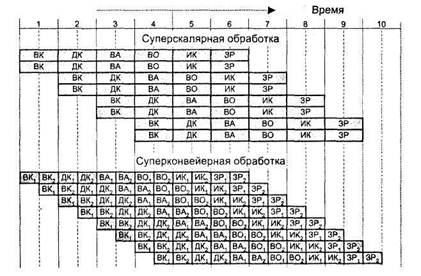
Рис. 9.44. Сравнение суперскалярного и суперконвейерного подходов
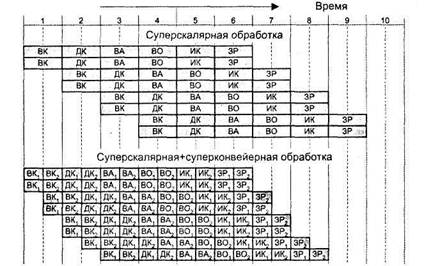
Рис. 9.45. Сравнение эффективности стандартной суперскалярной и совмещенной схем суперскалярных вычислений
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 4654; Нарушение авторских прав?; Мы поможем в написании вашей работы!