КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Особенности реализации суперскалярных процессоров
|
|
|
|
Поскольку в реальных суперскалярных процессорах множественность функциональных блоков сочетается с множественностью конвейеров команд, таким процессорам присущи все виды зависимостей, характерные для одинарных конвейеров, причем положение дел усугубляется тем, что конвейеров несколько. В суперскалярных процессорах одновременная работа нескольких конвейеров становится источником дополнительных неувязок, в частности проблемы последовательности поступления команд на исполнение и проблемы последовательности завершения команд.
Первая из упомянутых проблем возникает, когда очередность выдачи декодированных команд на исполнительные блоки отличается от последовательности, предписанной программой. Подобная ситуация известна как неупорядоченная выдача команд (out-of-order issue). Термин упорядоченная выдача команд (in-order issue) применяют, когда команды покидают ступени, предшествующие ступени исполнения, в определенном программой порядке. В обоих случаях завершение команд обычно неупорядочено (неупорядоченное завершение команд — out-of-order completion), и это является второй проблемой. Упорядоченное завершение происходит реже. Например, в последовательности

даже если команда умножения MUL поступит в исполнительный блок до команды сложения ADD, умножение может потребовать много циклов, из-за чего команда MUL будет завершена позже, чем ADD. В современных микропроцессорах каждая команда разбивается на простейшие микрооперации, которые далее выполняются суперскалярным процессорным ядром в порядке, который удобен процессору.
В суперскалярных процессорах, с их множественными конвейерами и неупорядоченными выдачами/завершениями, взаимозависимость команд представляет серьезную проблему. Кроме того, существует еще один фактор, характерный только для суперскалярных процессоров, — конфликт по функциональному блоку, когда на него претендуют несколько команд, поступивших из разных конвейеров.
Пусть имеется последовательность

Зависимости между командами здесь нет, однако если в ЦП имеется только одно АЛУ, одновременное выполнение указанных операций невозможно.
Стратегии выдачи и завершения команд
В режиме параллельного выполнения нескольких команд процессор должен определить, в какой очередности ему следует:
ü выбирать команды из памяти;
ü выполнять эти команды;
ü позволять командам изменять содержимое регистров и ячеек памяти.
Для достижения максимальной загрузки всех ступеней своих конвейеров суперскалярный процессор должен варьировать все перечисленные виды последовательностей, но так, чтобы получаемый результат был идентичен результату при выполнении команд в порядке, определенном программой. Значит, процессор обязан учитывать все виды зависимостей и конфликтов.
В самом общем виде стратегии выдачи и завершения команд можно сгруппировать в такие категории:
ü упорядоченная выдача и упорядоченное завершение;
ü упорядоченная выдача и неупорядоченное завершение;
ü неупорядоченная выдача и неупорядоченное завершение.
Проанализируем каждый из этих вариантов на примере суперскалярного процессора с двумя конвейерами [200]. Процессор способен одновременно выбирать и декодировать две команды, причем передача обеих команд на декодирование должна также производиться одновременно. В состав процессора входят три отдельных функциональных блока (ФБ) и два устройства, обеспечивающие запись результата. В рассматриваемом примере предполагается существование следующих ограничений на выполнение программного кода из шести команд (I1-I6):
ü I1 требует для своего выполнения двух циклов процессора;
ü I3 и I4 имеют конфликт за обладание одним и тем же ФБ;
ü I5 зависит от значения, вычисляемого командой I4;
ü I5 и I6 конфликтуют за обладание одним и тем же ФБ.
Упорядоченная выдача и упорядоченное завершение. Наиболее простым в реализации вариантом является выдача декодированных команд на исполнение в том порядке, в котором они должны выполняться по программе (упорядоченная выдача), с сохранением той же последовательности записи результатов (упорядоченное завершение). Хотя такая стратегия и применялась в первых процессорах типа Pentium, сейчас она практически не встречается. Тем не менее ее обычно берут в качестве точки отсчета при сравнении различных стратегий выдачи и завершения. Согласно данному принципу, все что затрудняет завершение команды в одном конвейере, останавливает и другой конвейер, так как команды должны покидать конвейеры, соответствуя порядку поступления на них. Пример использования подобной стратегии показан на рис. 9.46.
Здесь производятся одновременная выборка и декодирование двух команд. Чтобы принять очередные команды, процессор должен ожидать, пока освободятся обе части ступени декодирования. Для упорядочивания завершения выдача команд приостанавливается, если возникает конфликт за общий функциональный блок или если функциональному блоку для формирования результата требуется более чем один такт процессора.
В рассматриваемом примере время задержки от декодирования первой команды до записи последнего результата составляет 8 тактов.
Упорядоченная выдача и неупорядоченное завершение. Стратегии с неупорядоченным завершением дают возможность одному из конвейеров продолжать работать при «заторе» в другом, при этом команды, стоящие в программе «позже», могут быть фактически выполнены раньше предыдущих, «застрявших» в другом конвейере. Естественно, процессор должен гарантировать, что результаты не будут записаны в память, а регистры не будут модифицироваться в неправильной последовательности, поскольку при этом могут получиться ошибочные результаты.

Рис. 9.46. Упорядоченная выдача и упорядоченное завершение
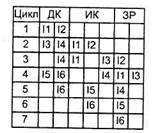
Рис. 9.47. Упорядоченная выдача и неупорядоченное завершение
Проиллюстрируем стратегию с упорядоченной выдачей и неупорядоченным завершением (рис. 9.47). При заданных ей условиях допускается, что команда I2 может быть завершена еще до окончания исполнения команды I1. Это позволяет команде I3 завершиться на один такт раньше, вследствие чего результаты выполнения команд I1 и I3 записываются в одном и том же такте. При неупорядоченной выдаче в любой момент времени в стадии исполнения может находиться любое число команд, а степень параллелизма ограничена только числом функциональных блоков. По сравнению с предыдущей стратегией, возможность неупорядоченного завершения команд привела к сокращению времени выполнения шести команд на один цикл процессора.
Неупорядоченная выдача и неупорядоченное завершение. Неупорядоченная выдача развивает предыдущую концепцию, разрешая процессору нарушать предписанный программой порядок выдачи команд на исполнение. Чтобы обеспечить неупорядоченную выдачу команд, в конвейере необходимо максимально развязать ступени декодирования и исполнения. Это обеспечивается с помощью буферной памяти, называемой окном команд. Каждая декодированная команда сначала помещается в окно команд. Процессор может продолжать выборку и декодирование новых команд вплоть до полного заполнения буфера. Выдача команд из буфера на исполнение определяется не последовательностью их поступления, а мерой из буфера на исполнение.
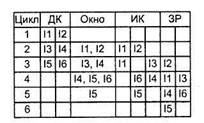
Рис. 9.48. Неупорядоченная выдача и неупорядоченное завершение
Стратегию иллюстрирует рис. 9.48. В каждом цикле процессора две команды из ступени декодирования пересылаются в окно команд (с учетом ограничения на размер буфера). Выдача команд из буфера производится по мере их готовности. Так, в рассматриваемом примере возможна выдача команды I6 до выдачи команды I5 (напомним, что I5 зависит от I4, а I6 — нет). Таким образом, сберегается один такт, как в ступени исполнения команды (ИК), так и в ступени записи результата (ЗР), и сквозная экономия по сравнению с рис. 9.47 составляет один цикл процессора. На рисунке изображено окно команд, но оно не является дополнительной ступенью конвейера.
Стратегии неупорядоченной выдачи и неупорядоченного завершения также свойственны ранее рассмотренные ограничения. Команда не может быть выдана, если она приводит к зависимости или конфликту. Разница заключается в том, что к выдаче готово больше команд, и это позволяет уменьшить вероятность приостановки конвейера.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1519; Нарушение авторских прав?; Мы поможем в написании вашей работы!