КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Архитектура VLIW
|
|
|
|
Процессоры с множественной выдачей инструкций (multiple-issue processors) ориентированы на исполнение нескольких инструкций за такт и бывают двух видов: суперскалярные процессоры (superscalar processors) и процессоры с архитектурой VLIW (Very Long Instruction Word).
Первые суперскалярные процессоры работали в режиме упорядоченной выдачи команд. Но упорядоченная выдача команд (in-order issue) неэффективна, так
как требуемое функциональное устройство (FU) может оказаться занятым. Упорядоченное завершение команд (in-order completion) также неэффективно, так как остановка продвижения в одном функциональном устройстве приведёт к простою всех функциональных устройств. Неупорядоченные выдача и завершение - неупорядоченная модель обработки (out-of-order execution) - дополнительный потенциал повышения производительности суперскалярного процессора. Современные суперскалярные процессоры исполняют от 2 до 10 инструкций за такт и используют аппаратную логику анализа архитектуры системы команд перед выдачей команд. Такой аппаратный механизм переупорядочивания исполнения инструкций (out-of-order engine) называется динамическим планированием. Компилятор и динамический планировщик не могут обойти все конфликты (структурные, по данным, по управлению) и задержки доступа к памяти (при кеш-промахах). Таким образом, фактическое число выданных в такте инструкций колеблется от нуля до максимально возможного (загрузка FU колеблется от 0% до 100%).
Если суперскалярные процессоры исполняют переменное число инструкций за такт, используя методы как статического (развёртка кода компилятором), так и динамического (алгоритм Томасуло) планирования, то VLIW процессоры, напротив, исполняют фиксированное число независимых инструкций, сгруппированных в одну длинную инструкцию. таком пакете инструкций параллелизм уровня инструкций обеспечивается статически на этапе компиляции. Компания Intel, например, именует такую методику явного распараллеливания инструкций - EPIC -Explicitly Parallel Instruction Computing.
Суть явного параллелизма заключается в том, что распределение команд между исполнительными узлами производится не процессором в ходе выполнения программы (динамически), а компилятором при формировании машинного кода (статически). Таким образом, схемотехника VLIW процессора существенно упрощается (по сложности он сравним с суперскалярным процессором без поддержки неупорядоченного исполнения команд). Кроме того, в компиляторах алгоритмы выбора порядка исполнения команд могут быть существенно сложнее и эффективнее, чем алгоритмы аппаратного планирования инструкций (так как решение необходимо принимать в течение наносекунд).
VLIW (англ. very long instruction word — «очень длинная машинная команда») — архитектура процессоров с несколькими вычислительными устройствами. Характеризуется тем, что одна инструкция процессора содержит несколько операций, которые должны выполняться параллельно. Фактически это «видимое программисту» микропрограммное управление, когда машинный код представляет собой лишь немного свернутый микрокод) для непосредственного управления аппаратурой.
суперскалярных процессорах также есть несколько вычислительных модулей, но задача распределения между ними работы решается аппаратно. Это сильно усложняет дизайн процессора, и может быть чревато ошибками. процессорах VLIW задача распределения решается во время компиляции и в инструкциях явно указано, какое вычислительное устройство должно выполнять какую команду.
VLIW можно считать логическим продолжением идеологии RISC, расширяющей её на архитектуры с несколькими вычислительными модулями. Так же, как в RISC, в инструкции явно указывается, что именно должен делать каждый модуль процессора. Из-за этого длина инструкции может достигать 128 или даже 256 бит.
2.7. КОМПЬЮТЕРЫ СО СТЕКОВОЙ АРХИТЕКТУРОЙ
При создании компьютера одновременно проектируют и систему команд (СК) для него. Существенное влияние на выбор операций для их включения в СК оказывают:
* элементная база и технологический уровень производства ком-пьютеров;
класс решаемых задач, определяющий необходимый набор операций, во-
площаемых в отдельные команды;
* системы команд для компьютеров аналогичного класса;
* требования к быстродействию обработки данных, что может породить созда-
ние команд с большой длиной слова (VLIW-команды).
Анализ задач показывает, что в смесях программ доминирующую роль играют команды пересылки и процессорные команды, использующие регистры и простые режимы адресации.
На сегодняшний день наибольшее распространение получили следующие структуры команд: одноадресные (1А), двухадресные (2А), трехадресные (ЗА), безадресные (БА), команды с большой длиной слова (VLIW - Б ДО (рис. 2.1 - знать и разбираться):
1А~
| КОП | А1 |
2А
| КОП | А1 | А2 |
ЗА
| КОП | А1 | А2 | A3 |
БА
КОП
БДС
| коп | Адреса | Теги | Дескрипторы |
Рис. 2.1. Структуры команд
Причем операнд может указываться как адресом, так и непосредственно в структуре команды.
случае БА-команд операнды выбираются и результаты помещаются в стек (магазин, гнездо). Типичными первыми представителями БА-компьютеров являются KDF-9 и МК "Эльбрус". Их характерной особенностью является наличие стековой памяти.
| го хранения данных и операций. |
Стек - это область оперативной памяти, которая используется для временно-
щступ к элементам стека осуществляется по
| принциг |
FILO (first in, last out) - первым вошел, последним вышел. Кроме того,
доступ к элементам стека осуществляется только через его вершину, т. е. пользователю "виден" лишь тот элемент, который помещен в стек последним.
Рассмотрим функционирование процессора со стековой организацией памяти.
При выполнении различных вычислительных процедур процессор использует либо новые операнды, до сих пор не выбиравшиеся из памяти компьютера, либо операнды, употреблявшиеся в предыдущих операциях. процессорах с классической структурой обращение к любому операнду (1А-ЭВМ) требует цикла памяти.
Рассмотрим пример.
Пусть процессор вычисляет значение выражения
X
а2+Ь; b + с
Программа решения этой задачи для одноадресного компьютера может быть
следующей (табл. 2.4).
Таблица 2.4. Пример программы
| Номер команды | Команда | Комментарии |
| C^Z | ||
| (I)+b | ||
| (I)">Р! | R - рабочая ячейка 1 " | |
| а->Е | ||
| (I)•* | ||
| (I)">Р, | P, - рабочая ячейка 2 г | |
| b^Z | ||
| (I)-ь | ||
| (I) + (p,) | ||
| (I):(P.) | а'+ь' Ь+ с |
Замечание. ыполнение команды типа (^) ® (Р) подразумевает, что результат операции помещается в первый регистр, в данном случае в регистр ^].
Как следует из приведенной программы, операнд а выбирается из памяти 2 раза (команды 4 и 5), Ъ - 3 раза (команды 2, 7 и 8). Кроме того, потребовались дополнительные обращения к памяти для запоминания и вызова из памяти результатов промежуточных вычислений (команды 3, 6, 9, 10).
Если главным фактором, ограничивающим быстродействие компьютера, является время цикла памяти, то необходимость в дополнительных обращениях к памяти значительно снижает скорость его работы. Очевидно, что принципиально необходимы только обращения к памяти за данными в первый раз. дальнейшем они могут храниться в триггерных регистрах или СОЗУ.
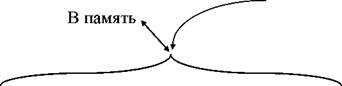
Указанные соображения получили свое воплощение в ряде логических структур процессора. Одна из них - процессор со стековой памятью. Принцип ее работы поясняет схема, представленная на рис. 2.2.
|
|
| ИИ | ||
| Pi | ||
| пи | ш | |
| ?2 | ||
| ИИ | ш | |
| Рз |
| Рп |
Рис. 2.2. Стековая организация процессора
Стековая память представляет собой набор из п регистров, каждый из кото
рых способен хранить одно машинное слово. Одноименные разряды регистров Р ь
Р? ,..., Рл соединены между собой цепями сдвига. есь набор регистров может рас
сматриваться как группа n-разрядных сдвигающих регистров, составленных из од
ноименных разрядов регистров Рь Р?........ Рп. Информация в стеке может продви-
гаться между регистрами вверх и вниз.
Движение вниз: (P i ) —> Р?, (Р?) —> Рз,..., а Р^ заполняется данными из главной памяти.
Движение вверх: (Рд) —> Рги, (Рги) — > Рл л, а Рп заполняется нулями.
Регистры Р^ и Р? связаны с АЛУ, образуя два операнда для выполнения операции. Результат операции записывается в Рь Следовательно, АЛУ выполняет операцию (Р,)®(Р„) -»Р.
*^— ==> ------- \ 1/ \ 2/ 1 -
Одновременно с выполнением арифметической операции (АО) осуществляется продвижение операндов вверх, не затрагивая Рь т. е. (PQ — > Р?, (Р д ) —> Рз и т. д.
Таким образом, АО используют подразумеваемые адреса, что уменьшает длину команды. принципе, в команде достаточно иметь только поле, определяющее код операции. Поэтому компьютеры со стековой памятью называют безадресными. то же время команды, осуществляющие вызов или запоминание информации из главной памяти, требуют указания адреса операнда. Поэтому в ЭВМ со стековой памятью используются команды переменной длины. Например, в KDF-9 команды АО - однослоговые, команды обращения к памяти и передач управления - трех-слоговые, остальные - двуслоговые.
Команды располагаются в памяти в виде непрерывного массива слогов независимо от границ ячеек памяти. Это позволяет за один цикл обращения к памяти вызвать несколько команд.
Для эффективного использования возможностей такой памяти в ЭВМ вводятся спецкоманды:
• дублирование ~ (P i ) —> Р?, (Р?) — > Р я, ••• и т. д., a (P i ) остается при этом неизменным;
• реверсирование ~ (Рь) —> Р?, а (Р?) — > Рь что удобно для выполнения некоторых операций.
Рассмотрим тот же пример для новой ситуации (табл. 2.5):
a2+b2
X =.
b + c
Таблица 2.5. Реализация программы со стековой памятью
| № п/п | Команда | Pi | Рг | Рз | Рд |
| Вызов b | b | ||||
| Дублирование | b | В | |||
| Вызов с | с | в | В |
| № п/п | Команда | Pi | P2 | Рз | P4 |
| Сложение | b+c | В | |||
| Реверсирование | b | b+c | |||
| Дублирование | b | В | b+c | ||
| Умножение | b2 | b+c | |||
| ызов а | a | b2 | b+c | ||
| Дублирование | a | A | b | b+c | |
| Умножение | a2 | b2 | b+c | ||
| Сложение | a2+b2 | b+c | |||
| Деление | a + b 22 b + c |
Как следует из табл. 2.5, понадобились лишь три обращения к памяти для вызова операндов (команды 1, 3, 8). Меньше обращений принципиально невозможно. Операнды и промежуточные результаты поступают для операций в АУ из стековой памяти; 9 команд из 12 являются безадресными.
ся программа размещается в трех 48-разрядных ячейках памяти.
Главное преимущество использования стековой (магазинной) памяти состоит в том, что при переходе к подпрограммам (1111) или в случае прерывания нет необходимости в специальных действиях по сохранению содержимого арифметических регистров в памяти. Новая программа может немедленно начать работу. При введении в стековую память новой информации данные, соответствующие предыдущей программе, автоматически продвигаются вниз. Они возвращаются обратно, когда новая программа закончит вычисления.
Преимуществами стековой памяти являются:
* уменьшение количества обращений к памяти;
* упрощение способа обращения к подпрограммам и обработки прерываний. Недостатки стековой организации памяти:
• большое число регистров с быстрым доступом;
• необходимость в дополнительном оборудовании, чтобы следить за переполнением стековой памяти, так как число регистров памяти всегда конечно;
• приспособленность главным образом для решения научных задач и в меньшей степени для систем обработки данных или управления технологическими
k процессами.
-------------- \
шец лекции \
№ 4 / 40
2.8. МЕТОДЫ АДРЕСАЦИИ И ТИПЫ КОМАНД
машинах с регистрами общего назначения метод (или режим) адресации объектов, с которыми манипулирует команда, может задавать константу, регистр или ячейку памяти.
табл. 2.2 представлены основные методы адресации операндов, которые 'еализованы в большинстве компьютеров (знать все методы).
Таблица 2.2. Методы адресации
| Метод адресации | Пример команды | Смысл команды | Использование команды |
| Регистровая | Add R4, R3 | R4 = R4+R3 | Для записи требуемого значения в регистр |
| Непосредственная или литерная | Add R4, #3 | R4 = R4+3 | Для задания констант |
| Базовая со смещением | Add R4, 100(R1) | R4= R4+M(100+R1) | Для обращения к локальным переменным |
| Косвенная регистровая | Add R4, (R1) | R4 = R4+M(R1) | Для обращения по указателю к вычисленному адресу |
| Индексная | Add R3, (R1+R2) | R3 = R3+M(R1+R2) | Полезна при работе с массивами: R1 - база, R3 - индекс |
| Прямая или абсолютная | Add R1, (1000) | R1=R1+M(1000) | Полезна для обращения к статическим данным |
| Косвенная | Add R1, @(R3) | Rl = R1+M(M(R3)) | Если R3 - адрес указателя р, то выбирается значение по этому указателю |
| Автоинкрементная | Add R1, (R2)+ | Rl = R1+M(R2) R2 = R2+d | Полезна для прохода в цикле по массиву с шагом: R2 - начало массива. каждом цикле R2 получает приращение d |
| Автодекрементная | Add R1, (R2)– | R2 = R2-d Rl = R1+M(R2) | Аналогична предыдущей. Обе могут использоваться для реализации стека |
| Базовая индексная со смещением и масштабированием | Add R1, 100(R2)(R3) | R1=R 1 +M(100)+R2 +R3*d | Для индексации массивов |
Адресация непосредственных данных и литерных констант обычно рассматривается как один из методов адресации памяти (хотя значения данных, к которым
в этом случае производятся обращения, являются частью самой команды и обрабатываются в общем потоке команд).
табл. 2.2 на примере команды сложения (Add) приведены наиболее употребительные названия методов адресации, хотя при описании архитектуры в документации производители компьютеров и ПО используют разные названия для этих методов. табл. 2.2. знак "=" используется для обозначения оператора присваивания, а буква М обозначает память (Memory). Таким образом M(R1) обозначает содержимое ячейки памяти, адрес которой определяется содержимым регистра R1.
Использование сложных методов адресации позволяет существенно сократить количество команд в программе, но при этом значительно увеличивается сложность аппаратуры.
Команды традиционного машинного уровня можно разделить на несколько типов, которые показаны в табл. 2.3 (знать все типы).
Таблица 2.3. Основные типы команд
| Тип операции | Примеры |
| Арифметические и логические | Целочисленные арифметические и логические операции: сложение, вычитание, логическое сложение, логическое умножение и т. д. |
| Пересылки данных | Операции загрузки/записи |
| Управление потоком команд | Безусловные и условные переходы, вызовы процедур и возвраты |
| Системные операции | Системные вызовы, команды управления виртуальной памятью и т. д. |
| Операции с плавающей точкой | Операции сложения, вычитания, умножения и деления над вещественными числами |
| Десятичные операции | Десятичное сложение, умножение, преобразование форматов и т. д. |
| Операции над строками | Пересылки, сравнения и поиск строк |
Тип операнда может задаваться либо кодом операции в команде, либо с помощью тега, который хранится вместе с данными и интерпретируется аппаратурой во время обработки данных.
Обычно тип операнда (целый, вещественный, символ) определяет и его размер. Как правило, целые числа представляются в дополнительном коде. Для задания символов компания IBM использует код EBCDIC, другие компании применяют код ASCII. Для представления вещественных чисел с одинарной и двойной точностью придерживаются стандарта IEEE 754.
ряде процессоров применяют двоично кодированные десятичные числа, которые представляют в упакованном и неупакованном форматах. Упакованный формат предполагает, что для кодирования цифр 0 - 9 используют 4 разряда и две
десятичные цифры упаковываются в каждый байт. неупакованном формате байт содержит одну десятичную цифру, которая обычно изображается в символьном коде ASCII.
2.9. ОПТИМИЗАЦИЯ СИСТЕМЫ КОМАНД
ажным вопросом построения любой системы команд является оптимальное кодирование команд. Оно определяется количеством регистров и применяемых методов адресации, а также сложностью аппаратуры, необходимой для декодирования. Именно поэтому в современных RISC-архитектурах используются достаточно простые методы адресации, позволяющие резко упростить декодирование команд. Более сложные и редко встречающиеся в реальных программах методы адресации реализуются с помощью дополнительных команд, что, вообще говоря, приводит к увеличению размера программного кода. Однако такое увеличение программы с лихвой окупается возможностью простого увеличения частоты RISC-процессоров. Этот процесс мы можем наблюдать сегодня, когда максимальные тактовые частоты практически всех RISC-процессоров (Alpha, R4400, HyperSPARC и Power2) превышают тактовую частоту, достигнутую процессором Pentium.
Существует два способа выбора и построения системы команд:
1. На основе знаний класса решаемых задач, выбор некоторой типовой системы команд для широко распространенного класса компьютеров и исследование выбранной СК на предмет присутствия всего разнообразия операций в заданном классе задач. Не встречающиеся или редко встречающиеся операции исключаются. Частота встреч операций для задания их в СК определяется из соотношения «стоимость затрат - сложность реализации - получаемый выигрыш».
2. Состоит в расширении имеющейся системы команд. Существует два подхода.
а)Создание макрокоманд
б)Дополнение имеющегося синтаксиса языка СК новыми командами с по
следующим переассемблированием, через расширение функций ассемблера.
Оба эти способа принципиально одинаковы, но отличаются в тактике реализации аппарата расширения.
Так, система команд для ПК IBM покрывает следующие группы операций: передачи данных, арифметические операции, операции ветвления и циклов, логические операции и операции обработки строк.
Способы оптимизации системы команд:
1. выявление частоты повторений сочетаний двух или более команд, следующих друг за другом в некоторых типовых задачах для данного компьютера, с последующей заменой их одной командой, выполняющей те же функции. Это приводит к сокращению времени выполнения программы и уменьшению требуемого объема памяти;
2. исследование частоты генерируемых компилятором последовательностей команд, с последующей ликвидацией избыточных кодов, т.е. заменой группы команд одной командой;
3. оптимизация в пределах отдельной команды на основе исследования ее информационной емкости. Для этого можно применить аппарат теории информации, в частности для оценки количества переданной информации - энтропию источника. Тракт "процессор - память" можно считать каналом связи.
Замечание. Энтропия - это мера вероятности пребывания системы в данном состоянии (в статистической физике).
2.10 ИСТОРИЯ РАЗВИТИЯ МИКРОПРОЦЕССОРНЫХ АРХИТЕКТУР НА ОСНОВЕ ОПТИМИЗАЦИИ СИСТЕМЫ КОМАНД
Поскольку каждый производитель процессоров по-своему улучшал архитектуру, развитие микропроцессоров сопровождалось появлением нескольких вариантов SIMD расширений (один поток инструкций, множественный поток данных).
ммх
MMX-расширение появилось в Pentium ММХ (январь 1997) и включало в себя 57 новых команд, предназначенных для обработки звуковых и видеосигналов. Позднее их поддержка появилась в Кб (Little Foot) от AMD и в 6х86МХ от Cyrix.
MMX-расширение микропроцессора Pentium предназначено для поддержки приложений, ориентированных на работу с большими массивами данных целого типа, над которыми выполняются одинаковые операции. С данными такого типа обычно работают мультимедийные, графические, коммуникационные программы. По этой причине данное расширение архитектуры микропроцессоров Intel и названо MultiMedia extensions (ММХ), что переводится как мультимедиа расширения.
Основа программной компоненты - система команд MMX-расширения (те самые 57 новых команд) и четыре новых типа данных. ММХ-команды являются естественным дополнением основной системы команд микропроцессора. Основным принципом их работы является одновременная обработка нескольких единиц однотипных данных одной командой. Основа аппаратной компоненты - 8 ММХ регистров, каждый размером в 64 бит = 8 байт. ММХ работает только с целыми числами; поддерживаются данные размером в 1, 2, 4 или 8 байт. То есть, один ММХ регистр может содержать 8, 4, 2 или 1 операнд соответственно.
|
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 1731; Нарушение авторских прав?; Мы поможем в написании вашей работы!