КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Количество информации
|
|
|
|
II часть лекции.
Для оценки и измерения количества информации применяются статистический, семантический, прагматический и структурный подходы.
Статистический подход (основоположник Шеннон, 1948г.) измеряет количество информации уменьшением неопределенности состояния системы. Количественно выраженная неопределенность состояния системы получила название энтропии. При получении информации неопределенность системы, т.е. ее энтропия уменьшается. Если энтропия =0, то о ней имеется полная информация.
Семантический подход (основатели Н.Винер, Ю.Шнайдер) предполагает, что для получения и использования информации ее получатель должен обладать определенным запасом знаний – тезаурусом. Если индивидуальный тезаурус потребителя равен 0, то в этом случае и количество воспринятой им смысловой информации будет равно 0.
Прагматический подход определяет количество информации как меру, способствующую достижению поставленной цели.
Структурный подход предполагает абстрагирование от смыслового содержания информации с целью организации таких логических и физических структур организации информации, которые позволяли бы наиболее эффективно ее использовать (быстрый поиск, извлечение, копирование и т.д.) Структурный подход предполагает преобразование информации в машинные коды и обратно в доступную форму. Структурными элементами информации являются поля, записи, массивы, банки данных и т.д.
Количество информации - числовая характеристика информации, отражающая ту степень неопределенности, которая исчезает после получения информации.
Пусть объем алфавита A составляет m дискретных сообщений. Каждое сообщение включает n символов. В принятых обозначениях общее количество дискретных символов составляет 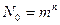
. Покажем, как определяется количество информации в сообщениях такого источника.
Удобной характеристикой сообщений является логарифмическая мера количества информации H, удовлетворяющая перечисленным выше требованиям, а именно
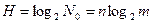
Эта формула предложена Р.Хартли в 1928 г. как мера количества информации. Формула Хартли не отражает случайного характера формирования сообщений. Чтобы устранить этот недостаток, необходимо связать количество информации в сообщениях с вероятностью появления символов. Эта задача была решена К. Шенноном в 1948 г.
Пусть сообщение состоит из одного символа. Если вероятности появления всех символов одинаковы и равны P = 1/m, то количество информации, которое переносит символ, можно выразить как
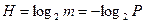
Здесь количество информации связано с вероятностью появления символа. В реальных сообщениях символы 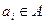 появляются с различными вероятностями
появляются с различными вероятностями 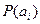 , поэтому
, поэтому
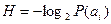
Среднее количество информации H(A), которое приходится на один символ источника сообщений можно найти усреднением по всему объему алфавита
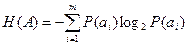 (1) ф-ла Шеннона
(1) ф-ла Шеннона
Эта величина называется энтропией источника дискретных сообщений. Формула (1) носит название формулы Шеннона.
Энтропия рассматривается как мера неопределенности в поведении источника сообщений.
Энтропия является непрерывной функцией от вероятностей появления символов и обладает следующими свойствами:
· Энтропия источника дискретных сообщений есть величина вещественная, ограниченная и неотрицательная.
· Энтропия равна нулю, если с вероятностью единица выбирается один и тот же символ (неопределенность в поведении источника отсутствует).
· Энтропия максимальна, если все символы источника появляются независимо и с одинаковой вероятностью.
Кодирование данных двоичным кодом
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления — для этого обычно используется прием кодирования, то есть выражение данных одного типа через данные другого типа.
В качестве примеров можно привести систему записи математических выражений, азбуку Морзе, морскую флажковую азбуку, систему Брайля для слепых другие.
Своя система существует и в вычислительной технике — она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по английски — binary digit или, сокращенно, bit (бит).
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т. п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11
Тремя битами можно закодировать восемь различных значений:
000 001 010 011
100 101 110 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
N = 2m, где:
N — количество независимых кодируемых значений;
m — разрядность двоичного кодирования, принятая в данной системе.
1байт = 8бит
1 КБ = 1024 Б = 210 (1024) Б.
1 МБ = 1024 КБ = 220 (1024 x1024) Б.
1 ГБ= 1024 МБ = 230 (1024х1024 х1024) Б.
1 ТБ = 1024 ГБ = 240 (1024х1024х1024х1024) Б.
1 ПБ = 1024 ТБ = 250 (1024х1024х1024х1024х1024)Б.
Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом достаточно просто — достаточно взять целое число и делить его пополам до тех пор, пока в остатке не образуется ноль или единица. Совокупность остатков от каждого деления, записанная справа налево вместе с последним остатком, и образует двоичный аналог десятичного числа.
19: 2 = 9 (1)
9: 2 = 4 (1)
4: 2 = 2 (0)
2: 2 = 1 (0)
1: 2 = 0 (1)
|
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65535, а 24 бита — уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
|
 300 000 = 0,3 · 106
300 000 = 0,3 · 106
 123 456 789 = 0,123456789 · 109
123 456 789 = 0,123456789 · 109
Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком).
/для представления очень больших и очень малых чисел, числа с плавающей запятой – представления дробных чисел (тогда число хранится в форме мантиссы и показателя степени) /
Кодирование текстовых данных.
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию.
Восьми двоичных разрядов достаточно для кодирования 256 различных символов.(28 )
Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например символ «§».
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI — American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств).
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов.
Базовая таблица кодировки ASCII приведена в таблице
Аналогичные системы кодирования текстовых данных были разработаны и в других странах.
Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших. Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение. Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы. Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Организационные трудности вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE.
Шестнадцать разрядов позволяют обеспечить уникальные коды для 65536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Кодирование графических данных
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части -- растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element).
Код пиксела содержит информации о его цвете.
Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится -- не светится), а для его кодирования достаточно одного бита памяти: 1 - белый, 0 - черный.
Пиксел на мониторе может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 -- черный, 10 -- зеленый, 01 -- красный, 11 -- коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов -- красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
|
|
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов -- К и количество битов для их кодировки -- N связаны между собой простой формулой: 2N = К.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения -- линия, прямоугольник, окружность или фрагмент текста -- располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т. д.). Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличии от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость). Подробнее о графических форматах рассказывается в разделе "Компьютерная графика".
/Современные компьютерные видеодисплеи отображают информацию в растровом формате/
Кодирование звуковой информации
Приемы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В то же время, данный метод кодирования обеспечивает весьма компактный код, и потому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
Метод таблично-волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называют сэмплами.
Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 3765; Нарушение авторских прав?; Мы поможем в написании вашей работы!