КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Estimation
|
|
|
|
Randomness and data
We will assume simple random sampling
Conditional mean, ctd.
Conditional expectations and conditional moments
Conditional distributions
· The distribution of Y, given value(s) of some other random variable, X
· Ex: the distribution of test scores, given that STR < 20
· conditional mean = mean of conditional distribution
= E (Y | X = x) (important concept and notation)
· conditional variance = variance of conditional distribution
· Example: E (Test scores | STR < 20) = the mean of test scores among districts with small class sizes
The difference in means is the difference between the means of two conditional distributions:
D = E (Test scores | STR < 20) – E (Test scores | STR ≥ 20)
Other examples of conditional means:
· Wages of all female workers (Y = wages, X = gender)
· Mortality rate of those given an experimental treatment (Y = live/die; X = treated/not treated)
· If E (X | Z) = const, then corr(X, Z) = 0 (not necessarily vice versa however)
The conditional mean is a (possibly new) term for the familiar idea of the group mean
(d) Distribution of a sample of data drawn randomly
from a population: Y B 1 B ,…, Y B n B
· Choose and individual (district, entity) at random from the population
· Prior to sample selection, the value of Y is random because the individual selected is random
· Once the individual is selected and the value of Y is observed, then Y is just a number – not random
· The data set is (Y B1B, Y B2B,…, Y B n B), where Y B i B = value of Y for the i PthP individual (district, entity) sampled
Distribution of Y B 1 B ,…, Y B n B under simple random sampling
· Because individuals #1 and #2 are selected at random, the value of Y B1B has no information content for Y B2B. Thus:
o Y B1B and Y B2B are independently distributed
o Y B1B and Y B2B come from the same distribution, that is, Y B1B, Y B2B are identically distributed
o That is, under simple random sampling, Y B1B and Y B2B are independently and identically distributed (i.i.d.).
o More generally, under simple random sampling, { Y B i B}, i = 1,…, n, are i.i.d.
This framework allows rigorous statistical inferences about moments of population distributions using a sample of data from that population …
1. The probability framework for statistical inference
3. Testing
4. Confidence Intervals
Estimation
 is the natural estimator of the mean. But:
is the natural estimator of the mean. But:
(a) What are the properties of ?
(b) Why should we use rather than some other estimator?
· Y B1B (the first observation)
· maybe unequal weights – not simple average
· median(Y B1B,…, Y B n B)
The starting point is the sampling distribution of …
(a) The sampling distribution of
is a random variable, and its properties are determined by the sampling distribution of
· The individuals in the sample are drawn at random.
· Thus the values of (Y B1B,…, Y B n B) are random
· Thus functions of (Y B1B,…, Y B n B), such as , are random: had a different sample been drawn, they would have taken on a different value
· The distribution of over different possible samples of size n is called the sampling distribution of .
· The mean and variance of are the mean and variance of its sampling distribution, E () and var().
· The concept of the sampling distribution underpins all of econometrics.
The sampling distribution of , ctd.
Example: Suppose Y takes on 0 or 1 (a Bernoulli random variable) with the probability distribution,
Pr[ Y = 0] =.22, Pr(Y =1) =.78
Then
E (Y) = p ´1 + (1 – p)´0 = p =.78
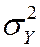 = E [ Y – E (Y)]2 = p (1 – p) [remember this?]
= E [ Y – E (Y)]2 = p (1 – p) [remember this?]
=.78´(1–.78) = 0.1716
The sampling distribution of depends on n.
Consider n = 2. The sampling distribution of is,
Pr( = 0) =.222 =.0484
Pr( = ½) = 2´.22´.78 =.3432
Pr( = 1) =.782 =.6084
The sampling distribution of when Y is Bernoulli (p =.78):
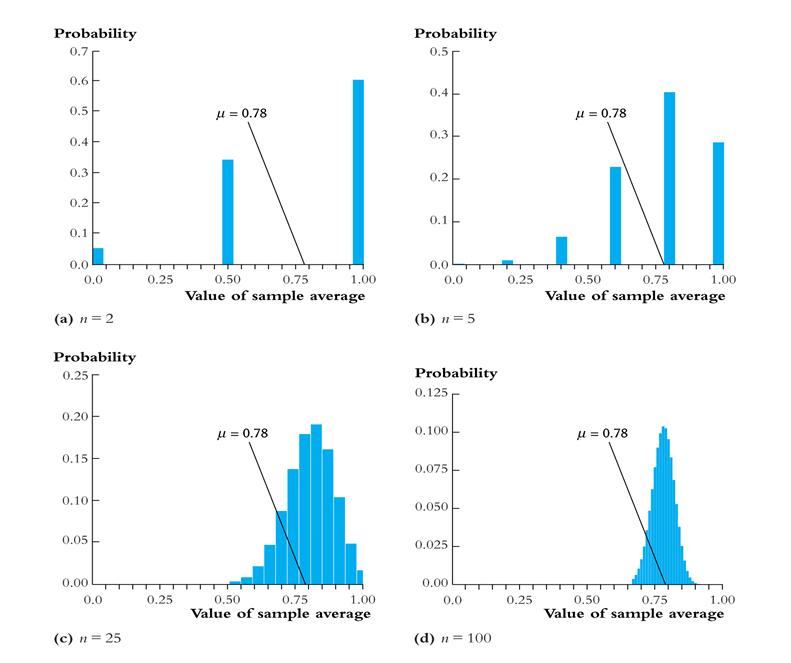
Things we want to know about the sampling distribution:
· What is the mean of ?
o If E () = true m =.78, then is an unbiased estimator of m
· What is the variance of ?
o How does var() depend on n (famous 1/ n formula)
· Does become close to m when n is large?
o Law of large numbers: is a consistent estimator of m
· – m appears bell shaped for n large…is this generally true?
o In fact, – m is approximately normally distributed for n large (Central Limit Theorem)
The mean and variance of the sampling distribution of
General case – that is, for Yi i.i.d. from any distribution, not just Bernoulli:
mean: E () = E (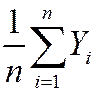 ) =
) = 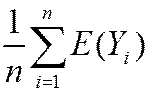 =
= 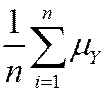 = mY
= mY
Variance: var() = E [– E ()]2
= E [– mY ]2
= E
= E 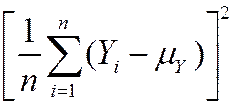
so var() = E
= 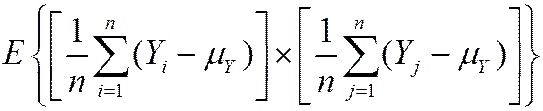
= 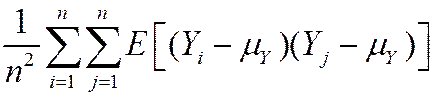
= 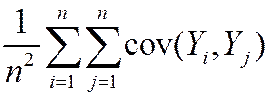
= 
= 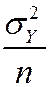
Mean and variance of sampling distribution of , ctd.
E () = mY
var() =
Implications:
1. is an unbiased estimator of mY (that is, E () = mY)
2. var() is inversely proportional to n
· the spread of the sampling distribution is proportional to 1/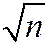
· Thus the sampling uncertainty associated with is proportional to 1/(larger samples, less uncertainty, but square-root law)
The sampling distribution of when n is large
For small sample sizes, the distribution of is complicated, but if n is large, the sampling distribution is simple!
1. As n increases, the distribution of becomes more tightly centered around mY (the Law of Large Numbers)
2. Moreover, the distribution of – mY becomes normal (the Central Limit Theorem)
The Law of Large Numbers:
An estimator is consistent if the probability that its falls within an interval of the true population value tends to one as the sample size increases.
If (Y 1,…, Yn) are i.i.d. and < ¥, then is a consistent estimator of mY, that is,
Pr[| – mY | < e ] ® 1 as n ® ¥
which can be written, 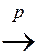 mY
mY
(“ mY ” means “ converges in probability to mY ”).
(the math: as n ® ¥, var() = ® 0, which implies that Pr[| – mY | < e ] ® 1.)
The Central Limit Theorem (CLT):
If (Y 1,…, Yn) are i.i.d. and 0 < < ¥, then when n is large the distribution of is well approximated by a normal distribution.
· is approximately distributed N (mY, ) (“normal distribution with mean mY and variance / n ”)
· (– mY)/ sY is approximately distributed N (0,1) (standard normal)
· That is, “standardized” = 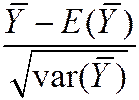 =
= 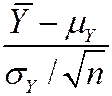 is approximately distributed as N (0,1)
is approximately distributed as N (0,1)
· The larger is n, the better is the approximation.
Sampling distribution of when Y is Bernoulli, p = 0.78:
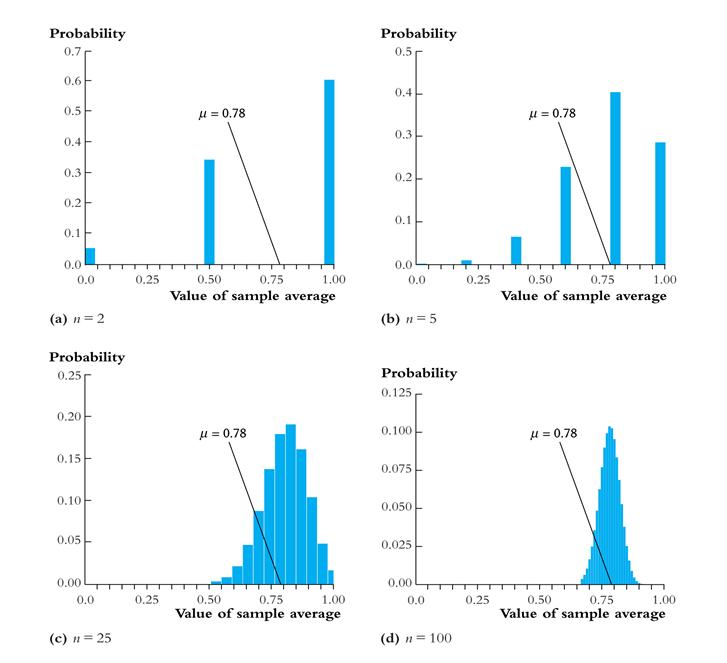
Same example: sampling distribution of :

Summary: The Sampling Distribution of
For Y 1,…, Yn i.i.d. with 0 < < ¥,
· The exact (finite sample) sampling distribution of has mean mY (“is an unbiased estimator of mY ”) and variance / n
· Other than its mean and variance, the exact distribution of is complicated and depends on the distribution of Y (the population distribution)
· When n is large, the sampling distribution simplifies:
o mY (Law of large numbers)
o is approximately N (0,1) (CLT)
(b) Why Use To Estimate mY?
· isunbiased: E () = mY
· is consistent: mY
· is the “least squares” estimator of mY; solves,
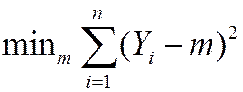
so, minimizes the sum of squared “residuals”
optional derivation (also see App. 3.2)
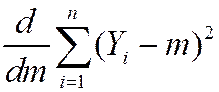 =
= 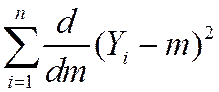 =
= 
Set derivative to zero and denote optimal value of m by 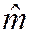 :
:
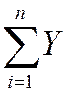 =
= 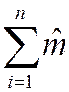 =
= 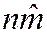 or = =
or = =
Why Use To Estimate mY, ctd.
· has a smaller variance than all other linear unbiased estimators: consider the estimator, 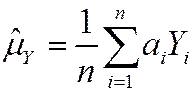 , where { ai } are such that
, where { ai } are such that 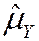 is unbiased; then var() £ var() (proof: SW, Ch. 17)
is unbiased; then var() £ var() (proof: SW, Ch. 17)
· isn’t the only estimator of mY – can you think of a time you might want to use the median instead?
1. The probability framework for statistical inference
2. Estimation
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 394; Нарушение авторских прав?; Мы поможем в написании вашей работы!