КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Регистры специальных функций
|
|
|
|
| Наименование | Назначение | Адрес |
| P 0* | Порт 0 | 80 H |
| SP | Регистр–указатель стека | 81 H |
| DPL | Младший байт регистра–указателя данных DPTR | 82 H |
| DPH | Старший байт регистра–указателя данных DPTR | 83 H |
| PCON | Регистр управления потреблением | 87 H |
| TCON* | Регистр управления/состояния таймера/счетчика | 88 H |
| TMOD | Регистр режима таймеров/счетчиков | 89 H |
| TL 0 | Таймер/счетчик 0. Младший байт | 8 АH |
| TL 1 | Таймер/счетчик 1. Младший байт | 8 BH |
| TH 0 | Таймер/счетчик 0. Старший байт | 8 CH |
| TH 1 | Таймер/счетчик 1. Старший байт | 8 DH |
| P 1* | Порт 1 | 90 H |
| SCON* | Регистр управления последовательного порта | 98 H |
| SBUF | Буфер последовательного порта | 99 H |
| P 2* | Порт 2 | 0 A 0 H |
| IE * | Регистр разрешения прерываний | 0 A 8 H |
| P 3* | Порт 3 | 0 B 0 H |
| IP * | Регистр приоритетов прерываний | 0 B 8 H |
| PSW* | Регистр состояния программы | 0 D 0 H |
| A* | Аккумулятор | 0 E 0 H |
| B* | Регистр B | 0F0 H |
* – регистры, допускающие побитовую адресацию.
9.4. Порты ввода/вывода информации
Четыре 8-разрядных двунаправленных порта ввода/вывода P 0, P 1, P 2, P 3предназначены для обмена информацией МК с внешними устройствами. Порты адресуются как регистры специальных функций. Каждая линия (группа линий) портов может быть использована индивидуально для ввода или вывода информации. Для того чтобы некоторая линия (группа линий) порта использовалась для ввода, в соответствующий разряд (группу разрядов) этого порта необходимо записать 1.
Порты P 0, P 2, P 3 могут выполнять ряд дополнительных функций.
9.5. Организация таймеров/счетчиков
МК Intel 8051 содержит два программируемых 16-разрядных таймера/счетчика (Т/Cч0 и T/Cч1). Каждый из них состоит из двух доступных по записи и чтению регистров специальных функций THx и TLx (x = 0, 1), предназначенных для хранения текущего содержимого таймеров/счетчиков.
Таймеры/счетчики (Т/Сч) могут быть использованы как в качестве таймеров, так и в качестве счетчиков внешних событий. В первом случае содержимое соответствующего Т/Сч инкрементируется в каждом машинном цикле, т. е. через 12 периодов тактового генератора. Во втором случае содержимое Т/Сч инкрементируется под воздействием перехода из 1 в 0 внешнего сигнала, подаваемого на соответствующий вход (Т 0, Т 1) МК. При этом максимальная частота регистрируемых сигналов не должна превышать 1/24 частоты тактового генератора МК. Для надежной регистрации каждое значение входного сигнала должно удерживаться как минимум в течение одного машинного цикла.
Признаком окончания счета, как правило, является переполнение регистров TH и TL. При этом устанавливается в единицу флаг переполнения таймера/счетчика TF. Если прерывания разрешены, управление передается подпрограмме, обслуживающей источник прерывания. По окончании этой подпрограммы управление возвращается прерванной программе. Кроме того, регистры TH и TL доступны не только по записи, но и по чтению. Поэтому контроль достижения тем или иным таймером/счетчиком заданной величины можно осуществлять программным путем.
Для выбора режимов работы таймеров/счетчиков и управления их работой используются два регистра специальных функций (TMOD – регистр режимов работы и TCON – регистр управления/состояния).
Регистр TMOD устанавливает один из четырех возможных режимов работы таймеров/счетчиков, работу каждого таймера/счетчика в режиме таймера или в режиме счетчика внешних событий. Он также обеспечивает возможность управления таймерами/счетчиками внешними сигналами. Наименование и назначение разрядов регистра TMOD приведены в табл. 9.3.
Регистр TCON предназначен для приема и хранения команды, управляющей работой таймеров/счетчиков. Наименование и назначение разрядов регистра TCON приведены в табл. 9.4.
Для обоих таймеров/счетчиков режимы 0, 1 и 2 одинаковы, режимы 3 – различны.
Таймер/счетчик T/Cч в режиме 0 (1) представляет собой устройство на основе 13- (16-) разрядного регистра, состоящего из 8 разрядов регистра TH и 5 младших разрядов (8 разрядов) регистра TL.
| Таблица 9.3 Регистр TMOD | ||
| Биты | Наименование | Назначение |
| GATE 1 | Бит разрешения (GATE 1 = 1)/запрещения (GATE 1 = 0) управления T/Cч1 от внешнего вывода 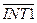
| |
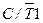
| Бит выбора режима работы T/Cч1 в качестве таймера (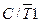 = 0) или в качестве счетчика внешних событий ( = 0) или в качестве счетчика внешних событий (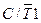 = 1) = 1)
| |
| М 1.1 М 0.1 | Биты выбора одного из четырех режимов работы T/Cч1 | |
| M 1.1 | M 0.1 | Режим |
| GATE 0 | Бит разрешения (GATE0 = 1)/запрещения (GATE 0 = 0) управления T/Cч0 от внешнего вывода 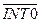
| |
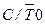
| Бит выбора режима работы T/Cч0 в качестве таймера (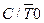 = 0) или в качестве счетчика внешних событий ( = 0) или в качестве счетчика внешних событий (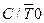 = 1) = 1)
| |
| М 1.0 М 0.0 | Биты выбора одного из четырех режимов работы T/Cч0 (аналогично Т/Сч1) |
| Таблица 9.4 Регистр TCON | ||
| Биты | Наименование | Назначение |
| TF 1 | Флаг переполнения T/Cч1 | |
| TR 1 | Бит включения T/Cч1 TR 1 = 1 – включен, TR 1 = 0 – выключен | |
| TF 0 | Флаг переполнения T/Cч0 | |
| TR 0 | Бит включения T/Cч0 TR 0 = 1 – включен, TR 0 = 0 – выключен | |
| IE 1 | Флаг запроса внешнего прерывания 
| |
| IT 1 | Бит выбора типа прерывания
IT 1 = 0 – прерывание по уровню (низкому),
IT 1 = 1 – прерывание по переходу из «1» в «0»
| |
| IE 0 | Флаг запроса внешнего прерывания 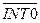
| |
| IT 0 | Бит выбора типа прерывания
IT 0 = 0 – прерывание по уровню (низкому),
IT 0 = 1 – прерывание по переходу из «1» в «0»
|
В режиме 2 T/Cч представляет собой устройство на основе 8-раз-рядного регистра TL. При каждом переполнении регистра TL устанавливается флаг переполнения TF и происходит автозагрузка регистра TL содержимым регистра TH, при этом содержимое регистра TH не изменяется.
Таймер/счетчик T/Cч1 в режиме 3 заблокирован (значение кода в регистрах TH 1, TL 1 не изменяется). Таймер/счетчик T/Cч0 в режиме 3 представляет собой два независимых устройства на основе регистров TH 0 и TL 0. Устройство на основе TL 0 может работать в режиме таймера или в режиме счетчика и при переполнении устанавливает флаг TF 0. За этим устройством сохраняются биты управления TR 0, GATE 0, 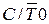 . Устройство на основе регистра TH 0 может работать только в режиме таймера. Оно использует бит включения TR 1, при переполнении выставляет флаг TF 1. Других битов управления устройство на основе TH 0 не имеет.
. Устройство на основе регистра TH 0 может работать только в режиме таймера. Оно использует бит включения TR 1, при переполнении выставляет флаг TF 1. Других битов управления устройство на основе TH 0 не имеет.
9.6. Универсальный асинхронный приемопередатчик
Последовательный порт МК Intel 8051 – универсальный асинхронный приемопередатчик (УАПП) – обеспечивает прием и передачу информации, представленной в последовательном коде. В состав УАПП входят передающий и принимающий сдвигающие регистры, буфер приемника и передатчика SBUF и блок управления работой приемопередатчика с регистром управления SCON. Запись подлежащего передаче байта данных в буфер передатчика SBUF приводит к его автоматической загрузке в сдвигающий регистр передатчика, к преобразованию данных из параллельного кода в последовательный код и добавлению (в случае необходимости) служебных битов. Сформированная таким образом последовательность битов подается на выход УАПП.
Сдвигающий регистр приемника принимает данные, поступающие на вход УАПП в последовательном коде, преобразует их в параллельный код, очищает (в случае необходимости) от служебных битов. Полученный в результате байт данных записывается в буфер приемника. Принятое из канала слово считывается в ЦП МК из буфера приемника.
УАПП может работать в четырех режимах. В режиме 0 УАПП реализует полудуплексный синхронный канал передачи данных, а в режимах 1, 2 и 3 – дуплексный асинхронный канал.
Настройка УАПП на определенный режим работы осуществляется путем загрузки соответствующего управляющего слова в регистр управления УАПП SCON. Наименование и назначение разрядов регистра SCON приведены в табл. 9.5.
| Таблица 9.5 Регистр SCON | |||
| Биты | Наименование | Назначение | |
| SM 0 SM 1 | Биты выбора режима работы | ||
| SM 0 | SM 1 | Режим | Характеристика режима |
| синхронный | |||
| 8 бит, асинхронный, скорость переменная | |||
| 9 бит, асинхронный, скорость f ГТИ/64 или f ГТИ/32 | |||
| 9 бит, асинхронный, скорость переменная | |||
| SM 2 | Бит разрешения многопроцессорной работы | ||
| REN | Бит разрешения приема. REN = 1 – прием разрешен, REN = 0 – прием запрещен | ||
| TB 8 | Девятый бит передаваемых в режимах 2, 3 данных | ||
| RB 8 | Девятый бит принятых в режимах 2, 3 данных | ||
| TI | Флаг прерывания передатчика | ||
| RI | Флаг прерывания приемника |
Режим 0. Режим последовательной синхронной передачи данных. Каждый передаваемый бит данных сопровождается импульсом синхронизации, информирующим приемник о наличии в линии информационного бита.
Реализуется полудуплексный канал связи. Данные поступают через внешний вывод приемника RxD в обе стороны (т. е. и передаются, и принимаются), но в каждый конкретный момент времени только в одну сторону. На выходе передатчика TxD формируются тактовые импульсы синхронизации, стробирующие передаваемые или принимаемые биты.
Во всех остальных режимах работы УАПП реализуется полнодуплексный канал связи, причем асинхронная передача и прием могут вестись одновременно с одинаковой или разной скоростью.
В нулевом режиме работы обеспечивается максимальная скорость передачи данных УАПП. За один МЦ УАПП передает один бит информации.
Режим 1. Режим последовательной асинхронной передачи данных. Используемый стандартный формат содержит 8 передаваемых битов информации и два специальных служебных бита, называемых стартовым и стоповым. Информация передается через вывод TxD, а принимается через вывод RxD. Скорость приема/передачи является переменной и задается таймером/счетчиком Т/Сч1.
До начала передачи символа на выводе TxD формируется логическая 1. Первый передаваемый бит всегда имеет нулевое значение и является стартовым битом. Приняв его, приемная сторона подстраивает фазу своих синхросигналов в соответствии с моментом прихода стартового бита. После стартового бита один за другим следуют 8 битов данных. Завершается передача стоповым битом, имеющим всегда единичное значение. Формат передачи десятичного числа 95, представленного двоично-десятичным кодом 8-4-2-1, приведен на рис. 9.5.
Режим 2. Режим 2, как и режим 1, является режимом последовательной асинхронной передачи данных. Отличается от режима 1 наличием девятого программируемого бита данных, предназначенного для организации обмена данными в мультиконтроллерных системах. При передаче значение этого бита берется из бита TB 8, а при приеме записывается в бит RB 8 регистра SCON. Частота приема/передачи может быть выбрана равной 1/32 или 1/64 частоты тактового генератора МК.

Режим 3. Режим 3 идентичен режиму 2 с тем отличием, что скорость приема/передачи является переменной и задается Т/Сч1.
Синхронизация ЦП МК с УАПП осуществляется с помощью флагов прерывания приемника и передатчика. Флаг RI прерываний приемника аппаратно устанавливается в конце времени приема 8-го бита данных в режиме 0 УАПП или через половину времени приема стоп бита в остальных режимах работы УАПП. Флаг TI прерываний передатчика устанавливается аппаратно в конце выдачи 8-го бита в режиме 0 или в начале передачи стоп бита в остальных режимах работы УАПП.
9.7. Система прерываний
Система прерываний МК Intel 8051 обеспечивает возможность аппаратного прерывания от двух внешних источников (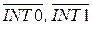 ) прерывания и четырех внутренних источников прерывания. К внутренним источникам относятся передатчик УАПП, приемник УАПП, Т/Сч0 и Т/Сч1.
) прерывания и четырех внутренних источников прерывания. К внутренним источникам относятся передатчик УАПП, приемник УАПП, Т/Сч0 и Т/Сч1.
Запрос любого источника прерывания заставляет ЦП микроконтроллера прервать выполнение текущей программы и перейти к выполнению специальной подпрограммы обслуживания прерывания. По окончании подпрограммы ЦП возвращается к выполнению прерванной программы.
Запросы прерываний от внутренних источников генерируются в соответствии с принципами работы устройств, их генерирующих.
Для приема внешних запросов на прерывание служат линии 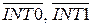 . При возникновении внешнего запроса прерывания устанавливается флаг прерывания IE 0 или флаг прерывания IE 1 соответственно. Для обнаружения запроса требуемые уровни сигналов должны присутствовать на входе в течение как минимум одного машинного цикла.
. При возникновении внешнего запроса прерывания устанавливается флаг прерывания IE 0 или флаг прерывания IE 1 соответственно. Для обнаружения запроса требуемые уровни сигналов должны присутствовать на входе в течение как минимум одного машинного цикла.
 |
Каждый источник имеет свой, фиксированный вектор прерывания (табл. 9.6). Под вектором прерывания в данном случае понимается ячейка памяти программ с фиксированным адресом, которой передается управление в случае прихода соответствующего запроса прерывания.
Прерывания могут быть вызваны или отменены программно, так как все выше перечисленные флаги программно доступны по записи и чтению.
Каждому источнику прерывания может быть программно присвоен высокий или низкий уровень приоритета.
Прерывание каждого источника прерывания можно индивидуально разрешить или запретить.
 |
Лекция 10
 СИСТЕМА КОМАНД МИКРОКОНТРОЛЛЕРОВ СЕМЕЙСТВА MCS -51
СИСТЕМА КОМАНД МИКРОКОНТРОЛЛЕРОВ СЕМЕЙСТВА MCS -51
Система команд МК семейства MCS -51 содержит 111 базовых команд, которые по функциональному признаку можно подразделить на пять групп:
– команды передачи данных;
– команды арифметических операций;
– команды логических операций;
– команды операций с битами;
– команды передачи управления.
Формат команд одно-, двух- и трехбайтовый, причем большинство команд имеет формат один или два байта. Первый байт команд любого формата всегда содержит код операции, второй и третий байты содержат либо адреса операндов, либо непосредственные операнды.
Операнды могут быть четырех типов: биты, ниблы (4 разряда), байты и 16-битные слова.
МК семейства MCS -51 имеют 128 программно управляемых флагов пользователя и отдельные биты регистров специальных функций (в том числе и биты параллельных портов ввода/вывода).
Четырехразрядные операнды используются только в командах SWAP и XCHD, осуществляющих операции обмена.
К однобайтным операндам относятся ячейки памяти программ и ячейки памяти данных, непосредственные операнды (константы) и регистры специальных функций (в том числе и параллельные порты ввода/вывода).
К шестнадцатиразрядным операндам относятся константы и прямые адреса.
Время исполнения команд составляет 1, 2 или 4 машинных цикла.
При описании системы команд используются мнемокоды языка ассемблера.
10.1. Способы адресации
Набор команд МК семейства MCS -51 поддерживает следующие способы адресации данных.
Прямая адресация. В коде команд с прямой адресацией содержится прямой 8-битный адрес байта РПД (0–127) или РСФ. Примером таких команд может служить команда MOV A, ad. Эта команда обеспечивает загрузку содержимого ячейки РПД (содержимого РСФ), адрес которой (которого) указан во втором байте кода команды, в аккумулятор. Формат команды MOV A, 75 Н приведен на рис. 10.1, а ее операционная схема –
 |
на рис. 10.2.
 |
Двухбайтная команда хранится в смежных ячейках РПП, код операции – по адресу N, адрес ячейки РПД (75 Н), содержимое которой (34 Н) необходимо загрузить в аккумулятор А – по адресу N + 1. Перед выполнением команды адрес N должен быть загружен в счетчик команд РС.
В процессе выполнения этой команды ЦП МК читает содержимое ячейки РПП, адрес которой определяется содержимым счетчика команд РС, увеличивает его содержимое на 1 и пересылает считанный КОП в регистр команд ЦП. Далее ЦП читает содержимое ячейки РПП по адресу N + 1 (75 Н) и снова увеличивает содержимое счетчика команд на 1, читает содержимое (34 Н) ячейки РПД по адресу 75 Н и загружает его в аккумулятор, т. е. в РСФ по адресу 0 ЕН. После этого ЦП приступает к выборке следующей команды, хранящейся в РПП по адресу N + 2.
 Регистровая адресация. В коде команд с регистровой адресацией находится трехбитный адрес одного из регистров текущего банка РОН. Выбор одного из четырех банков осуществляется программированием битов селектора банка (RS 1, RS 0) регистра PSW.
Регистровая адресация. В коде команд с регистровой адресацией находится трехбитный адрес одного из регистров текущего банка РОН. Выбор одного из четырех банков осуществляется программированием битов селектора банка (RS 1, RS 0) регистра PSW.
Примером команды с прямой адресацией может быть команда MOV A, R 1. Формат этой команды приведен на рис. 10.3, а ее операционная схема – на рис. 10.4.
 |
Команда MOV A, R 1 обеспечивает передачу содержимого регистра R 1 банка 0 РОН РПД в аккумулятор. Адрес этого регистра в команде, записанной на языке ассемблера, задан символическим именем R 1. В процессе выполнения этой команды ЦП МК читает содержимое ячейки РПП, адрес которой определяется содержимым счетчика команд РС, увеличивает его содержимое на 1 и пересылает считанный код команды в регистр команд ЦП. Код операции, занимающий пять старших битов кода команды, определяет дальнейшие действия ЦП МК по реализации данной команды. С учетом состояния битов селектора банка (RS 1, RS 0) регистра PSW и адресного поля кода команды ЦП определяет действительный адрес РОН, читает содержимое этого регистра и пересылает его в аккумулятор.
Команды с регистровой адресацией являются однобайтными и требуют однократного обращения к памяти программ. Однако они обеспечивают возможность обращения только к регистрам общего назначения.
Косвенная адресация. В случае косвенной регистровой адресации команда содержит адрес регистра, в котором находится действительный адрес операнда. Код команды, записанный на языке ассемблера, должен содержать признак косвенной регистровой адресации, в качестве которого используется символ «@». В качестве регистра косвенной регистровой адресации могут использоваться:
– при обращении к РПД регистры R 0 и R 1 текущего банка РОН;
– в командах, оперирующих со стеком, регистр-указатель стека SP;
– при обращении к внешней памяти данных регистры R 0 и R 1 текущего банка РОН или регистр-указатель данных DPTR.
 В качестве примера рассмотрим команду MOV A, @ R 0, обеспечивающую загрузку содержимого ячейки РПД, адрес которой находится в регистре R0 текущего банка РОН, в аккумулятор. Формат этой команды приведен на рис. 10.5, а операционная схема – на рис. 10.6 для случая первого текущего банка РОН.
В качестве примера рассмотрим команду MOV A, @ R 0, обеспечивающую загрузку содержимого ячейки РПД, адрес которой находится в регистре R0 текущего банка РОН, в аккумулятор. Формат этой команды приведен на рис. 10.5, а операционная схема – на рис. 10.6 для случая первого текущего банка РОН.
Для указания адреса регистра косвенной адресации в этой команде используется младший бит кода команды. Наличие 0 в этом разряде соответствует регистру R 0, наличие единицы – регистру R 1.
В процессе выполнения этой команды ЦП МК читает содержимое ячейки РПП, адрес которой определяется содержимым счетчика команд РС, увеличивает его содержимое на 1 и пересылает считанный код команды MOV A, @ R 0 в регистр команд ЦП. Код операции, занимающий семь старших битов кода команды, определяет дальнейшие действия ЦП МК по реализации данной команды. С учетом состояния битов селектора банка (RS 1, RS 0) регистра PSW и адресного поля кода команды ЦП определяет действительный адрес РОН, в котором находится адрес 20 Н ячейки РПД, в которой находится операнд, и читает содержимое этого регистра. Найденный таким образом адрес используется для чтения операнда и последующей его загрузки в аккумулятор.
 |
Непосредственная адресация. При непосредственной адресации операнд является частью кода команды. Команды с такой адресацией имеют двухбайтный формат, если операнд однобайтный, или трехбайтный формат, если операнд двухбайтный. Используются эти команды для загрузки регистров МК, для введения необходимых при вычислениях констант, для инициализации счетчиков и т. д.
В качестве примера команды с непосредственной адресацией рассмотрим команду MOV A, #56 H. Эта команда обеспечивает загрузку аккумулятора константой #56 H. Формат команды приведен на рис. 10.7, операционная схема – на рис. 10.8.
 |
Операнд содержится непосредственно в поле команды вслед за кодом операции и занимает один байт. В процессе выполнения этой команды ЦП МК читает из памяти программ код операции, затем второй байт кода команды и пересылает считанный операнд в аккумулятор.
Неявная адресация. Некоторые команды МК используют индивидуальные регистры (например, аккумулятор), при этом адрес этих регистров в явном виде непосредственно в коде команды не указан. Информация об адресе регистров в таких командах в неявном виде содержится в коде операции. Примерами таких команд являются ранее рассмотренные команды MOV A, R 1 и MOV A, #56 H, в которых используется неявная адресация аккумулятора А.
10.2. Команды передачи данных
Команды передачи данных обеспечивают обмен данными как внутри микроконтроллера, так и между различными устройствами микроконтроллерной системы. Они подразделяются на следующие подгруппы:
– команды обращения к РПД и РСФ;
– команды обращения к ВПД;
– команды обращения к памяти программ.
В табл. 10.1 приведены команды обращения к РПД и РСФ и применяемые при этом способы адресации.
Команда MOV A, src обеспечивает загрузку аккумулятора:
– содержимым любой ячейки РПД или любого РСФ с использованием прямой адресации (MOV A, ad);
– содержимым любой ячейки РПД с использованием косвенной регистровой адресации (MOV A, @ Ri);
– содержимым регистра текущего банка РОН РПД с использованием регистровой адресации (MOV A, Rn);
– константой с использованием непосредственной адресации
(MOV A, # d).
| Таблица 10.1 Команды обращения к РПД и РСФ | ||||||
| Мнемоника | Операция | Адресация | Время выполнения (МЦ) | |||
| Прямая | Косвенная | Регистровая | Непосред- ственная | |||
| MOV A, src | (A) ¬ (src) | х | х | х | х | |
| MOV dest, A | (dest) ¬ (A) | х | х | х | ||
| MOV dest, src | (dest) ¬ (src) | х | х | х | х | |
| MOV DPTR, # d 16 | (DPTR) ¬ # d 16 | х | ||||
| PUSH src | (SP) ¬ (SP) + 1 ((SP)) ¬ (src) | x | ||||
| POP dest | (dest) ¬ ((SP)) (SP) ¬ (SP) – 1 | x | ||||
| XCH A, byte | (A) ↔ (byte) | x | x | x | ||
| XCHD A, @ Ri | (A)0–3↔ ((Ri)0–3) | x |
Команда MOV dest, A обеспечивает загрузку содержимого аккумулятора в:
– любую ячейку РПД или в РСФ с использованием прямой адресации (MOV ad, A);
– любую ячейку РПД с использованием косвенной регистровой адресации (MOV @ Ri, A);
– регистр текущего банка РОН РПД с использованием регистровой адресации (MOV Rn, A).
Команда MOV dest, src позволяет пересылать данные между ячейками РПД, РОН или SFR без использования аккумулятора. При этом работа с РПД может осуществляться с использованием прямой и косвенной адресации, обращение к регистрам SFR – только прямой адресации, а обращение к РОН – только регистровой адресации.
Команды PUSH src и POP dеst обеспечивают загрузку в стековую память содержимого прямоадресуемой ячейки РПД или прямоадресуемого РСФ и их загрузку из стековой памяти соответственно.
Операция XCH A, byte применяется для обмена данными между аккумулятором и адресуемым байтом. Команда XCHD A, @ Ri выполняется только для младших тетрад (ниблов), участвующих в обмене аккумулятора и адресуемой ячейки РПД.
Для обращения к внешней памяти данных существуют 4 специальные команды MOVX (табл. 10.2), использующие только косвенную регистровую адресацию. В качестве регистров косвенной адресации могут использоваться регистры R 0 и R 1 текущего банка РОН или 16-разрядный регистр-указатель данных DPTR. При любом доступе к внешней памяти данных обмен информацией осуществляется исключительно через аккумулятор. Сигналы записи и чтения ВПД (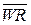 и
и 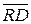 ) активизируются только во время выполнения команд MOVX.
) активизируются только во время выполнения команд MOVX.
| Таблица 10.2 Команды обращения к внешней памяти данных | |||
| Мнемоника | Операция | Адрес | Время выполнения (МЦ) |
| MOVX A, @Ri | (А) ¬ (ВПД(Ri)), i = 0,1 | 8 бит | |
| MOVX @Ri, A | (ВПД(Ri)) ¬ (А), i = 0,1 | 8 бит | |
| MOVX A, @DPTR | (А) ¬ (ВПД(DPTR)) | 16 бит | |
| MOVX @DPTR, A | (ВПД(DPTR)) ¬ (А) | 16 бит |
В табл. 10.3 приведены две единственные команды обращения к памяти программ. С их помощью возможно только чтение памяти программ, но не изменение ее содержимого.
| Таблица 10.3 Команды обращения к внешней памяти программ | ||
| Мнемоника | Операция | Время выполнения (МЦ) |
| MOVC A, @ A + DPTR | Чтение памяти программ по адресу (A + DPTR) | |
| MOVC A, @ A + PC | Чтение памяти программ по адресу (A + PC) |
10.3. Команды арифметических операций
Данную группу команд (табл. 10.4) образуют команды, выполняющие операции сложения, вычитания, умножения, деления, инкремента, декремента, десятичной коррекции результата, полученного при сложении десятичных чисел, представленных в двоично-десятичном коде 8-4-2-1.
В табл. 10.4 указаны способы адресации, которые используются для определения однобайтного операнда < byte >. Например, в команде ADD A, < byte > один операнд находится в аккумуляторе, второй операнд задается одним из четырех возможных способов адресации:
– ADD A, 7 FH; прямая адресация;
– ADD A, @ R 0; косвенная регистровая адресация;
– ADD A, R 7; регистровая адресация;
– ADD A, #7 F; непосредственная адресация.
Полученная сумма размещается в аккумуляторе.
По результату выполнения команд ADD, ADDC, SUBB, MUL и DIV устанавливаются флаги PSW.
Флаг основного переноса С устанавливается при переносе из разряда D 7, флаг вспомогательного переноса АС устанавливается при переносе из разряда D 3 в командах сложения и вычитания и служит для реализации десятичной арифметики. Этот признак используется командой DAA.
| Таблица 10.4 Команды арифметических операций | ||||||
| Мнемоника | Операция | Адресация | Время выполнения (МЦ) | |||
| Прямая | Косвенная | Регистровая | Непосредственная | |||
| ADD A, < byte > | (A) ¬ (A) + <byte> | х | х | х | х | |
| ADDC A, <byte> | (A) ¬ (A) + < byte> + (C) | х | х | х | х | |
| SUBB A, < byte > | (A) ¬ (A) – < byte > – (C) | х | х | х | х | |
| INC A | (A) ¬ (A) + 1 | Только аккумулятор | ||||
| INC < byte > | < byte > ¬ < byte> + 1 | х | х | х | ||
| INC DPTR | (DPTR) ¬ (DPTR) + 1 | Только DPTR | ||||
| DEC A | A ¬ A – 1 | Только аккумулятор | ||||
| DEC <byte> | <byte > ¬ < byte> – 1 | х | х | х | ||
| MUL AB | (B)(A) ¬ (B)∙(A) | Только аккумулятор и регистр В | ||||
| DIV AB | (A) ¬ Int [ (A)/(B)], (B) ¬ Mod [ (A)/(B) ] | Только аккумулятор и регистр В | ||||
| DA A | Десятичная коррекция | Только аккумулятор |
Флаг переполнения OV устанавливается при переносе из разряда D 6. Этот признак служит для организации обработки чисел со знаком.
Флаг паритета Р устанавливается и сбрасывается аппаратно. Если число единичных бит в аккумуляторе нечетно, то Р = 1, в противном случае Р = 0.
10.4. Команды логических операций
Команды логических операций (табл. 10.5) выполняют логические операции поразрядно. Исходный операнд находится в аккумуляторе, второй операнд задается одним из четырех возможных способов адресации (прямым, косвенным регистровым, регистровым и непосредственным). Результат операции возвращается в аккумулятор.
Исходный операнд может быть и прямоадресуемым байтом. Вторым операндом в этом случае является содержимое аккумулятора или константа, а результат логической операции замещает первый операнд.
| Таблица 10.5 Команды логических операций | ||||||
| Мнемоника | Операция | Адресация | Время выполнения (МЦ) | |||
| Прямая | Косвенная | Регистровая | Непосредственная | |||
| ANL A, < byte > | A ¬ A Ù < byte > | х | х | х | х | |
| ANL < byte >, A | < byte > ¬ < byte > Ù A | х | ||||
| ANL < byte >, # data | < byte > ¬ < byte > Ù # data | х | ||||
| ORL A, < byte > | A ¬ A Ú < byte > | х | х | х | х | |
| ORL < byte >, A | < byte > ¬ < byte > Ú A | x | ||||
| ORL < byte >, # data | < byte > ¬ < byte > Ú # data | x | ||||
| XRL A, < byte > | A ¬ A Å < byte > | x | x | x | x | |
| XRL < byte >, A | < byte > ¬ < byte > Å A | x | ||||
| XRL < byte >, # data | < byte > ¬ < byte > Å # data | x | ||||
| CLRA | A ¬ 00 H | Только аккумулятор | ||||
| CPLA | A ¬ 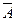
| Только аккумулятор | ||||
| RLA | Сдвиг (А) влево | Только аккумулятор | ||||
| RLCA | Сдвиг (А) влево через С | Только аккумулятор | ||||
| RRA | Сдвиг (А) вправо | Только аккумулятор | ||||
| RRCA | Сдвиг (А) вправо через С | Только аккумулятор | ||||
| SWAPA | (А 0–3) ↔ (А 4–7) | Только аккумулятор |
10.5. Команды операций с битами
РПД имеет 128 прямо адресуемых бит, пространство РСФ содержит еще 128 адресуемых флагов. Все линии портов ввода/вывода являются адресуемыми битами и каждая из них может использоваться как независимый однобитный порт ввода/вывода. Все указанные биты доступны в режиме прямой адресации.
Команды, обеспечивающие доступ ко всем этим битам, обеспечивают передачу, установку, сброс, инверсию и выполнение логических операций И, ИЛИ (табл. 10.6).
В данную группу команд включены команды условных переходов, в которых условия перехода определяются состоянием флага С или прямо адресуемого бита (bit). Однобитный относительный адрес передачи управления –127 ≤ rel ≤ +128 является вторым байтом во всех командах операций с битами. В случае выполнения условия переход выполняется по адресу (РС) ← (РС) + rel.
10.6. Команды передачи управления
Команды этой группы используются для изменения естественного порядка следования команд и организации циклических участков в программах. К ним относятся команды безусловных и условных переходов, вызова подпрограммы и выхода из подпрограммы.
| Таблица 10.6 Команды операций с битами | ||
| Мнемоника | Операция | Время выполнения (МЦ) |
| ANL C, bit | C ← C Ù bit | |
ANL C, 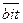
| C ← C Ù ()
| |
| ORL C, bit | C ← C Ú bit | |
| ORL C,
| C ← C Ú ()
| |
| MOV C, bit | C ← bit | |
| MOV bit, C | bit ← C | |
| CLRC | C ← 0 | |
| CLR | bit ← 0 | |
| SETB C | C ← 1 | |
| SETB bit | bit ← 1 | |
| CPL C | C ←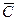
| |
| CPL bit | bit ←
| |
| JC rel | Jump if C = 1 | |
| JNC rel | Jump if C = 0 | |
| JB bit, rel | Jump if bit = 1 | |
| JNB bit, rel | Jump if bit = 0 | |
| JBC bit, rel | Jump if bit = 1; bit ← 0 |
В результате выполнения команд безусловных переходов управление передается команде по новому адресу вне зависимости от выполнения или невыполнения каких-либо условий. Команда безусловного перехода JMP addr (табл. 10.7) имеет 3 разновидности (SJMP, LJMP и AJMP), различающиеся форматом адреса перехода.
| Таблица 10.7 Команды безусловных переходов | ||
| Мнемоника | Операция | Время выполнения (МЦ) |
| JMP | Переход по адресу addr | |
| JMP @ A+DPTR | Переход по адресу @ A + DPTR | |
| CALL addr | Вызов подпрограммы | |
| RET | Выход из подпрограммы | |
| RETI | Выход из подпрограммы, обслуживающей прерывание | |
| NOP | Пустая операция |
Команда короткого перехода (SJMP) позволяет передать управление в пределах от –128 до +127 байтов относительно адреса команды, следующей за командой SJMP.
Команда длинного перехода (LJMP) предоставляет возможность перехода по любому адресу из 64 Кбайтов памяти программ.
Команда абсолютного перехода (AJMP) позволяет передать управление в пределах одной страницы памяти программ размером 2048 байтов.
Существует две разновидности команды вызовы подпрограммы CALL: LCALL и ACAL L. При использовании команды LCALL подпрограмма может быть расположена в любом месте памяти программ. В случае команды ACALL вызываемая подпрограмма должна быть расположена в одном двухкилобайтном блоке с командой, следующей за командой ACALL.
Подпрограмма завершается командой RET, позволяющей вернуться в исходную программу к выполнению команды, следующей за командой CALL. Команда RETI используется для возврата из подпрограмм обработки прерываний.
Команды условного перехода осуществляют передачу управления только в случае выполнения (невыполнения) определенного условия. В противном случае, т. е. при невыполнении (выполнении) этого условия, выполняется команда, следующая в программе за командой условного перехода.
Перечень команд условных переходов приведен в табл. 10.8. Все команды условных переходов определяют адрес назначения как относительное смещение (rel) с длиной перехода, находящейся в пределах от –128 до +127 байтов (относительно команды, следующей за командой условного перехода).
| Таблица 10.8 Команды условных переходов | ||||||
| Мнемоника | Операция | Адресация | Время выполнения (МЦ) | |||
| Прямая | Косвенная | Регистровая | Непосредственная | |||
| JZ rel | Переход, если A = 0 | Только аккумулятор | ||||
| JNZ rel | Переход, если A ≠ 0 | Только аккумулятор | ||||
| DJNZ < byte >, rel | Декремент и переход, если не нуль | х | х | |||
| CJNE A, < byte >, rel | Переход, если (A) ≠ < byte > | х | х | |||
| CJNE < byte > # data, rel | Переход, если < byte > ≠ data | х | х |
 |
Лекция 11
ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ
ИНТЕГРАЛЬНЫЕ СХЕМЫ
Появившиеся в начале 70-х годов программируемые постоянные запоминающие устройства (ППЗУ) первоначально использовались исключительно по своему прямому назначению. Позже их стали применять для реализации булевых функций. Однако ограниченная емкость ППЗУ не позволяла реализовывать системы булевых функций большого числа переменных. Для решения этой задачи в 1971 г. программируемые логические матрицы (ПЛМ, PLA) стали выпускаться промышленностью. Их можно считать первыми программируемыми логическими устройствами (PLD), получившими очень широкое распространение в качестве универсальной элементной базы цифровых систем.
Совершенствование архитектуры ПЛМ привело к появлению программируемых матриц логики (ПМЛ, PAL), практически полностью вытеснивших программируемые логические матрицы.
Дальнейшее совершенствование технологии производства интегральных схем привело к возможности реализации на одном кристалле нескольких PAL, объединяемых программируемыми соединениями. Подобные программируемые логические интегральные схемы (ПЛИС) получили название сложных PLD (CPLD), а все ранее разработанные PLD стали называть стандартными PLD (SPLD), или классическими PLD.
Параллельно с PLD развивались архитектуры вентильных матриц, в русскоязычной литературе получившие название базовых матричных кристаллов. Первые вентильные матрицы были полузаказными, т. е. программировались во время изготовления, что сдерживало их широкое практическое использование. Однако в 1985 году фирма Xilinx выпустила программируемую пользователем вентильную матрицу (FPGA). Это дало сильный толчок к широкому распространению вентильных матриц и конкуренции их с PLD.
Программируемые логические интегральные схемы (ПЛИС) принято делить на три класса: стандартные (классические) PLD, сложные PLD и программируемые пользователем вентильные матрицы.
11.1. Основные свойства ПЛИС
Основные характеристики ПЛИС:
– низкая стоимость, приближающаяся к стоимости стандартных цифровых устройств;
– высокое быстродействие, характеризующееся задержкой прохождения сигнала через ПЛИС, равной 3,5 нс, и позволившее достичь частоты функционирования устройств в 250 МГЦ;
– значительные функциональные возможности, позволяющие стандартным PLD заменять десятки корпусов «жесткой» логики, а сложным PLD – сотни корпусов «жесткой» логики;
– универсальность, позволяющая применять ПЛИС одного типа для построения различных функциональных узлов (комбинационных, регистровых, арифметических и др.);
– многократность программирования, достигающая 100–1000 раз в зависимости от технологии производства и типа настраиваемого элемента;
– возможность перенастройки во время функционирования системы, реализованной на CPLD, в которых в качестве настраиваемых элементов используются статические ОЗУ, позволяющая строить различные адаптивные системы;
– малое (порядка 3–5 часов для проекта средней сложности) время проектирования.
Процесс проектирования цифровых систем на основе ПЛИС состоит из четырех основных последовательно выполняемых этапов:
– ввод исходных данных для проектирования (ввод проекта);
– выполнение синтеза отдельных частей проекта и всего проекта в целом;
– моделирование проекта;
– программирование и тестирование.
Ввод проекта. Ввод исходных данных для проектирования заключается в описании одним из способов машинного представления всех частей проекта. Наибольшее распространение получили текстовый ввод, схемный ввод и ввод в виде временных диаграмм.
Текстовый ввод предполагает описание проекта или его части на некотором исходном языке используемого программного средства в виде текстового файла. Текстовый файл, как правило, включает заголовок, определение переменных и назначение им соответствующих выводов ПЛИС, а также описание функционирования устройства в виде структурных формул, алгоритма функционирования, таблицы истинности или конечного автомата.
С хемный ввод осуществляется с помощью графического редактора используемого программного средства. Для упрощения ввода принципиальных схем графический редактор, как правило, содержит библиотеки стандартных элементов жесткой логики. Имеется также библиотека параметризированных функциональных узлов (вентилей, шифраторов, дешифраторов, мультиплексоров, демультиплексоров, триггеров, регистров, счетчиков и т. д.).
Ввод проекта в виде временной диаграммы осуществляется с помощью графического редактора. Вначале определяются переменные (сигналы) проекта, а затем описывается поведение устройства в виде временной диаграммы.
Синтез проекта фактически заключается в компиляции его исходного описания во внутреннее представление используемого программного средства (файл). В последующем этот файл используется для моделирования.
Моделирование проекта на ПЛИС может осуществляться как на логическом, так и на физическом уровне. При моделировании на логическом уровне работоспособность проекта проверяется на основании математических моделей ПЛИС и выполняется программным обеспечением без участия конкретной микросхемы. На физическом уровне проверяется реальное функционирование проекта с использованием уже запрограммированных ПЛИС.
Программирование ПЛИС заключается в ее настройке на заданный алгоритм функционирования. Стандартные PLD программируются с помощью программаторов.
Сложные CPLD, в которых настраиваемым элементом является статическое ОЗУ, программируются всякий раз при включении питания.
11.2. Стандартные PLD
Большинство стандартных PLD условно можно представить состоящими из двух матриц взаимно ортогональных проводников: матрицы И и матрицы ИЛИ. Входные сигналы обычно поступают на входы матрицы И, которая позволяет реализовать любые конъюнкции входных переменных. Выходы матрицы И соединены с входами матрицы ИЛИ, которая на выходах реализует дизъюнкции поступающих сигналов.
К стандартным PLD принято относить программируемые постоянные запоминающие устройства, программируемые логические матрицы, программируемые матрицы логики и программируемые логические секвенсоры (PLS).
В ППЗУ (рис. 11.1) матрица И постоянно настроена на функции полного дешифратора.
Структуру ПЛМ можно представить в виде совокупности двух матриц взаимно ортогональных проводников (рис. 11.2). Входные сигналы поступают на вход матрицы И, которая позволяет сформировать любые конъюнкции n входных переменных. Совокупность входов логического элемента И на схеме представлена горизонтальной линией, пересекающей вертикальные линии, которые соответствуют прямым или инвертированным входным сигналам. Сигналы с выходов матрицы И поступают на входы матрицы ИЛИ, формирующей дизъюнкции этих сигналов. Совокупность входов элемента ИЛИ на рис. 11.2 обозначена вертикальной линией в коммутационном поле матрицы ИЛИ.

Матрицы И и ИЛИ имеют настраиваемую структуру. На каждый вход каждого ЛЭ И может быть подан через повторитель или инвертор любой из n входных сигналов и на каждый вход каждого ЛЭ ИЛИ может быть подан выходной сигнал каждого ЛЭ И. На рис. 11.2 эти соединения обозначены кружочком в месте пересечения ортогональных проводников.
Таким образом, ПЛМ путем настройки программируемых матриц И и ИЛИ на осуществление нужных наборов конъюнкций и дизъюнкций позволяет реализовать любую комбинационную схему с числом входов, не превышающим размерность матрицы И.
Основной недостаток ПЛМ – слабое использование ресурсов программируемой матрицы ИЛИ. Поэтому дальнейшее развитие получили программируемые матрицы логики PAL.
Программируемая матрица логики, структура которой приведена на рис. 11.3, содержит n входов, матрицу И, матрицу ИЛИ, m выходных буферов (программируемых макроячеек) и цепи обратной связи. Программируемая матрица И на своих выходах позволяет получать любые элементарные конъюнкции ее входных переменных. Выходы матрицы И подсоединены к входам матрицы ИЛИ. Матрица ИЛИ имеет фиксированную настройку. Каждый выход матрицы И связывается только с одним входом матрицы ИЛИ.
Программирование только одной матрицы И в ПМЛ значительно упростило ее структуру и, как следствие, привело к снижению стоимости устройства и повышению его быстродействия. Наличие в структуре ПМЛ цепей обратной связи и выходных буферов (программируемых макроячеек), таких как управляемые повторители, инверторы, триггеры, позволяет реализовать не только комбинационные, но и последовательностные схемы, а также увеличить число входов устройства.
Программируемые логические секвенсоры по своей структуре похожи на программируемые логические матрицы с памятью. Они предназначены для построения последовательностных схем.
 |
Выше перечисленные архитектуры ПЛИС содержат небольшое число ячеек, к настоящему времени морально устарели и применяются для реализации относительно простых устройств, для которых не существует готовых ИС средней степени интеграции.
11.3. Сложные программируемые логические устройства
К сложным программируемым логическим устройствам принято относить ПЛИС высокой степени интеграции, содержащие несколько логических блоков (ЛБ), объединенных коммутационной матрицей.
Наиболее популярными представителями этого класса ПЛИС являются КМОП-макроматрицы высокой плотности (MACH) фирмы Advanced Micro Devices (VANTIS), многократные матричные таблицы (MAX) и матрицы элементов гибкой логики (FLEX) фирмы Altera.
КМОП-макроматрицы высокой плотности – MACH-устройства. Структура MACH -устройств представляет собой совокупность PAL -бло-ков, объединенных матрицей переключений (рис. 11.4). Основные функциональные преобразования выполняются в PAL -блоках, а матрица переключений обеспечивает передачу сигналов между ними. Каждый PAL -блок имеет достаточно большое число двунаправленных внешних выводов. Выходные сигналы формируются с помощью программируемых макроячеек, имеющих обратные связи с матрицей И (рис. 11.3).
Кроме того, MACH -устройство имеет некоторое число специальных информационных входов, сигналы с которых через матрицу переключений могут быть поданы на любой PAL -блок. Синхронизация PAL -блоков осуществляется внешними сигналами, подаваемыми на входы С, которые в случае необходимости могут использоваться также в качестве обычных информационных входов.
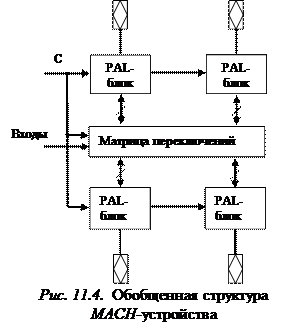 Характерной особенностью MACH -устройств является постоянная задержка прохождения сигнала с любого входа на любой выход.
Характерной особенностью MACH -устройств является постоянная задержка прохождения сигнала с любого входа на любой выход.
В настоящее время фирмой Advanced Micro Devices (VANTIS) разработано три поколения МАСН -устройств.
Первое поколение составляют семейства МАСН 1 и МАСН 2. Практически все элементы этих семейств являются синхронными. Они отличаются числом выводов (44–84), числом макроячеек (32–128), числом связей PAL -блоков с матрицей переключений (22–26), числом информационных входов (2–4) и входов синхронизации (2–8).
Второе поколение составляют семейства МАСН 3 и МАСН 4. В микросхемах этих семейств почти в 3 раза выше степень интеграции, в 2 раза увеличено число выводов по сравнению с MACH -устройствами первого поколения. Кроме того, увеличено общее число макроячеек (от 96 до 256), причем для каждой макроячейки возможен как синхронный режим работы, так и асинхронный.
При возрастании числа PAL -блоков сложно обеспечить необходимые соединения между ними без значительного увеличения размеров матрицы переключений. Поэтому в семействе МАСН 5, образующем третье поколение MACH -устройств, реализована двухуровневая архитектура соединений. Матрица переключений образована одной глобальной шиной и несколькими локальными шинами. Все PAL -блоки объединены в сегменты по 4 PAL-блока в каждом. Локальные шины обеспечивают соединения между PAL -блоками одного сегмента, а глобальная шина – между всеми сегментами.
Многократные матричные таблицы – МАХ-устройства. Рассмотрим архитектуру этих устройств на примере ПЛИС семейства МАХ 5000 фирмы Altera. Она представляет собой совокупность блоков логических матриц (Logic Array Blocks – LAB) или LAB -модулей, объединенных в одно устройство с помощью программируемой матрицы межсоединений (рис. 11.5). Каждый LAB -модуль имеет множество двунаправленных выводов. Блок управления вводом-выводом позволяет каждый двунаправленный вывод настраивать как вход, выход или оставлять двунаправленным выводом. Все LAB -модули пронизаны поступающими с входов
 |
ПЛИС сигналами синхронизации, сброса и установки в третье состояние каждой макроячейки.
Каждый LAB -модуль состоит из программируемой матрицы И, матрицы макроячеек и расширителя промежуточных шин матрицы И (рис. 11.6). Матрица макроячеек реализует комбинационные функции, объединяя сформированные программируемой матрицей И произведения по ИЛИ либо по исключающему ИЛИ. Предусмотрена настройка на комбинационный или регистровый выход. При этом образованный триггерами макроячеек регистр может эмулировать D -, T -, JK - или SR -триггеры.
Расширитель промежуточных шин обеспечивает возможность реализации функций ИЛИ от большого числа переменных. Он может быть также использован для построения дополнительных триггеров или входных регистров.
В МАХ -устройствах задержка прохождения сигнала с любого входа на любой выход не является постоянной. Она зависит от выбранной конфигурации макроячеек и, естественно, от пути, по которому входной сигнал достигает выхода. Эта особенность, с одной стороны, усложняет разработку устройств, так как требует выполнения временного тестирования и анализа. С другой же стороны, она позволяет повысить быстродействие реализованного устройства по сравнению с его реализацией на МАСН -устройствах путем выбора оптимального пути прохождения входных
 |
сигналов.
FLEX-устройства. Разработанные фирмой Atmel CPLD,
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 2460; Нарушение авторских прав?; Мы поможем в написании вашей работы!