КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Стандартные прикладные программные средства в решении задач медицинской информатики
|
|
|
|
На сегодняшний день для решения задач медицинской информатики специально разрабатываются программы, программно-технические комплексы. Это позволяет более эффективно и оптимально по затратам добиваться результата в информатизации лечебно-диагностических, организационных и иных процессов в здравоохранении. Однако еще большое количество медицинских учреждений не оснащены подобными программными продуктами. Поэтому применение стандартных прикладных программных средств для решения информационных задач сотрудниками всех уровней и подразделений медицинских учреждений остается востребованным и актуальным.
Одним из наиболее распространенным и применяемым стандартным программным пакетом является пакет офисных программ: текстовый процессор, электронные таблицы, система управления базой данных, графический редактор, редактор презентаций. Широко известны пакеты Microsoft Office, OpenOffice, LibreOffice.
| пакет | Microsoft Office | OpenOffice | LibreOffice |
| Текстовый процессор | Microsoft Office Word | OpenOffice Writer | LibreOffice Writer |
| Табличный процессор (электронные таблицы) | Microsoft Office Excel | OpenOffice Calc | LibreOffice Calc |
| Система управления базами данных | Microsoft Office Access | OpenOffice Base | LibreOffice Base |
1.1. Применение текстового редактора в медицинских задачах
Далеко не каждое отделение ЛПУ использует компьютерную систему хотя бы ограниченного электронного документооборота. В то же время применение стандартных программных средств, распространенных повсеместно, позволяет формировать отдельные медицинские документы в электронном виде и осуществлять статистическую обработку данных о состоянии здоровья пациентов.
Большое количество документов создается и редактируется с помощью текстовых редакторов и текстовых процессоров. Работа с текстами - важная составная часть деятельности людей многих профессий: писателей, юристов, ученых, руководителей, инженеров, в том числе и врачей. Обработка текстов, подготовка различного вида документов составляют значительную часть работ, выполняемых в настоящее время на персональных компьютерах.
В состав создаваемых документов могут входить текстовые данные, таблицы, математические формулы, графические объекты и т.д. Главная задача любого текстового редактора заключается в обеспечении оптимальных для пользователя условий по созданию и обработке документов.
Современный текстовый редактор представляет собой программный продукт, обеспечивающий пользователя компьютера средствами создания, обработки и хранения документов различной степени сложности. В последнее время текстовые редакторы вытесняются текстовыми процессорами, которые позволяют не только набирать "чистый", неформатированный текст, но и оформлять его: произвольно размещать на странице, выделять шрифтами, цветом и т.д. Однако без ущерба для понимания можно в равной степени использовать оба термина.
Текстовый редактор позволяет делать все то, что может делать машинистка с помощью хорошей пишущей машинки. Но кроме традиционных возможностей компьютера позволяет осуществлять качественно новые способы обработки текстовых документов: вставку повторяющихся фрагментов, изменение длины строк, автоматический перенос слов, выделение нужных частей текста нестандартным шрифтом при печати и другие.
Ошибка при подготовке документа на компьютере не влечет за собой больших переделок, так как автоматическое выполнение рутинных работ облегчает изменение и перемещение фрагментов текста. Возможность предварительного просмотра полученного документа на экране дисплея помогает избежать непроизводительных затрат труда и бумаги при печати.
Итак, текстовой процессор предназначен для выполнения всех процессов обработки текста: от набора и верстки, до проверки орфографии, вставки в текст графики в стандарте *.pcx или *.bmp, распечатки текста. Он работает с многими шрифтами, как с русским, так и с любым из двадцати одного языка мира. В одно из многих полезных свойств текстового процессора входит автоматическая коррекция текста по границам, автоматический перенос слов и правка правописания слов, сохранение текста в определенный устанавливаемый промежуток времени, наличие мастеров текстов и шаблонов, позволяющих в считанные минуты создать деловое письмо, факс, автобиографию, расписание, календарь и многое другое. Текстовый процессор обеспечивает поиск заданного слова или фрагмента текста, замену его на указанный фрагмент, удаление, копирование во внутренний буфер или замену по шрифту, гарнитуре или размеру шрифта, а так же по надстрочным или по подстрочным символам. Наличие закладки в тексте позволяет быстро перейти к заложенному месту в тексте. Можно так же автоматически включать в текст дату, время создания, обратный адрес и имя написавшего текст. При помощи макрокоманд текстового процессора позволяет включать в текст базы данных или объекты графики, музыкальные модули в формате *.wav. Для ограничения доступа к документу можно установить пароль на текст, который текстового процессора будет спрашивать при загрузке текста для выполнения с ним каких-либо действий. Текстовый процессор позволяет открывать много окон для одновременной работы с несколькими текстами, а так же разбить одно активное окно по горизонтали на два и выровнять их.
Текстовый процессор позволяет вводить, редактировать, форматировать и оформлять текст и грамотно размещать его на странице. С помощью этой программы можно вставлять в документ графику, таблицы и диаграммы, а также автоматически исправлять орфографические и грамматические ошибки.
Текстовый процессор обладает и многими другими возможностями, значительно облегчающими создание и редактирование документов. Наиболее часто используемые функции:
- набор текста;
- вырезание кусков текста, запоминание их в течении текущего сеанса работы, а также в виде отдельных файлов;
- вставка кусков в нужное место текста;
- замена слов одно на другое частично или полностью по всему тексту;
- нахождение в тексте нужных слов или предложений;
- форматирование текста, т.е. придание ему определенного вида по следующим параметрам:ширина текстовой колонки, абзац, поля с обеих сторон, верхнее и нижнее поле, расстояние между строками, выравнивание края строк;
- автоматическая разбивка текста на страницы с заданным числом строк;
- автоматическая нумерация страниц;
- автоматический ввод подзаголовков в нижней или верхней части страницы;
- выделение части текста жирным, наклонным или подчеркнутым шрифтом;
- переключение программы для работы с другим алфавитом;
- табуляция строк, т.е. создание постоянных интервалов для представления текста в виде колонок;
- при вводе текста вы упираетесь в конец строки, Word автоматически делает переход на следующую строку;
- если при вводе текста делается опечатка, функция автокоррекции автоматически ее исправляет. А функция автоматической проверки орфографии подчеркивает неправильно написанные слова красной волнистой линией, чтобы их было легче увидеть и исправить;
- если пользоваться дефисами для выделения пунктов списка, употреблять дроби, знак торговой марки или другие специальные символы, функция автоформатирования будет сама их корректировать;
- возможность вставки в текст формул, таблиц, рисунков;
- возможность создания нескольких текстовых колонок на одной страницы;
- выбор готовых стилей и шаблонов;
- для представления текста в виде таблицы можно, конечно, пользоваться и табулятором, однако Microsoft Word предлагает гораздо более эффективные средства. А если таблица содержит цифровые данные, то их легко превратить в диаграмму;
- режим предварительного просмотра позволяет увидеть документ в том виде, в каком он выйдет из печати. Кроме того, он дает возможность отобразить сразу все страницы, что удобно для внесения изменений перед распечаткой.
Программа предлагает также ряд функций, экономящих время и усилия. Среди них:
- автотекст – для хранения и вставки часто употребляемых слов, фраз или графики;
- стили – для хранения и задания сразу целых наборов форматов;
- слияние – для создания серийных писем, распечатки конвертов и этикеток;
- макросы – для выполнения последовательности часто используемых команд;
- “мастера” – для создания профессионально оформленных документов.
Среди применяемых в настоящее время текстовых процессоров одним из самых используемых является текстовый процессор MS Word — разработанная фирмой Microsoft программная система, входящая в комплекс Microsoft Office. Она относится к классу программ текстового редактирования, таких как «Блокнот», Word Pad и др. Отличием MS Word от других редакторов является его многофункциональность, насыщенность средствами автоматизации для форматирования текста, построения таблиц, введения в текст формул, графиков, рисунков, возможность работы с большими документами. В других пакетах используются аналогичные текстовые процессоры Writer OpenOffice и LibreOffice.
Существуют и специализированные текстовые редакторы, имеющие приложения в здравоохранении. Одним из них является текстовый редактор для ведения дневников в истории болезни SDAssistant.
SDAssistant - специализированный текстовый редактор - помощник доктора в ведении медицинской документации. Программа приспособлена для быстрого ввода большого количества повторяющейся информации, которая составляет львиную долю содержимого дневников. SDAssistant поддерживает гибкую систему шаблонов стандартных фраз. Шаблоны применяются в зависимости от контекста ввода, для каждого из разделов дневника можно использовать свой набор шаблонов для автозаполнения. SDAssistant поддерживает гибкую систему шаблонов стандартных фраз, причем поддерживается автоматическое переключение шаблонов в зависимости от контекста ввода.
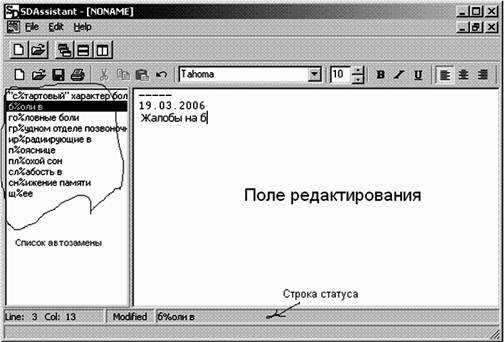
Рис. Вид документа в редакторе SDAssistant
При вводе текста редактор SDAssistant определяет первое слово в начале абзаца (заголовок раздела дневника), исходя из которого подключает набор стандартных фраз, предназначенных для данного раздела.
Алгоритм работы функции автозамены следующий: из списка стандартных фраз (находится в левой части редактора) выбирается фраза, в которой символы до знака "%" совпадают с введеными, данная фраза появляется в строке статуса, при нажатии клавиши "ПРОБЕЛ" эта фраза появляется в тексте.
В программе предусмотрена функция вставки содержимого предыдущего дневника или одного из его разделов, что еще больше ускоряет ввод. Вводимая информация может сохраняться в формате.RTF для последующего использования в других текстовых редакторах. Данная функция полезна также для создания базы данных осмотров пациентов.
· Набор разделов и фраз определяется в текстовом файле patterns.ini, который расположен в корневой папке программы. Формат файла следующий:
· название раздела дневника (первое слово) в квадратных скобках
· набор фраз для данного раздела. Каждая фраза начинается с новой строки. Внутри фразы ставится знак "%" для выделения ключевого набора букв для функции автозаполнения. В конце фразы ставится знак "=".
· первый раздел должен быть [Default], в этом разделе указываются стандартные фразы для пустого абзаца (абзац, начинающийся с символа пробела). Обычно в этом разделе указываются названия разделов дневника для быстрого ввода и возможные заглавия для дневника.
| [Default]Ос%мотр невролога=со%вмесно с заведующей поликлиники=Ж%алобы на=Жа%лоб не предъявляет.=А%намнез:=О%бъективно:=Д%иагноз:=Р%екомендовано:=С%правка:=З%аключение:=Б%ольничный лист №= | [Жалобы]го%ловные боли=сн%ижение памяти=б%оли в=п%ояснице=щ%ее=гр%удном отделе позвоночника=ир%радиирующие в=пл%охой сон=сл%абость в= |
5.2. Применение электронных таблиц при работе с медицинскими данными.
Для ведения учета, анализа и создания текстовых документов: отчетов, справок, накладных, листов учета, применяют табличные процессоры или иначе электронные таблицы.
Табличные процессоры (электронные таблицы) — удобное средство для проведения расчетов, построения диаграмм и анализа данных. Наиболее распространенные электронные таблицы имеют большие графические возможности и совместимы с текстовыми редакторами, что удобно при формировании документов.
Табличные процессора предназначены для работы с таблицами данных, преимущественно числовых. При формировании таблицы выполняют ввод, редактирование и форматирование текстовых и числовых данных, а также формул. Наличие средств автоматизации облегчает эти операции. Созданная таблица может быть выведена на печать.
Электронная таблица, так же, как и обычная таблица, представляет собой набор числовых и текстовых данных размещенных в ячейках. Данные, находящиеся в ячейке электронной таблицы, могут быть введены пользователем, либо определены (вычислены) по данным других ячеек. На основе содержимого электронных таблиц могут создаваться диаграммы, графики, служащие иллюстрацией числовой информации.
Вычисления в таблицах табличных процессоров осуществляются при помощи формул. Формула может содержать числовые константы, ссылки на ячейки и встроенные функции, соединенные знаками математических операций. Скобки позволяют изменять стандартный порядок выполнения действий. Если ячейка содержит формулу, то в рабочем листе отображается текущий результат вычисления этой формулы. Если сделать ячейку текущей, то сама формула отображается в строке формул.
Так как таблицы часто содержат повторяющиеся или однотипные данные, табличные процессоры содержат средства автоматизации ввода. К числу предоставляемых средств относятся: автозавершение, автозаполнение числами и автозаполнение формулами.
Для упрощения работы с формулами в электронных таблицах есть заранее заготовленные функции (около 200). Вставить функции в формулу можно с помощью меню.
Построение диаграмм осуществляется с помощью встроенного мастера диаграмм на основе ряда данных.
Итак, с помощью электронных таблиц табличных процессоров можно создавать различные документы, выполнять множество задач, связанных с данными в этих документах:
· Составлять всевозможные списки, отчеты, ведомости, бланки;
· Оперативно выполнять вычисления различного уровня сложности;
· По данным из таблиц строить динамически связанные с ними диаграммы, графики;
· Решать сложные финансовые, экономические и математические задачи;
· Статистически обрабатывать приведенные в таблице данные с использованием, в том числе, и методик факторного анализа.
Среди применяемых в настоящее время табличных процессоров одним из самых используемых является табличный процессор MS Excel — разработанная фирмой Microsoft программная система, входящая в комплекс Microsoft Office. В других пакетах используются аналогичные текстовые процессоры Calc OpenOffice и LibreOffice.
Для статистической обработки медицинских данных применяют и специализированные программные продукты, такие например как пакет Statistica.
Statistica - современный пакет статистического анализа, в котором реализованы все новейшие компьютерные и математические методы анализа данных.
Statistica - это универсальная интегрированная система, предназначенная для статистического анализа и визуализации данных, управления базами данных и разработки пользовательских приложений, содержащая широкий набор процедур анализа для применения в научных исследованиях, технике, бизнесе, а также специальные методы получения данных.
Помимо общих статистических и графических средств, в системе имеются специализированные модули, например, для проведения социологических или биомедицинских исследований, решения технических и, что очень важно, промышленных задач: карты контроля качества, анализ процессов и планирование эксперимента. Работа со всеми модулями происходит в рамках единого программного пакета, для которого можно выбирать один из нескольких предложенных интерфейсов пользователя.
С помощью реализованных в системе Statistica мощных языков программирования, снабженных специальными средствами поддержки, легко создаются законченные пользовательские решения и встраиваются в различные другие приложения или вычислительные среды. Очень трудно представить себе, что кому-то могут понадобиться абсолютно все статистические процедуры и методы визуализации, имеющиеся в системе Statistica. Однако опыт многих людей, успешно работающих с пакетом, свидетельствует о том, что возможность доступа к новым, нетрадиционным методам анализа данных (а Statistica предоставляет такие возможности в полной мере) помогает находить новые способы проверки рабочих гипотез и исследования данных
Система Statistica обладает широкими графическими возможностями. Statistica включает в себя большое количество разнообразных категорий и типов графиков (включая научные, деловые, трехмерные и двухмерные графики в различных системах координат, специализированные статистические графики — гистограммы, матричные, категорированные графики и др.).
В систему Statistica включено большое количество инструментов настройки всех компонент графиков. Имеется возможность выбора различных типов линий, форматов разметки осей, цветов, легенд, названий и других атрибутов графика. Настроенные атрибуты могут быть сохранены в специальном файле и потом применяться к другим графикам. Доступ ко всем основным командам настройки реализован при помощи контекстных меню, которые появляются при нажатии на правую кнопку мыши, общего меню и из панели инструментов графика.
Рис. Электронная таблица с данными
Медицинский работник, и в первую очередь врач, должен понимать, какие математические вычисления и почему используются в том или другом методе, осознанно выбирать методы обработки данных, адекватно оценивать, какие результаты и почему он получил, грамотно их интерпретировать. Поэтому особое место в применении электронных таблиц заключается в возможности статистического анализа данных. Выбор метода осуществляется с помощью меню. Среди инструментов анализа описательная статистика, однофакторный дисперсионный анализ, двухфакторный дисперсионный анализ с повторениями, двухфакторный дисперсионный анализ без повторений, корреляция, ковариация, экспоненциальное сглаживание, двухвыборочный F-тест для дисперсии, анализ Фурье и др.
5.3. Применение систем управления базами данных (СУБД)
Основой многих медицинских информационных систем (МИС) являются базы данных (БД).
База данных, БД (Data Base) - структурированный организованный набор данных, объединенных в соответствии с некоторой выбранной моделью и описывающих характеристики какой-либо физической или виртуальной системы.
Или
База данных — это организованная совокупность данных, предназначенная для длительного хранения во внешней памяти ЭВМ, постоянного обновления и использования. Также БД можно определить как объективную форму представления и организации совокупности данных, систематизированных таким образом, чтобы эти данные могли быть найдены и обработаны с помощью стандартных или специальных программ.
Обычно БД можно рассматривать как информационную модель реальной системы.
Классификация БД.
Базы данных классифицируют на основе разных признаков. Одним из системообразующих признаков может быть характер хранимой информации. По нему БД подразделяют на фактографические и документальные. Фактографические содержат в себе данные в строго фиксированных форматах и краткой форме, являясь электронным аналогом каталогов. Документальные БД похожи на архив документов.
Другим системообразующим признаком является способ хранения информации. По нему БД подразделяются на централизованные и распределенные. В централизованной БД вся информация хранится на одном компьютере. Это может быть отдельный компьютер, но чаще — сервер, к которому подключены клиенты-пользователи. Распределенные БД функционируют в локальных и глобальных сетях. В этих случаях фрагменты БД могут храниться на разных компьютерах или серверах.
Локальная сеть объединяет компьютеры одного подразделения или учреждения, расположенного в одном здании.
Региональные и глобальные сети — это интегрированные локальные сети определенной территории, обеспечивающие функционирование ИС определенной направленности (территориальное здравоохранение, онкологическая служба и т.д.).
Еще одним системообразующим признаком классификации БД является структура хранимых данных. По нему БД подразделяют на иерархические, сетевые и реляционные (табличные).
Иерархические БД в графическом изображении часто сравнивают с деревом, перевернутым кроной вниз. На верхнем уровне находится один объект, на втором — несколько (объекты второго уровня), на третьем — еще больше (объекты третьего уровня) п т.д. Между объектами есть связи. Объект, находящийся выше по иерархии («предок»), может быть связан с несколькими объектами более низкого уровня («потомками»), а может и не иметь их. Объект ниже по иерархии может иметь только одного «предка».Объекты, имеющие общего «предка», называются «близнецами».
Самым распространенным и всем известным примером иерархической БД является Каталог папок Windows. Верхний уровень (Рабочий стол) — «предок», второй уровень (Мои документы, Мой компьютер, Сетевое окружение, Корзина и т.д.) — «потомки».
Сетевые БД являются обобщением иерархических за счет допущения объектов, имеющих более одного «предка». В сетевых моделях на связи между объектами никаких ограничений не накладывается.
Наглядным примером сетевой БД является компьютерная сеть Интернет, в которой с помощью гиперссылок многие миллионы документов связаны между собой в распределенную БД. Не зря Интернет очень точно часто называют Всемирной паутиной.
Реляционные БД (от англ. relation — отношение) в настоящее время наиболее распространены. В них используется табличная модель данных. Такая БД может состоять из одной таблицы, а может — из множества взаимосвязанных таблиц.
Структурными составляющими таблицы являются записи и поля. Запись БД — это строка таблицы, содержащая информацию об отдельном объекте системы, например об одном пациенте. Поле БД — это столбец таблицы, содержащий характеристику (свойство, атрибут) объекта, например пол пациента, его возраст и т.д. Каждая таблица должна содержать хотя бы одно поле или несколько полей, содержимое которого уникально для каждой записи в данной таблице (ключ). Иначе говоря, ключ однозначно идентифицирует запись в таблице. В большинстве реально функционирующих медицинских реляционных БД используется составной ключ, например фамилия пациента, год рождения, номер истории болезни. Каждое поле таблицы имеет определенный тип, который определяется типом данных, которые в нем содержатся. Поле каждого типа имеет набор свойств. Наиболее важными из них являются размер поля — длина, формат поля — формат данных, которые в нем содержатся, обязательное поле — указание на то, что данное поле должно заполняться обязательно.
Базы данных медицинской информации служат для сбора, накопления, хранения и использования медицинских данных. К таким данным можно отнести электронные медицинские карты стационарных и амбулаторных больных, архивы исследований, электронные системы учета лекарственных препаратов и т.д.. Базы данных позволяют не только оптимально хранить соответствующие данные и визуализировать их, но и содержат средства сортировки, фильтрации и преобразование данных с созданием отчетных документов. Кроме того, база данных допускает расширение и редактирование хранящихся данных в зависимости от потребностей пользователя и позволяют организовывать защиту данных от утраты и несанкционированного доступа. Благодаря этим свойствам базы данных могут служить эффективным инструментом информатизации и автоматизации работы врача.
Системы управления базами данных. Система управления базами данных (СУБД) — это программное обеспечение, предназначенное для работы с БД: их определения, создания, поддержки, осуществления контролируемого доступа.
С помощью СУБД пользователь может:
1) разрабатывать структуру БД;
2) заполнять БД;
3) редактировать структуру и содержание БД;
4) искать информацию по БД;
5) осуществлять защиту и проверку целостности БД в ограниченном размере.
Системы управления базами данных могут быть ориентированы на применение как программистами, так и специалистами в конкретной предметной области. Они предоставляют специальные инструментальные средства для разработки БД.
Среди распространенных в России сложных СУБД, ориентированных на специалистов, следует назвать Oracle и Microsoft SQL и одна из наиболее распространенных, которой является MS Access. Часто используют СУБД HSQLDB, аналог Access, из офисных пакетов OpenOffice и LibreOffice
Построение базы данных. Построение БД включает в себя два основных элемента: проектирование и создание.
Проектирование БД в свою очередь включает анализ предметной области, анализ данных и построение реляционной модели данных.
Анализ предметной области основывается на информационной модели исследуемого объекта, например ЛПУ. Первый шаг системного анализа любого процесса — это его разделение на последовательные этапы. На каждом этапе выделяют и описывают происходящие на объекте информационные процессы.
Анализ данных подразумевает выделение информации, используемой на каждом этапе процесса, и планирование таблиц (в реляционной БД).
Создание реляционной модели данных заключается в описании всех используемых в ней таблиц (отношений) и построении схемы БД — системы связей между таблицами. Связи между таблицами осуществляются через одноименные поля: «один к одному» — одна запись в одной таблице связана с одной записью другой таблицы на одном уровне иерархии; «один ко многим» — одна запись в одной таблице связана с множеством записей в другой таблице (между соседними уровнями иерархической структуры). Организация связей между таблицами обеспечивает одно из важнейших качеств БД, называемое целостностью: СУБД не допустит, чтобы поля с одинаковыми именами в разных, связанных между собой, таблицах имели бы разные значения. Другими словами, СУБД осуществляет автоматический контроль за согласованностью взаимосвязанных данных разных таблиц. На этом проектирование БД завершается.
Итак, создание БД состоит из разработки структуры БД и заполнения ее данными.
Выбор конкретной СУБД представляет собой сложную многопараметрическую задачу и является одним из важнейших этапов в разработке ИС. Программный продукт должен удовлетворять как текущим, так и будущим потребностям заказчика, при этом следует учитывать финансовые затраты на приобретение необходимого оборудования, самой системы, разработку необходимого программного обеспечения на ее основе, а также обучение персонала. Очевидно, наиболее простой подход при выборе СУБД основан на оценке того, в какой мере существующие системы удовлетворяют основным требованиям создаваемого проекта ИС. Более сложным и дорогостоящим вариантом является создание испытательного проекта на основе нескольких СУБД и последующий выбор наиболее подходящего из кандидатов. Но и в этом случае необходимо ограничивать круг возможных систем, опираясь на некие критерии отбора. Однако подобный подход является весьма дорогостоящим мероприятием, при этом весьма подверженным субъективности и предвзятости. Более того, результаты одного и того же эксперимента могут быть интерпретированы как в пользу одной СУБД, так и в пользу другой, в зависимости от расставленных приоритетов выбора СУБД или особенностей конкретного разработчика.
В противовес экспериментальному подходу в выборе СУБД эмпирический анализ хоть и не дает конкретных рекомендаций и, строго говоря, не предназначен для выявления наиболее удачной или наоборот, наихудшей для комплексной медицинской информационной системы СУБД, зато позволяет вести этот выбор на основе достаточно объективных показателях, сложившихся многолетней практикой и наблюдениями рынка. Все вышесказанное побудило провести такое эмпирическое исследование с целью выявить тенденции и объективные показатели использования СУБД в современных медицинских информационных системах.
Подавляющее большинство современных комплексных медицинских информационных систем основано на архитектуре "Клиент-сервер". Практическим опытом доказана неизбежность такого решения для создания комплексной информационной системы, так как настольные базы данных, в том числе с использованием файл-сервера, способны поддерживать только до 10 рабочих станций и небольшой объем базы данных. Кроме того, значительная часть существующих требований к медицинским информационным системам уже реализована в промышленных СУБД, построенных в архитектуре “клиент — сервер”, что позволяет существенно сократить время на создание системы.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 9751; Нарушение авторских прав?; Мы поможем в написании вашей работы!